
One of the great advantages of emulation is that runtimes are much faster than for simulation – sufficiently fast  that you can really debug hardware together with software for comprehensive use-case testing. A not so great aspect is that emulators are expensive and, until relatively recently, not particularly easy to share across concurrent projects. That tended to focus emulation use only on the biggest, baddest, highest-revenue project you had in the shop at any given time. Which wasn’t great for optimizing return on that sizeable investment (the emulator sits idle during test development and debug, before verification starts and after tapeout), or for justifying capacity increases for the next even bigger project.
that you can really debug hardware together with software for comprehensive use-case testing. A not so great aspect is that emulators are expensive and, until relatively recently, not particularly easy to share across concurrent projects. That tended to focus emulation use only on the biggest, baddest, highest-revenue project you had in the shop at any given time. Which wasn’t great for optimizing return on that sizeable investment (the emulator sits idle during test development and debug, before verification starts and after tapeout), or for justifying capacity increases for the next even bigger project.
In fairness, vendors have offered forms of multi-user support for many years, but not really what we have come to expect for general-purpose systems where we don’t really care who else is using the system, or how many people are using it or what kinds of jobs they are running. We expect the OS to manage loads and maximize utilization while providing a fair balance in prioritization. Of course emulators aren’t general-purpose computers, so advancing the technology to provide this level of support wasn’t trivial. But true support for multi-user concurrent job support on emulators is now available with sufficient capability that you can now think of emulation as a multi-tasking datacenter resource, right alongside the servers you use for more conventional software tasks.
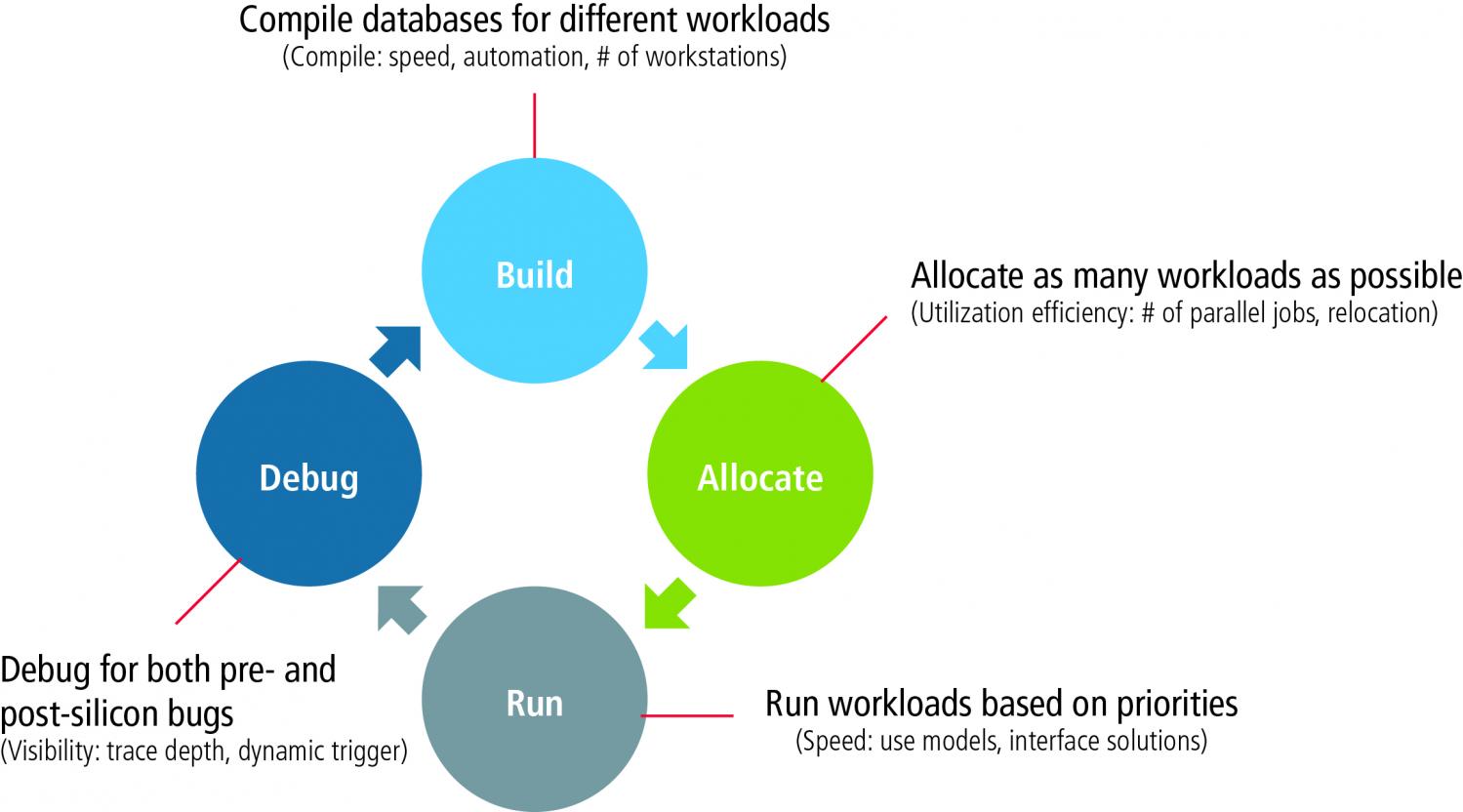
But it still requires a bit more thought to effectively load datacenter emulation than it takes for those servers. Frank Schirrmeister (Mr. Emulation, among other things, at Cadence) has written a white-paper on what you need to think about to optimize workload mixes in a virtualized emulation environment. Frank breaks it down into four pieces: Build, Allocate, Run and Debug.
The tradeoff between build-time and run-time is a good test of how a given emulation solution will fit with your job mix. Some platforms emulate quickly but build takes a long time. These systems would work well in mixes where runs dominate compiles – where each design is setup once for many long regression tests before cycling to the next round of design fixes. That profile would not work as well in mixes where you have a more heterogeneous range of objectives and where you might cycle more frequently to design fixes.
When you want to emulate 😎 general-purpose load-sharing as closely as possible, allocation is an important consideration. Jobs don’t come in fixed sized at fixed times, they end at different times and they may have different priorities. A big part of effective utilization is managing these varying parameters effectively, for maximum utilization and maximum throughput. Doing that requires an OS which can manage queuing, prioritization, task swapping and all the other features you take for granted in a multi-tasking OS.
There’s another factor too – one you probably don’t even think about – the granularity of emulation resources. Emulation task sizes can’t drop to the low levels possible in a general-purpose system – these are specialized resources after all. But the smaller the minimum size that can be supported, the more completely you can pack the space on average, so the more jobs you can service (for a distributed set of tasks) per unit time. It’s a basic tiling problem – if you have a mix of job sizes, a finer granularity gives you better utilization.
Another consideration is how effectively you can debug. Debug in the emulation world is necessarily in batch – you couldn’t afford to have an emulator occupied but idling while you’re scratching your head over a bug. So you have to decide before you start a run what signals you want to probe and over what time windows. This being hardware, there will be some constraints on these factors, and a poorly-chosen debug list may mean you have to rerun after you figure out what signals you missed, possibly more than once if a bug is far-removed from the root-cause. Also important to consider is whether updating the debug list also requires a recompile, which will further increase turnaround time on a rerun. Yet another factor is whether increasing the size of debug lists may slow emulation. These factors together require a careful balance and planning of debug strategy to ensure overall effectiveness of emulation in your shop. In general, support for big debug lists and trace windows will reduce the need for overthinking emulation runs.
Finally, give a thought to how ROI can be further improved by strong interoperability between verification methods. These often require transitions between simulation, emulation and prototyping. For instance, there is growing interest in using emulation as a way to accelerate or more accurately model components in a simulation. Here the emulator, operating in slave mode to a master simulation, models a device in an ICE environment or in a virtual equivalent. Similarly, easy transitions between FPGA prototyping and emulation, and between emulation and simulation help you get the best out of both platforms by letting the verification team get quickly to a starting point where they can then switch to a platform which allows for more detailed debug. Again this interoperability is especially important when the fix cycle is relatively short so restarting from a checkpoint won’t often help.
To read Frank’s more detailed analysis, click HERE.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.