
Teams buy HDL simulation for best bang for the buck. Teams buy hardware emulation for the speed. We’ve talked previously about SCE-MI transactors as a standardized vehicle to connect the two approaches to get the benefits of both in an accelerated testbench – what else should be accounted for?
Jim Kenney of Mentor Graphics has written a new white paper thinking through some of the details after a SCE-MI approach is selected. We all know that clock for clock, hardware emulation is much faster than host-based simulation, even considering a high-performance distributed simulation farm. At first glance, the idea would be to shift as much as possible into the hardware emulator and minimize the interaction with the simulator via SCE-MI transactions.
In practice, shifting testbench workload into the hardware emulator is important, but there are also important choices into what is kept in the simulator. Simply put, bus cycle state machines convert behavioral events from the simulation and convert data into a multiple-clock pattern at emulation speed. Not all cycles are created equal, however: AMBA transactions typically generate 10 emulation clocks in hardware for each testbench event, while Ethernet transactions are one or two orders of magnitude higher.
The idea is efficiency, where the simulator is not waiting around for event responses and isn’t overwhelmed by how much high-level data it has to generate for the SCE-MI transactors on each event. If the simulator still falls behind, much of the benefit of hardware emulation is undone. Keeping data exchanges limited yet robust while running high-frequency pin activity at emulator clock rates can increase overall performance.

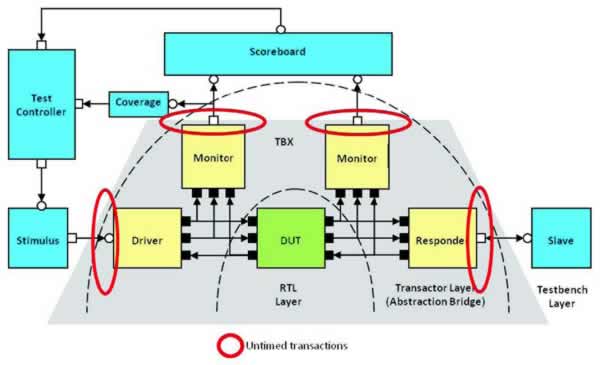
Mentor has built in some prudent testbench choices in TestBench Xpress (TBX) co-modeling software. Lower-level synthesizable components such as drivers, monitors, and more are synthesized into the emulator hardware. Higher, transaction-level components such as generators, scoreboards, coverage collectors, and others stay inside the simulator.
The trick in co-modeling is to create a single code base that can run either on a simulation platform without emulation, or with the hardware emulator acceleration and the run-time speedup. That means partitioning the testbench into a synthesizable HDL implementation and a high-level verification (HVL) side encompassing the workstation, transactors, and emulator.
That, in turn, suggests a separation between timed and untimed constructs. Quoting Kenney from the white paper:
A co-emulation flow enforces this separation and requires that the transactor layer components are included on the HDL side to run alongside the DUT on the Veloce emulator. It further requires that the HDL and HVL sides are completely separated hierarchies with no cross module or signal references, and with the code on the HVL side strictly untimed. This means that the HVL side cannot include any explicit time advance statements like clock synchronizations, # delays and wait statements, which may occur only on the HDL side. Abstract event synchronizations and waits for abstract events are permitted on the untimed HVL side, and it is still time-aware in the sense that the current time as communicated with every context switch from HDL to HVL side can be read.
Kenney’s complete white paper is available for download (registration required):
Testbench Considerations for Maximizing Speed of Simulation Acceleration with a Hardware Emulator
It’s an interesting discussion because the nuances of partitioning, even with a hardware emulator that just eats synthesized stuff, can handcuff or even completely stall a co-modeled environment. The downside of having to go create two code bases, one for pure simulation and one for an accelerated testbench with emulation, is obviously something to avoid. I can see users needing some application-engineering insight before plowing from a simulation strategy into the emulation platform hoping for 100x speedups, and the hints in this paper are valuable.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.