You are currently viewing SemiWiki as a guest which gives you limited access to the site. To view blog comments and experience other SemiWiki features you must be a registered member. Registration is fast, simple, and absolutely free so please,
join our community today!
WP_Term Object
(
[term_id] => 36
[name] => eFPGA
[slug] => efpga
[term_group] => 0
[term_taxonomy_id] => 36
[taxonomy] => category
[description] =>
[parent] => 0
[count] => 139
[filter] => raw
[cat_ID] => 36
[category_count] => 139
[category_description] =>
[cat_name] => eFPGA
[category_nicename] => efpga
[category_parent] => 0
[is_post] =>
)
As semiconductor technology advances into increasingly complex and expensive process nodes, the economic and technical risks associated with ASIC design have grown dramatically. At advanced nodes such as Intel 18A, the cost of a single design error can escalate into tens of millions of dollars, compounded by months of delay.… Read More
The semiconductor industry’s transition toward chiplet-based architectures is entering a decisive new phase. What began as a promising alternative to SoC design is now confronting real-world demands around system integration, validation, and long-term scalability. At Chiplet Summit 2026, taking place February 17–19 … Read More
When designing IP for system-on-chip (SoC) and application-specific integrated circuit (ASIC) implementations, IP designers strive for perfection. Optimal engineering often yields the smallest die area, thereby reducing both cost and power consumption while maximizing performance.
Similarly, when incorporating embedded… Read More
The rapid technological evolution and soaring mask set costs have created numerous challenges for designers today. Protocols, algorithms, and cryptography are all advancing at a blistering pace, leaving designers struggling to keep up. While fab suppliers are enhancing performance and reducing power consumption, this … Read More
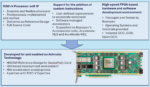
Recently, a partnership between Achronix and Bluespec has been in the news. Bluespec RISC-V processors are available as soft cores in a Speedster®7t FPGA on Achronix’s VectorPath® PCIe development card or in a standalone Speedster7t FPGA. We spoke with executives from Achronix and Bluespec about the impetus for this effort … Read More
Field-Programmable Gate Arrays (FPGAs) have long been celebrated for their unmatched flexibility and programmability compared to Application-Specific Integrated Circuits (ASICs). And the introduction of Embedded FPGAs (eFPGAs) took these advantages to new heights. eFPGAs offer on-the-fly reconfiguration capabilities,… Read More
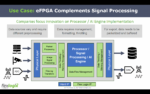
The performance demands of data centers continue to grow, driven to large degree by the ubiquitous use of complex AI algorithms. On April 25, Embedded Computing Design held an informative webinar on this topic. Two experts looked at the problem from the standpoint of processor architecture and communication strategies, which… Read More
The server and enterprise network boundary has seen complexity explode in recent years. What used to be a simple TCP/IP offload task for network interface cards (NICs) is transforming into full-blown network acceleration using a data processing unit (DPU), able to make decisions based on traffic routes, message content, and… Read More
Today we live in a world where technology is a part of our everyday lives, not only our personal data, but all devices we rely on on a daily basis including our automobiles, cell phones, and home devices. Hackers have found creative and novel ways to corrupt these products, disable systems, steal secrets and threaten our identities.… Read More
The three-step conversational AI (CAI) process – automatic speech recognition (ASR), natural language processing, and text-to-synthesized speech response – is now deeply embedded in the user experience for smartphones, smart speakers, and other devices. More powerful large language models (LLMs) can answer more queries… Read More







Enhancing Multi-Domain System Simulation with FMI Co-Simulation