
I was scheduled to attend the Mentor tutorial at DVCon this year. Then coronavirus hit, two big sponsors dropped out and the schedule was shortened to three days. Mentor’s tutorial had to be moved to Wednesday and, as luck would have it, I already had commitments on that day. Mentor kindly sent me the slides and audio from the meeting and I’m glad they did because the content proved to be much richer than I had expected.
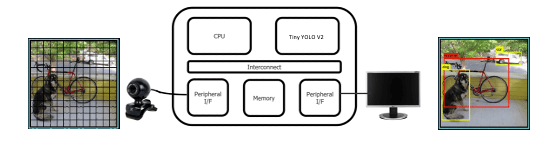
Lauro Rizzatti and Steve Bailey provided an intro and confirmed my suspicion that this class of solutions is targeted particularly at hardware accelerators. Could be ML, video, audio, wireless algorithms, any application-specific thing you need to speed up and/or reduce power in an edge device. Maybe a surveillance product, which had been getting by with a low-res image and ML software running on a CPU, now you must move to 4K resolution with faster recognition at the same power. You need a hardware accelerator. For this tutorial they use TinyYOLO for object recognition as their demo platform.
Russ Klein came next with a nod to algorithm design (in TensorFlow using Python) then algorithm partitioning and optimization. Sounds like a big yawn, right? Some basic partitioning, changing bus widths and fixed-point sizes, tweaking here tweaking there?
Wrong – very wrong.
This may be the best tutorial I have seen on the topic, from explanations of the mechanics behind convolution to how that maps into implementation. Not just for toy implementations, but through stepwise improvements all the way up to arrays of processing elements, close to the state of the art.
The process starts with a TinyYOLO algorithm running in TensorFlow executing on a laptop. This reads camera frames within a video feed, a scene of some kind, and aims to recognize certain objects – a dog, a bike, a car – and output the same scene feed with labeled bounding boxes around those objects. He noted that a single inference requires 5.2B floating point operations. It’s not practical to do this in software for real time recognition response.
They ran profiling on the software and of course all those multiply-accumulate (MAC) operations stuck up like a sore thumb, so that’s what they want to drop into hardware. Since this is a pitch for high-level synthesis (HLS), they want to convert that part of the algorithm to C++ for later synthesis to RTL.
But not all at once.
Russ and following speakers emphasized the importance of converting and verifying in steps. They break their neural net up into 9 stages and replace each stage, one at a time in the Python flow with a C++ implementation, verifying as they go. Once those all match, they replace all those stages and verify again. Now they can experiment with architecture.
Each stage come down to a bunch of nested loops; this is obviously where you can play with parallelism. As a simple example, an operation that in software might take 32 cycles can be squished into 1 cycle if the target technology makes that feasible.
Next is a common question for these 2D convolutions – what are you going to optimize for in on-chip memory? These images (with color depth) are huge, and they’re going to be processed through lots of planes, so you can’t do everything in local memory. Do you optimize to keep feature maps constant, or output channels constant, or use a tile approach where each can be constant over a tile but must change between tiles? Each architecture has pros and cons. Experimenting with different options in the C++ code, to first order, is just a matter of reordering nested loops.
However which option really works best relates in performance and power directly to on-chip memory architectures. Russ talked about several options and settled on shift registers, which can nicely support a sliding 3×3 convolution window and allow multiplies within that window to run in parallel.
Ultimately this led them to a processing element (PE) architecture, each element containing shift registers, a multiply and an adder. They can array these PEs to get further parallelism and were able to show they could process ~700B operations per second running at 600MHz. Since 5.2B operations are required per inference, that’s ~7ms per inference by my math.
There was also an interesting discussion, from John Stickley, on the verification framework. Remember that the goal is to always be able to reverify within the context of the original TensorFlow setup – replace a stage in the Python flow with a C++ equivalent or a synthesized RTL equivalent and reverify that they are indeed equivalent.
They run the TensorFlow system inside a Docker container with an appropriate version of the Ubuntu OS and TensorFlow framework, which they found greatly simplifies installation of the AI framework and the TinyYOLO (from Github), along with whatever C++ they were swapping in. This also made the full setup more easily portable. C++ blocks can then become transactors to an emulation or an FPGA prototype.
There’s a huge amount of detail I’m skipping in this short summary. You can get some sense or the architecture design from this link, though I hope Russ also write up his presentation as a white-paper.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.