Threads
XF\Mvc\Entity\ArrayCollection Object
(
[entities:protected] => Array
(
[22015] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 51
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22015
[node_id] => 2
[title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[reply_count] => 2
[view_count] => 217
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1738635052
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81179
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1738711158
[last_post_id] => 81229
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 12873
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1738710309
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 133
[alerts_unread] => 133
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 5555
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[21735] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 55
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 21735
[node_id] => 2
[title] => Intel Arc B580
[reply_count] => 56
[view_count] => 7176
[user_id] => 36640
[username] => soAsian
[post_date] => 1734985644
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 79177
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1738708029
[last_post_id] => 81228
[last_post_user_id] => 332041
[last_post_username] => XYang2023
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 52
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 36640
[username] => soAsian
[username_date] => 0
[username_date_visible] => 0
[email] => jackmtsai@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Chicago
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 251
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1608139716
[last_activity] => 1738685073
[last_summary_email_date] => 1719670845
[trophy_points] => 43
[alerts_unviewed] => 2
[alerts_unread] => 2
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 173
[warning_points] => 0
[is_staff] => 0
[secret_key] => 2oKeCTFkGUpMro5tcmj7WaY9HksB13Kw
[privacy_policy_accepted] => 1608139716
[terms_accepted] => 1608139716
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22013] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 59
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22013
[node_id] => 2
[title] => Bill Gates reminder on Intel struggles: One can get 'annihilated' if you miss a turn in the market
[reply_count] => 12
[view_count] => 795
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1738620414
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81157
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1738704098
[last_post_id] => 81226
[last_post_user_id] => 14042
[last_post_username] => hist78
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 12873
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1738710309
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 133
[alerts_unread] => 133
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 5555
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22014] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 63
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22014
[node_id] => 2
[title] => Samsung beats Intel to reclaim #1 position in semiconductor industry
[reply_count] => 7
[view_count] => 887
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1738624492
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81166
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738703834
[last_post_id] => 81225
[last_post_user_id] => 14042
[last_post_username] => hist78
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 12873
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1738710309
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 133
[alerts_unread] => 133
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 5555
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[21983] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 67
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 21983
[node_id] => 2
[title] => Intel Reports Fourth-Quarter and Full-Year 2024 Financial Results
[reply_count] => 97
[view_count] => 6843
[user_id] => 332041
[username] => XYang2023
[post_date] => 1738272712
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 80959
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738702598
[last_post_id] => 81223
[last_post_user_id] => 333049
[last_post_username] => BruceA
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 64
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 332041
[username] => XYang2023
[username_date] => 0
[username_date_visible] => 0
[email] => xiao.yang17@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => Australia/Sydney
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 656
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1708819075
[last_activity] => 1738708398
[last_summary_email_date] => 1723213219
[trophy_points] => 63
[alerts_unviewed] => 0
[alerts_unread] => 3
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 451
[warning_points] => 0
[is_staff] => 0
[secret_key] => NBs1n4BMtljiqSmfC-EZI_MMUn9Rzevl
[privacy_policy_accepted] => 1708819075
[terms_accepted] => 1708819075
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22021] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 71
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22021
[node_id] => 2
[title] => Australia to ban controversial Chinese AI company DeepSeek from all government systems
[reply_count] => 3
[view_count] => 172
[user_id] => 332041
[username] => XYang2023
[post_date] => 1738680872
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81214
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738690124
[last_post_id] => 81219
[last_post_user_id] => 20231
[last_post_username] => Barnsley
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 64
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 332041
[username] => XYang2023
[username_date] => 0
[username_date_visible] => 0
[email] => xiao.yang17@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => Australia/Sydney
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 656
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1708819075
[last_activity] => 1738708398
[last_summary_email_date] => 1723213219
[trophy_points] => 63
[alerts_unviewed] => 0
[alerts_unread] => 3
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 451
[warning_points] => 0
[is_staff] => 0
[secret_key] => NBs1n4BMtljiqSmfC-EZI_MMUn9Rzevl
[privacy_policy_accepted] => 1708819075
[terms_accepted] => 1708819075
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22020] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 75
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22020
[node_id] => 2
[title] => Deep Seek to be Criminalized Up to twenty years
[reply_count] => 0
[view_count] => 164
[user_id] => 10499
[username] => Arthur Hanson
[post_date] => 1738680389
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81213
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738680389
[last_post_id] => 81213
[last_post_user_id] => 10499
[last_post_username] => Arthur Hanson
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 72
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 10499
[username] => Arthur Hanson
[username_date] => 0
[username_date_visible] => 0
[email] => a-j-hanson@att.net
[custom_title] =>
[language_id] => 1
[style_id] => 1
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 3158
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1366028460
[last_activity] => 1738701174
[last_summary_email_date] => 1606051785
[trophy_points] => 83
[alerts_unviewed] => 5
[alerts_unread] => 5
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 389
[warning_points] => 0
[is_staff] => 0
[secret_key] => ta_8_Pj20m6PDO6RnrGK-VnSP_vyhP_m
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22019] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 79
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22019
[node_id] => 2
[title] => Will new AI/ML models come out to compete with Nvidia and Deep Seek?
[reply_count] => 2
[view_count] => 128
[user_id] => 10499
[username] => Arthur Hanson
[post_date] => 1738674107
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81207
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738677689
[last_post_id] => 81212
[last_post_user_id] => 332041
[last_post_username] => XYang2023
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 72
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 10499
[username] => Arthur Hanson
[username_date] => 0
[username_date_visible] => 0
[email] => a-j-hanson@att.net
[custom_title] =>
[language_id] => 1
[style_id] => 1
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 3158
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1366028460
[last_activity] => 1738701174
[last_summary_email_date] => 1606051785
[trophy_points] => 83
[alerts_unviewed] => 5
[alerts_unread] => 5
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 389
[warning_points] => 0
[is_staff] => 0
[secret_key] => ta_8_Pj20m6PDO6RnrGK-VnSP_vyhP_m
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22018] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 83
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22018
[node_id] => 2
[title] => NXP Semiconductors Reports Fourth Quarter and Full-Year 2024 Results
[reply_count] => 1
[view_count] => 189
[user_id] => 20231
[username] => Barnsley
[post_date] => 1738664075
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81203
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738664110
[last_post_id] => 81204
[last_post_user_id] => 20231
[last_post_username] => Barnsley
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 80
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 20231
[username] => Barnsley
[username_date] => 0
[username_date_visible] => 0
[email] => apickering72@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => Asia/Irkutsk
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 813
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1429440429
[last_activity] => 1738690129
[last_summary_email_date] => 1653315673
[trophy_points] => 63
[alerts_unviewed] => 29
[alerts_unread] => 29
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 339
[warning_points] => 0
[is_staff] => 0
[secret_key] => iAnkz9GTDfivRmH1BOp6OTrgESJR57G8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22017] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 87
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22017
[node_id] => 2
[title] => The 10% Tariff on Chinese Goods into US.
[reply_count] => 0
[view_count] => 159
[user_id] => 20231
[username] => Barnsley
[post_date] => 1738650403
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81197
[first_post_reaction_score] => 2
[first_post_reactions] => {"1":1,"3":1}
[last_post_date] => 1738650403
[last_post_id] => 81197
[last_post_user_id] => 20231
[last_post_username] => Barnsley
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 80
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 20231
[username] => Barnsley
[username_date] => 0
[username_date_visible] => 0
[email] => apickering72@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => Asia/Irkutsk
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 813
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1429440429
[last_activity] => 1738690129
[last_summary_email_date] => 1653315673
[trophy_points] => 63
[alerts_unviewed] => 29
[alerts_unread] => 29
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 339
[warning_points] => 0
[is_staff] => 0
[secret_key] => iAnkz9GTDfivRmH1BOp6OTrgESJR57G8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22016] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 91
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22016
[node_id] => 2
[title] => Could Taiwan Stocks See More Volatility? Morgan Stanley Slashes Nvidia GB200 Shipment Forecast – Two Stocks Directly Targeted
[reply_count] => 0
[view_count] => 237
[user_id] => 332041
[username] => XYang2023
[post_date] => 1738644987
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81196
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738644987
[last_post_id] => 81196
[last_post_user_id] => 332041
[last_post_username] => XYang2023
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 64
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 332041
[username] => XYang2023
[username_date] => 0
[username_date_visible] => 0
[email] => xiao.yang17@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => Australia/Sydney
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 656
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1708819075
[last_activity] => 1738708398
[last_summary_email_date] => 1723213219
[trophy_points] => 63
[alerts_unviewed] => 0
[alerts_unread] => 3
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 451
[warning_points] => 0
[is_staff] => 0
[secret_key] => NBs1n4BMtljiqSmfC-EZI_MMUn9Rzevl
[privacy_policy_accepted] => 1708819075
[terms_accepted] => 1708819075
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[21768] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 95
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 21768
[node_id] => 2
[title] => Will the Chinese DeepSeek AI upset the AI/ML race?
[reply_count] => 79
[view_count] => 5872
[user_id] => 10499
[username] => Arthur Hanson
[post_date] => 1735579262
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 79431
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738637140
[last_post_id] => 81186
[last_post_user_id] => 332041
[last_post_username] => XYang2023
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 72
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 10499
[username] => Arthur Hanson
[username_date] => 0
[username_date_visible] => 0
[email] => a-j-hanson@att.net
[custom_title] =>
[language_id] => 1
[style_id] => 1
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 3158
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1366028460
[last_activity] => 1738701174
[last_summary_email_date] => 1606051785
[trophy_points] => 83
[alerts_unviewed] => 5
[alerts_unread] => 5
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 389
[warning_points] => 0
[is_staff] => 0
[secret_key] => ta_8_Pj20m6PDO6RnrGK-VnSP_vyhP_m
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[21967] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 99
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 21967
[node_id] => 2
[title] => Trump To Tariff Chips Made In Taiwan, Targeting TSMC
[reply_count] => 88
[view_count] => 7764
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1738029427
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 80782
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1738629145
[last_post_id] => 81174
[last_post_user_id] => 38642
[last_post_username] => VCT
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 12873
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1738710309
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 133
[alerts_unread] => 133
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 5555
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22012] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 103
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22012
[node_id] => 2
[title] => Intel Packaging in the U.S.
[reply_count] => 4
[view_count] => 349
[user_id] => 38642
[username] => VCT
[post_date] => 1738609397
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81145
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738619548
[last_post_id] => 81156
[last_post_user_id] => 170880
[last_post_username] => nghanayem
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 100
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 38642
[username] => VCT
[username_date] => 0
[username_date_visible] => 0
[email] => whung7@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 384
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1621013199
[last_activity] => 1738705146
[last_summary_email_date] => 1669472430
[trophy_points] => 63
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 300
[warning_points] => 0
[is_staff] => 0
[secret_key] => V4mwFDRdVh7TOJgJF8v7ZKblcLijrxKj
[privacy_policy_accepted] => 1621013199
[terms_accepted] => 1621013199
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22002] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 107
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22002
[node_id] => 2
[title] => Would Optane have been good for AI inference?
[reply_count] => 7
[view_count] => 839
[user_id] => 35301
[username] => Xebec
[post_date] => 1738417199
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81065
[first_post_reaction_score] => 1
[first_post_reactions] => {"1":1}
[last_post_date] => 1738613375
[last_post_id] => 81150
[last_post_user_id] => 35301
[last_post_username] => Xebec
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 104
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 35301
[username] => Xebec
[username_date] => 0
[username_date_visible] => 0
[email] => john.heritage@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => America/New_York
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 834
[question_solution_count] => 0
[conversations_unread] => 1
[register_date] => 1598710106
[last_activity] => 1738710607
[last_summary_email_date] => 1631629203
[trophy_points] => 93
[alerts_unviewed] => 0
[alerts_unread] => 0
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 853
[warning_points] => 0
[is_staff] => 0
[secret_key] => Y7XyJgQMBi7ZiDtuAyqNGDrBQQsi8JB4
[privacy_policy_accepted] => 1598710106
[terms_accepted] => 1598710106
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22009] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 111
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22009
[node_id] => 2
[title] => Chipmaker STMicroelectronics may cut 2,000 to 3,000 jobs in France and Italy
[reply_count] => 3
[view_count] => 359
[user_id] => 20231
[username] => Barnsley
[post_date] => 1738555336
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81124
[first_post_reaction_score] => 0
[first_post_reactions] => {"4":1}
[last_post_date] => 1738603952
[last_post_id] => 81143
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 80
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 20231
[username] => Barnsley
[username_date] => 0
[username_date_visible] => 0
[email] => apickering72@gmail.com
[custom_title] =>
[language_id] => 1
[style_id] => 0
[timezone] => Asia/Irkutsk
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 813
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1429440429
[last_activity] => 1738690129
[last_summary_email_date] => 1653315673
[trophy_points] => 63
[alerts_unviewed] => 29
[alerts_unread] => 29
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 339
[warning_points] => 0
[is_staff] => 0
[secret_key] => iAnkz9GTDfivRmH1BOp6OTrgESJR57G8
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22011] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 115
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22011
[node_id] => 2
[title] => Pat Gelsinger: Wisdom – Learning the lessons I thought I already knew (part 2)
[reply_count] => 0
[view_count] => 249
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1738603328
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81140
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738603328
[last_post_id] => 81140
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 12873
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1738710309
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 133
[alerts_unread] => 133
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 5555
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[21999] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 119
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 21999
[node_id] => 2
[title] => China’s €37 Billion Push to End Europe’s Semiconductor Dominance Shakes Global Markets
[reply_count] => 9
[view_count] => 1814
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1738344877
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81025
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738603174
[last_post_id] => 81139
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 12873
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1738710309
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 133
[alerts_unread] => 133
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 5555
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22010] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 123
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22010
[node_id] => 2
[title] => The AI/ML technology process race has just begun
[reply_count] => 0
[view_count] => 104
[user_id] => 10499
[username] => Arthur Hanson
[post_date] => 1738596829
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81134
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738596829
[last_post_id] => 81134
[last_post_user_id] => 10499
[last_post_username] => Arthur Hanson
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 72
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 10499
[username] => Arthur Hanson
[username_date] => 0
[username_date_visible] => 0
[email] => a-j-hanson@att.net
[custom_title] =>
[language_id] => 1
[style_id] => 1
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 2
[secondary_group_ids] =>
[display_style_group_id] => 2
[permission_combination_id] => 8
[message_count] => 3158
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1366028460
[last_activity] => 1738701174
[last_summary_email_date] => 1606051785
[trophy_points] => 83
[alerts_unviewed] => 5
[alerts_unread] => 5
[avatar_date] => 0
[avatar_width] => 0
[avatar_height] => 0
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 0
[is_admin] => 0
[is_banned] => 0
[reaction_score] => 389
[warning_points] => 0
[is_staff] => 0
[secret_key] => ta_8_Pj20m6PDO6RnrGK-VnSP_vyhP_m
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[22008] => ThemeHouse\XPress\XF\Entity\Thread Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 127
[rootClass:protected] => XF\Entity\Thread
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[thread_id] => 22008
[node_id] => 2
[title] => The blogger who helped spark Nvidia’s $600 billion stock collapse and a panic in Silicon Valley
[reply_count] => 1
[view_count] => 660
[user_id] => 5
[username] => Daniel Nenni
[post_date] => 1738542720
[sticky] => 0
[discussion_state] => visible
[discussion_open] => 1
[discussion_type] => discussion
[first_post_id] => 81122
[first_post_reaction_score] => 0
[first_post_reactions] => []
[last_post_date] => 1738552190
[last_post_id] => 81123
[last_post_user_id] => 20231
[last_post_username] => Barnsley
[prefix_id] => 0
[tags] => []
[custom_fields] => []
[vote_score] => 0
[vote_count] => 0
[type_data] => []
)
[_relations:protected] => Array
(
[User] => ThemeHouse\XLink\XF\Entity\User Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 48
[rootClass:protected] => XF\Entity\User
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[user_id] => 5
[username] => Daniel Nenni
[username_date] => 0
[username_date_visible] => 0
[email] => dnenni@semiwiki.com
[custom_title] => Admin
[language_id] => 1
[style_id] => 0
[timezone] => America/Los_Angeles
[visible] => 1
[activity_visible] => 1
[user_group_id] => 3
[secondary_group_ids] => 4,5,132
[display_style_group_id] => 3
[permission_combination_id] => 88
[message_count] => 12873
[question_solution_count] => 0
[conversations_unread] => 0
[register_date] => 1280720820
[last_activity] => 1738710309
[last_summary_email_date] => 1605968657
[trophy_points] => 113
[alerts_unviewed] => 133
[alerts_unread] => 133
[avatar_date] => 1663211649
[avatar_width] => 110
[avatar_height] => 107
[avatar_highdpi] => 0
[gravatar] =>
[user_state] => valid
[security_lock] =>
[is_moderator] => 1
[is_admin] => 1
[is_banned] => 0
[reaction_score] => 5555
[warning_points] => 0
[is_staff] => 1
[secret_key] => 0HwyUVVHCwJotUUVEpvqAclfYJdGNPpw
[privacy_policy_accepted] => 0
[terms_accepted] => 0
[vote_score] => 0
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
[Forum] => XF\Entity\Forum Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 50
[rootClass:protected] => XF\Entity\Forum
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[discussion_count] => 6885
[message_count] => 46065
[last_post_id] => 81229
[last_post_date] => 1738711158
[last_post_user_id] => 5
[last_post_username] => Daniel Nenni
[last_thread_id] => 22015
[last_thread_title] => The US Is Now Investigating Whether Singapore Is Responsible For Supplying NVIDIA’s AI Chips To China
[last_thread_prefix_id] => 0
[moderate_threads] => 0
[moderate_replies] => 0
[allow_posting] => 1
[count_messages] => 1
[find_new] => 1
[allow_index] => allow
[index_criteria] =>
[field_cache] => []
[prefix_cache] => []
[prompt_cache] => []
[default_prefix_id] => 0
[default_sort_order] => last_post_date
[default_sort_direction] => desc
[list_date_limit_days] => 0
[require_prefix] => 0
[allowed_watch_notifications] => all
[min_tags] => 0
[forum_type_id] => discussion
[type_config] => {"allowed_thread_types":["poll"]}
)
[_relations:protected] => Array
(
[Node] => XF\Entity\Node Object
(
[_uniqueEntityId:XF\Mvc\Entity\Entity:private] => 49
[rootClass:protected] => XF\Entity\Node
[_useReplaceInto:protected] =>
[_newValues:protected] => Array
(
)
[_values:protected] => Array
(
[node_id] => 2
[title] => SemiWiki Main Forum ( Ask the Experts! )
[description] => Post your questions to the experts here!
[node_name] =>
[node_type_id] => Forum
[parent_node_id] => 1
[display_order] => 1
[display_in_list] => 1
[lft] => 2
[rgt] => 3
[depth] => 1
[style_id] => 0
[effective_style_id] => 0
[breadcrumb_data] => {"1":{"node_id":1,"title":"Main Category","depth":0,"lft":1,"node_name":null,"node_type_id":"Category","display_in_list":true}}
[navigation_id] =>
[effective_navigation_id] =>
)
[_relations:protected] => Array
(
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[_previousValues:protected] => Array
(
)
[_options:protected] => Array
(
)
[_deleted:protected] =>
[_readOnly:protected] =>
[_writePending:protected] =>
[_writeRunning:protected] =>
[_errors:protected] => Array
(
)
[_whenSaveable:protected] => Array
(
)
[_cascadeSave:protected] => Array
(
)
[_behaviors:protected] =>
)
)
[populated:protected] => 1
)
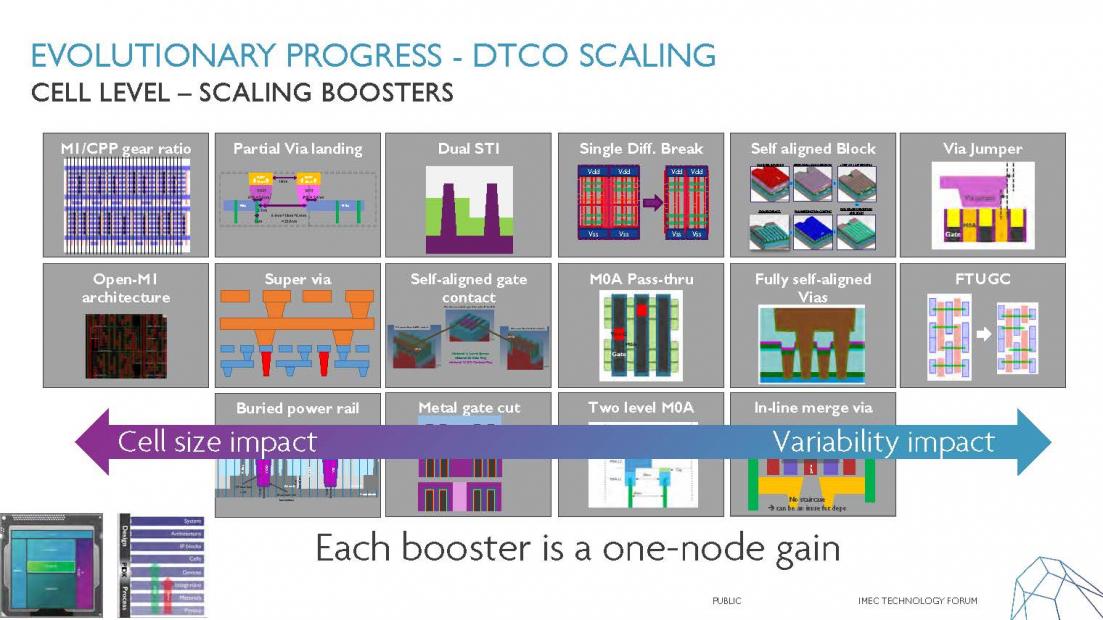
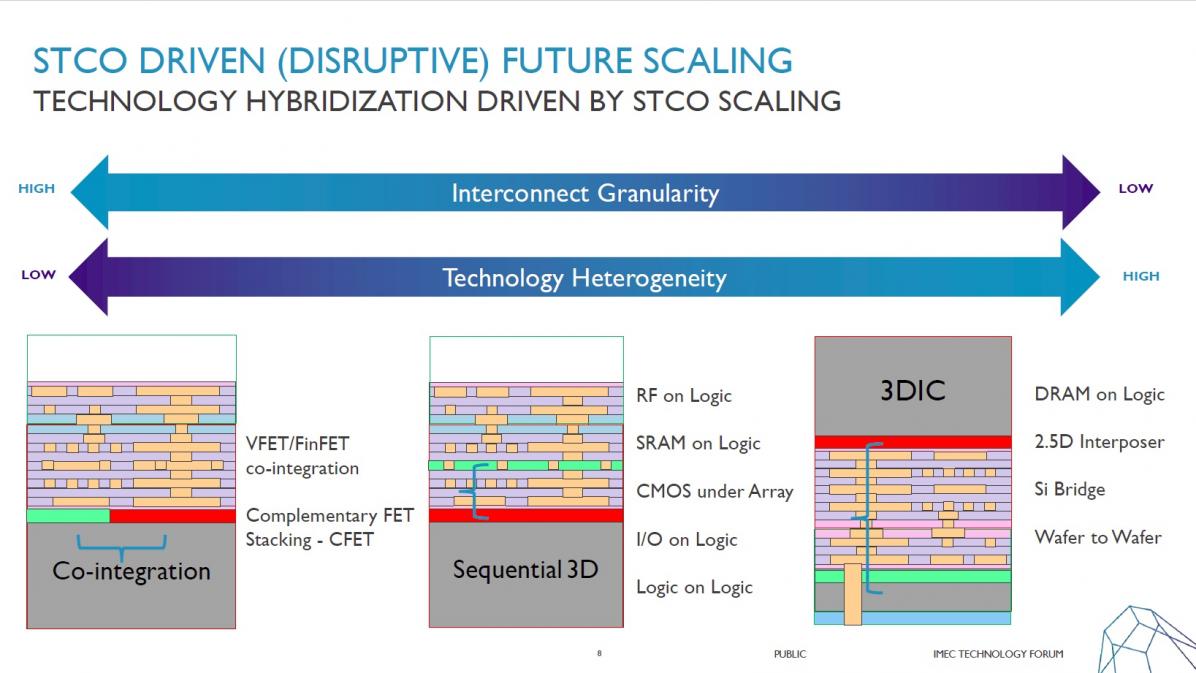
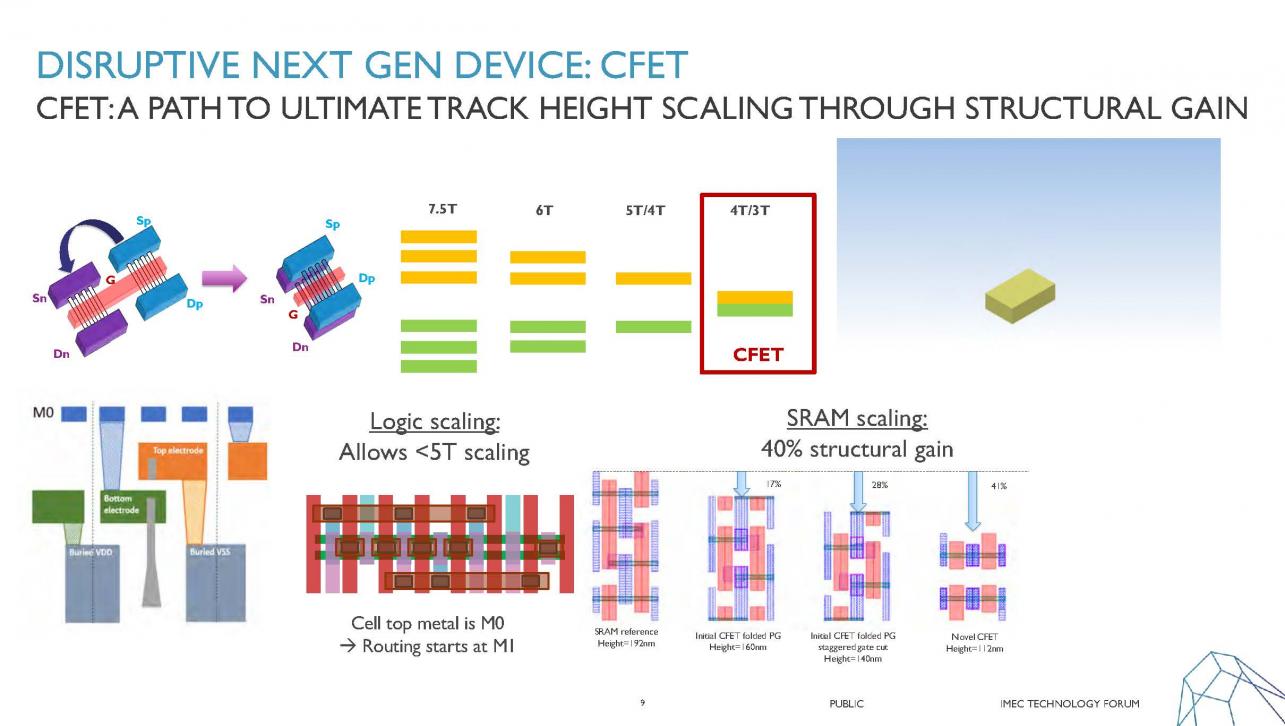
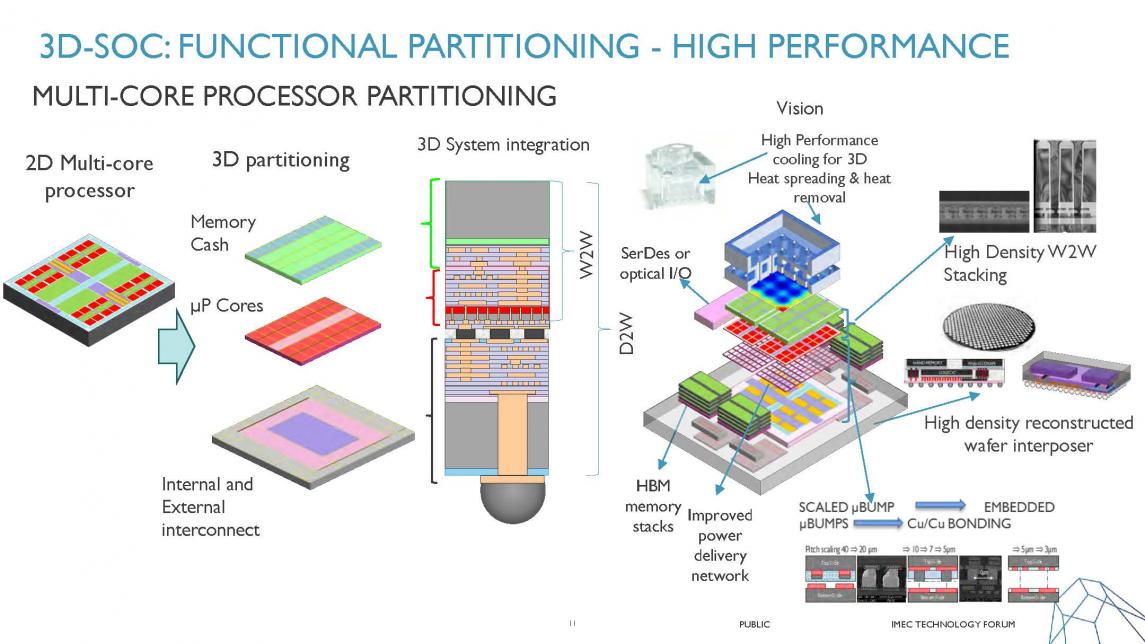




Comments
There are no comments yet.
You must register or log in to view/post comments.