You are currently viewing SemiWiki as a guest which gives you limited access to the site. To view blog comments and experience other SemiWiki features you must be a registered member. Registration is fast, simple, and absolutely free so please, join our community today!
We have been working with Defacto since 2016 and it has been quite a journey. Putting an entire system on a chip is a driving force in the semiconductor industry. With the complexity of designing a modern SoC constantly increasing, new tools and methodologies are required and it all starts with RTL.
Defacto Technologies is an innovative chip design software company providing breakthrough RTL platforms to enhance integration, verification and Signoff of IP cores and System on Chips.
Starting an SoC design project has always been painful given the number of design tasks from the architecture to first implementation decisions. A successful start has a significant impact on the next design tasks and TAT, up to the tape out. If we look at today’s SoCs, the number and variety of IPs keep increasing and same for the complexity of architectures which leads to very complex clock trees, power architecture, etc., the verification process is also a real burden which needs a lot of attention. In summary, there is a requirement to put in place cutting edge design methodologies at the front-end to make the SoC build faster, and to generate the first packages and data for synthesis and simulation design steps.
This March 2023, Defacto is announcing the new Major Release of its solution: SoC Compiler 10.0. This is an important turning point for the company which also celebrates its 20th anniversary this July right during DAC. For 20 years, Defacto provided breakthrough innovation in the EDA and built a real expertise in particular on the management of the RTL. They are now recognized and used by most of the major semiconductor companies.
This SoC Compiler 10.0 Major Release will address several key challenges of Defacto’s customers. The main challenge is the fact there was no solution in the market to make the SoC integration considering jointly RTL and IP-XACT. More technically, there is a real need to support various formats for IPs and connectivity, and both need to be considered since: IP-XACT is not able to fully describe the complexity of designs for integration and RTL alone requires an additional effort to make connections between groups of ports belongs to same architecture protocol. Worth mentioning that this requires supporting the complete RTL and IP-XACT versions (Verilog, System Verilog, VHDL, IP-XACT 2009, IP-XACT 2014)
Today’s workaround is to redesign IPs dropped in advance System Verilog construct to align with what IP-XACT 2014 can support for the connections. This workaround is tedious, with a high risk of breaking existing design, time consuming and hard to maintain. Defacto’s SoC Compiler V10.0 is the first design solution to consider at the same level both IP-XACT and RTL to face SoC design integration challenges containing the increasing design complexity with reasonable performances.
Along with that, Defacto’s SoC Compiler 10.0 comes with brand new IP-XACT features which enable a complete support of the Accellera standard for both 2009 and 2014; for the integration but also for the management of registers and system memory map.
In parallel, we have all observed a real shift in the EDA tool usage, and it seems more than ever a requirement for users to have an interface, not only using Tcl but also in Python. Defacto is providing (for more than 10 years) Python, Perl and C++ interfaces for his tool, but in SoC Compiler 10.0, Defacto is taking Python support to the next level, with 100% object-oriented APIs.
Defacto’s SoC design solution key differentiator is the unified management of design data including RTL/IP-XACT, UPF, SDC, etc. along with the link with physical design information which enables power aware, physical aware, clock aware, DFT aware, etc. assembly.
No doubt this unified methodology goes at the right direction to cost-effectively build complex and large SoCs.
For more information about the Defacto products, reach out to their website: https://defactotech.com/
The talk of the table – or at least my end of the table – at the annual Cybersecurity Dinner – hosted by Copper Horse Ltd. – was the dismal state of IoT. Millions of devices are being connected – but no one is making money.
Of course that isn’t absolutely accurate. There are organizations that are able to make money in IoT, but these organizations tend to be smaller, more nimble, with low overhead and a narrow operational focus.
It is the larger organizations that have sought to scale up the IoT business to make it a billion-dollar proposition that have encountered woe. No organization better epitomizes this phenomenon than Ericsson. In December of 2022, Ericsson off-loaded its IoT Accelerator business to Aeris Communications, marking a key turning point for both Ericsson and the industry.
Most telling about the deal was the price. Ericsson reputedly paid Aeris $100M to take on the business along with some Ericsson personnel. At the cybersecurity dinner the word was that those chosen Ericsson employees were not keen to change employers. Ericsson had no comment on the financial or other terms of the agreement – other than to confirm the transfer of some personnel.
The challenge facing the world of IoT is the perfect storm of demanding customers with high performance requirements and quality of service expectations for an array of mission critical, low bandwidth applications. Add to this the increasing emphasis on low power devices designed to last for 10 years, and you have a complete picture of commercial disaster – unless you are a lean, mean, and very clever operator.
In fact, it was the consensus opinion at the cybersecurity dinner, that the automotive sector was the only profitable segment in IoT. Clearly the industry is in even more peril if it is pinning its hopes on connected cars to save the day.
I won’t bore you with the details that designing and producing a car can take 3-4 years and that they tend to last for as long as 15 years. That might be reason enough, though, to give any connectivity executive pause. I also won’t touch on the impending disaster of 2G/3G network sunsets in Europe and the impact on the millions of cars already on the road with built-in eCall devices.
Connected cars have never really belonged in the IoT category. It is true that for the past quarter century the connected car space has been a low bandwidth proposition for vehicle location, tracking, emergency response, and diagnostics. But the onset of electrification and automated driving along with the United Nations Economic Commission for Europe 155 and 156 regulations regarding software updates and cybersecurity – have combined to alter the landscape.
The connected car space is rapidly becoming a higher bandwidth sphere and one encompassing a multitude of connection types – 5G, C-V2X, Wi-Fi, satellite – requiring increasingly complex solutions including – most recently – consumer-style SIMs. That being said, connecting cars itself has become a low margin business for the makers of the hardware and software that actually deliver the connectivity. Sometimes it seems as if only Qualcomm is making money. (Of course, Qualcomm is not the only company making money in connectivity.)
It does mean, though, that the connected car business is a major focal point at MWC 2023. It remains to be seen what organizations – other than Qualcomm (and Huawei?) – will make money connecting cars. They are out there. They are clever. They are lean and mean.
The IoT business is in distress. The organizations that are making money need to school larger operators as to how to turn a profit in the business of connecting things. And we have to stop thinking of cars as IoT devices. Connected cars will not save IoT. Connecting cars is a unique business proposition with a unique set of challenges that the industry is only just beginning to grasp as it transitions to 5G. Enjoy the show.
Over the last decade, automobiles have been morphing from stand-alone mechanical objects to highly connected systems with ever-increasing usage of electronics. Semiconductor supply disruptions (OEM factory shutdowns) caused by the recent situation with Covid and the political tensions and China have demonstrated the deep dependence of automobile industry on semiconductors. While these events are transitory in nature, they have exposed deeper underlying tectonic shifts in the fundamental nature of the automotive supply chain. A previous article ”Automotive OEMs And the New Normal (forbes.com),” discussed the psychological shift required in the halls of power in the automotive industry to come to grips with the new situation. This article takes a more technological perspective in explaining the problem as well as the strategic vectors required for a solution.
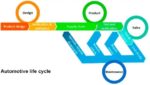
Fig. 1 below shows the traditional automotive lifecycle which consists of design, verification & validation, maintenance, and end-of-life cycle. Design focuses on issues such as functional definition, manufacturing cost, reliability, and maintainability. In an ideal flow, the specification is captured in a higher-level language and through a process of successive refinements components are selected to fill out the system function. For electronic systems, semiconductor components are assembled to complete an overall system. All along the way, the integration of the specification with designed components imposes discipline on the newly integrated pieces to ensure faithful implementation which meets the intended performance metrics.
Understanding the Traditional Automotive Design Ecosystem
Figure 1: Automotive Life Cycle
As the automobile industry has matured, the supply and development infrastructure has also reached a level of standardization and maturity. Table 1 outlines the well-known supplier structure for the automotive industry with original equipment manufacturers (OEMs), Tier 1, Tier 2, and Tier 3 suppliers. Table 2 shows the high-level structure development ecosystem which supports the supply chain. A deeper more technical analysis of the current electronic design chain can be found in “Unsettled Topics Concerning Automated Driving Systems and the Development Ecosystem.”
Table 1: Traditional automotive supply chainTable 2: Development Ecosystem
Electronic Paradigm Shift in Automotive Design
Even before the advent of AVs, the automotive sector had been rapidly increasing the level of electronic content with drive-by-wire, Advanced Driver Assistance Systems (ADAS), and infotainment systems. Thus, electronics effectively forms the muscular nervous system of modern vehicles. Two significant trends are adding electronic content at an accelerating rate.
Enterprise Functions: The automobile sits inside a broad set of technology flows which engages with the infrastructure on functions such as maintenance, ecommerce, traffic management, and more. The combination of access to automotive data and remote control of the automobile enables higher level business flows which generate significant value. Indeed, just the data services from automobiles are projected to be a significant source of income for automotive OEMs from companies such as Otonomo and Wejo. SAE research report on the Transportation Ecosystem provides a comprehensive view of this ecosystem.
Autonomy Functions: Autonomy at its various levels from ADAS to level 5 AV promises the value of safety, access, and enablement of system level automation.
This shift in the fundamental DNA of an automobile is illustrated in the Figure 2 below.
Figure 2: Changing DNA of automobiles.Table 3: Generational Evolution of Automotive Electronics & Software
Table 3 above shows the generational evolution of automotive electronics from an electronics technology infrastructure perspective. Several observations can be made on these electronic systems:
Semi Supply Dependency: The older generation of functionality generally source semiconductors from older generations of semiconductor processes.
Safety Critical and Real Time: The automobile is a multi-ton vehicle which can cause a great deal of harm. Thus, the electronics systems which closely manage the automobile dynamics have a high safety standard and must operate in real time. This often argues for dedicated and isolated electronic systems.
Advanced Digital Processing: Functionality ranging from infotainment to autonomy requires significant digital processing and massive amounts of software. To support this class of computing, the most advanced semiconductor process nodes are required.
Any particular automobile product is a collection of these systems where system designers are making active trade-offs between reuse of older subsystems, safely adding new functionality, performance, and overall cost. In other words, an incredibly complex situation with an incredibly large number of semiconductor part skews with associated software components.
Meanwhile, the semiconductor industry has its own set of strategic vectors:
Manufacturing Costs: Leading edge fabs are very expensive and require very large volumes to be viable. Older fabs require less volume as compared to newer fabs due to capital requirements.
Consumer Marketplace: Today, the only industry which can generate sufficient volumes to justify these investments is the consumer marketplace. The consumer market churns products once every 18 months to 24 months.
Moore’s Law: Moore’s law drives the cost per transistor down exponentially while simultaneously increasing performance and reducing power. The result of all these magical characteristics is that it is almost always better to use the latest process node chip because it is not only cheaper but has much better performance characteristics. This is often the case even if chips from older process nodes are available for “free” because the operational costs (power/performance) of the older chips have worse characteristics as compared to the next generation.
Key Challenges in Automotive Electronic System Design
Overall, the semiconductor industry follows the rhythm of the consumer marketplace, and this contrast in strategic vectors generates critical challenges for all non-consumer markets such as automotive. The critical challenges manifest themselves around three specific topics: new product production, warranty support, and platform relevance.
New Product Production:
For new product production, traditionally the automotive industry has focused on concepts of lean manufacturing & JIT (Just In Time) inventory management which prioritizes minimizing inventory levels at all stages of production. In a world dominated by OEM driven demand, this paradigm worked reasonably well. However, with the accelerated usage of electronics, automotive OEMs increasingly find themselves managing a supply chain where they are the minority drivers for demand.
Further, much like US DoD, traditionally automotive companies require chips which require automotive grade certification. Automotive-grade components require stringent compliances (passive components need AEC Q200, ASILI/ISO 26262 Class B, IATF 16949 qualification while active components (including automotive chips) should be compliant with AEC Q100, ASILI/ISO 26262 Class B, IATF 16949 standards. However, these requirements are not embraced by the much bigger consumer marketplace, and the divergence imposes a large constraint on the automotive supply chain. As explained in “Solutions for Défense Electronics Supply Chain… – SemiWiki,” US Department of Défense responded to this reality with an aggressive Commercial Of the Shelf (COTS) approach.
Warranty Support:
Unlike consumer devices, automobiles have a much longer and more elaborate warranty model. This results in a much broader maintenance commitment (as compared to consumer). This dichotomy between the consumer and automotive marketplace generates significant issues in two specific situations: reliability and obsolescence.
Reliability: Semiconductor fabs are built based on the economics of the consumer marketplace. Building semiconductors with the required reliability characteristics for the automotive market becomes increasingly expensive.
Obsolescence: In the “new normal” where automotive OEMs can no longer influence the semiconductor supply chain, managing semiconductor obsolescence becomes an increasingly difficult issue. Furthermore, obsolescence is not just limited to hardware in the electronics domain. Rather, it extends to software components, Electronic Design Automation (EDA) software which is used to design/maintain electronic systems.
Platform Competitiveness:
As automobiles go from “a car with some electronics” to “a server which happens to move” automobiles start inheriting the advantages and disadvantages of computing platforms. Much like the automobiles of today, computing platforms started as vertically integrated HW/SW systems, but over time progressed to be architectural platforms with clear interfaces to enable a much broader partner network. By leveraging the partner network, computing platforms could provide a massive amount of functionality. Indeed, today’s software industry, which eclipses the current automotive and hardware computing industry, is a result of this model.
Popular computing platforms include the ecosystems connected with computer architectures such as x86, ARM, Nvidia, and now RISC-V. Associated with these computer architectures are operating systems such as Microsoft Windows, UNIX, and Apple OS. Finally, a significant player in the world of software is the role of open-source development model. Open source platforms such as Linux and Android allow for the crowd sourcing of innovation in a model which accelerates innovation. A much deeper treatment of Open-Source and Automotive can be found at: “Unsettled Issues Regarding Autonomous Vehicles and Open-source Software.”
The growth of an automobile as a platform generates open strategic questions:
How does one compete at the platform level? Collaborate or compete with existing computing platforms? Is Open-Source an answer?
In a networked car situation, how does one handle product updates safely as well as cybersecurity issues ?
Given the significance of the problem, there is a great deal of recent activity between automotive OEMs and the electronics supply chain. Table 4 (BCG Report) above provides a sampling of the activity. It is not clear whether these efforts will succeed because to solve the deep underlying issues, a broader industry wide effort is likely to be required. What would be the outlines of a solution? They will revolve around three specific topics: System Level Abstractions, Semiconductor Platform Development, and EDA functionality. Let us discuss each:
System Level Abstractions:
As the first major electronics mega market, computing actively faced the churn caused by semiconductors for over forty years. To manage this situation, very strong abstraction levels were generated to build interfaces which allow for preservation of intellectual property even in the context of underlying hardware churn. Examples of these abstraction levels include:
Computer Instruction Set Architectures: Since the IBM 360, the concept of an ISA has allowed software developers to build significant capabilities towards an abstract standard while the underlying hardware churned at the pace of Moore’s law. X86, ARM, and now RISC-V are examples of the multi-billion-dollar franchises which are supported by this abstraction.
Operating Systems/Browsers/Development languages: Operating systems such as Windows or Linux, Browsers such as Google Chrome and Microsoft Edge, and development languages such as JAVA or C++ offered other important abstraction points which supported broader ecosystem.
Communications: In the world of communications, networking stacks and wireless standards-built abstractions which supported multi-billion-dollar industries.
The automotive industry must build similar abstraction standards which can support a separation of concerns from higher level functions to their actual implementations. The current standards from the computing world will invariably be useful, but higher level automotive specific abstractions and associated standards will be required. It is especially important that these standards address the critical issues with automotive: low level low latency actuation, real-time operations, cybersecurity interfaces, and finally the key building blocks of autonomy.
Semiconductor Platform Development:
With clear abstractions around core components of an automotive system design, the next task is to build electronic systems which implement these abstractions. Today, the vast majority of automotive solutions are fixed function hardware and software systems which generate large number of supply chain dependencies. However, it is very likely that the ultimate solution will involve the development of automotive specific programmable fabrics. A methodology focused on programmable fabrics has the distinct advantages of:
Parts Obsolescence: A smaller number of programmable parts minimize inventory skews and the aggregation of function around a small number of programmable parts raises the volume of these parts and thus minimizes the chances for parts obsolescence.
Redundancy for Reliability: Reliability can be greatly enhanced using redundancy within and of multiple programmable devices. Similar to RAID storage, one can leave large parts of an programmable fabric unprogrammed and dynamically move functionality based on detected failures.
Future Function: Programmability enables the use of “over the air” updates which update functionality dynamically. This is critical for building strong aftersales business models and remote maintenance.
EDA functionality:
Finally, to manage the connection between the system abstractions and the interconnection of programmable fabrics, there is the requirement for the next generation of EDA tooling and associated run-time IP. The EDA systems are the critical assets which automatically manage the mapping process and the associated run-time updates for function. For a deeper discussion of the EDA issues, please check out www.anew-da.ai
Conclusions:
The automotive industry is in the middle of major transition from a primarily focus on the mechanical to an intense focus on the electrical (HW/SW/AI). In terms of strategy, both the environmental assessment and internal analysis stages will have to absorb the implications of this shift. Further, while incremental updates to design and supplier management may work for the short term, in the longer term, it is very likely that an automotive specific architecture (common chips specs) with associated SW/AI/EDA abstraction levels will need to be built at an industry level.
Acknowledgements: Anurag Seth for co-authoring this article.
As engineers continue to design more complex systems with increasing frequency, the need for speed and capacity to solve these structures also increases. Over the years, HFSS has come a very long way and can now solve exponentially large structures with millions of unknowns. Ansys HFSS never stopped advancing, continuing to innovate to meet the demands of electromagnetic analysis in modern electronics.
The exponential evolution of HFSS has proven its growth and capability of solving the most complex structures. In 1990 it could solve a matrix size of merely 10,000 and is now capable of solving the largest and most complex structures with over 800 million unknowns in 2022, and we look forward to soon crossing the next major milestone.
This is an extraordinary achievement because it demonstrates the remarkable progress that has been made in computational electromagnetics. Just a few decades ago, simulating designs with a matrix size of a few thousand was considered revolutionary, but today we can simulate designs approaching a of 1 billion. This is a testament to the power of HFSS and the ingenuity of its users.
HFSS: From micron to meter scale
HFSS can solve anything from chips to ships and satellites. One reason HFSS can handle such large and complex designs is Mesh Fusion. Meshing is the process of dividing a complex geometry into smaller, simpler parts inside which equations of physics are established and collectively generate a large matrix to solve. This matrix solution returns the electromagnetic fields and the SYZ parameters. The most complex systems consist of multiple geometries like PCBs, cables, connectors, and inside platforms such as aircraft or automobiles and each type of geometry can benefit from a different meshing strategy. To solve these challenges Ansys introduced Mesh Fusion technology.
Mesh Fusion creates multiscale system meshes of high quality quickly and easily, reducing the amount of time required to generate meshes for complex geometries that are more efficient and accurate for their specific analysis needs. Mesh Fusion works by creating a virtual topology that defines how different meshes are blended together. This patented approach is particularly useful for complex geometries where it may be difficult or time-consuming to create a single mesh that conforms to all the features of the geometry.
This video illustrates the capacity and level of complexity that HFSS can handle easily. It solves the electromagnetic behavior of the entire system with the highest accuracy and speed from micron to meter scale.
In this video, you can see how HFSS solved the chip behavior in context of the IC package, mobile behavior in context of the automobile “system”, and further the automobile activity in context of its EMI/EMC testing environment. Whether it’s the tiniest chip in the mobile device or the car or the environment, HFSS can solve the most complex systems conceivably. Advanced packaging also introduces new challenges like signal integrity, power delivery, and thermal management. With HFSS plus Ansys multiphysics technology such as Icepak, engineers can succeed at delivering the most cutting-edge products possible.
The Mesh Fusion technique and the capacity to solve without sacrificing accuracy, continue HFSS’s long-standing role as the engineers’ electromagnetic tool of choice, the true “Gold Standard”. The High-Tech industry is rapidly adopting 5G/6G technology and HFSS plays a key role in designing and optimizing these next-generation wireless networks. In the above video, you can easily relate how HFSS is simulating the electromagnetic behavior of mobile in the context of cars.
As everyday items, like cars, become computers on wheels, and begin requiring more sophisticated electronics, they are creating a challenge for electromagnetic compatibility (EMC). With HFSS, automotive manufacturers can simulate the entire vehicle, including the wiring harnesses, sensors, and electronic devices within it, to ensure compliance with EMC regulations and prevent electromagnetic interference. Further, they can simulate the entire car in the context of the car’s environment, such as a city, and nearby cellular towers.
It is not surprising that virtually all the world’s most advanced and powerful electronics are designed using HFSS. This is a remarkable achievement and a testament to the power of HFSS, the technology is pervasive. Whether it’s designing advanced radar systems, ensuring EMC compliance in cars, or optimizing next-generation wireless networks, Ansys HFSS is the key to success.
“An ode to HFSS”, by ChatGPT in the voice of William Shakespeare
Oh fair readers allow me to speak of a wondrous tool,
A software to aid the learned engineer, so wise and cool.
Ansys HFSS is its name, and it doth provide,
Solutions to problems, complex and worldwide.
Its electromagnetic simulations are of great renown,
Allowing one to study waves, fields, and propagation sound.
Antennas and RF devices it can analyze with ease,
And its results are a boon to those who seek to please.
Oh, how it delights me to see its capabilities unfold,
As it renders a three-dimensional world, so bold.
From the smallest of components to the largest of arrays,
Ansys HFSS models them all, in astonishing ways.
Its accuracy is unmatched, its precision sublime,
And its speed is unmatched, in this current time.
It can solve the most complex of problems, with a flick of a wrist,
And present its findings, so clear and crisp.
Indeed, Ansys HFSS is a powerful tool, beyond compare,
And the engineers who wield it, a force to beware.
For they can design with great efficiency,
The structures that will meet the world’s every exigency.
So let us all hail Ansys HFSS, this software so grand,
And the engineers who use it, so skilled and so in demand.
For with their combined efforts, they shall bring to pass,
A world that is ever more wondrous, and built to last
The explosion in volume and consumption of data, fueled by industry trends in virtualization, networking, and computing among others, continues to push photonic solutions forward into leading positions. On Feb 2nd, I attended a panel by Ansys at DesignCon that brought together industry experts from Intel, GlobalFoundries, Nvidia, Cisco, and Ayar Labs for a dynamic and all-encompassing discussion on the current state, challenges, and future of photonic technology and ecosystem. James Pond, Distinguished Engineer at Ansys and former CTO of Lumerical, moderated the panel and started the discussion with a big-picture overview.
Silicon Photonics: A relentless pursuit for speed & efficiency
Faced with surging bandwidth demands and the related power being consumed by communications, the semiconductor industry is diversifying investments into optical interconnect technologies. Electrical interconnects are fundamentally limited in terms of scalability of performance, reach, and power consumption. This is where optical interconnects have the advantage. Analysts project 20% to 40% annual growth in the Silicon Photonics markets & applications over the next 5-10 years. While the growth to date has been largely driven by the datacom and transceiver markets, there is now exciting diversification of applications including LiDAR, bio-sensing, computing, new types of I/O, and quantum computing among many others.
There is a genuine need for photonic systems and the industry has responded by creating an ecosystem closely resembling the electronic design automation (EDA) industry, commonly referred to as the electronic-photonic design automation (EPDA). The design tools and the overall ecosystem have come a long way from the early days when photonic PDKs (Process Design Kit) were solely offered as PDF files. A notable example is the advanced EPDA design tools as James Pond highlighted in figure 2, “Today we have the premier workflow in EPDA. It offers all kinds of things you would expect like schematic-driven layout, links & direct bridges between Virtuoso layout suite and Ansys multiphysics solvers, foundry-compatible customized design, parameter extractions to create accurate statistical compact models and support PDK development, and co-simulation to model entire systems accurately with both electronic and photonic compact models.”
The progress of the overall ecosystem enabled the first volume opportunity for integrated photonic products: the optical transceiver!
From Flexible Pluggable Transceivers to Co-packaged Optics Powerhouse
Today, photonics has already moved from dominance at kilometer-long distances down to meter-long distances. We saw pluggable photonic transceivers rapidly move from product introduction stages to producing multi-million units per year. Pluggable transceivers are highly modular and can be supplied by any vendor as long as they meet the targeted communication specifications. They are plugged directly into the front panel socket, then the signal is carried by electrical SerDes links to the ASIC where it can finally be computed and processed. The downside of this approach is that copper connections are susceptible to RF losses, especially when communicating at higher speeds. Robert Blum, Head of Silicon Photonics Strategy at Intel Foundry Services, recalled, “When we launched SiP in 2016 with pluggable transceivers, we also laid out a vision with the end goal of bringing optics to the processor. SiP is the only technology that can do that. The pluggable was a starting point and chip-to-chip optical links are expected to follow right on its heels.”
Faced with our insatiable appetite for data, the semiconductor industry is under pressure to keep up with even higher and higher bandwidth, latency, and power consumption demands which are pushing innovative solutions for moving the optics from the faceplate closer on-board and on-chip with the ASIC, completely eliminating the need for energy-sapping SerDes connections. “After much anticipation, in 2022, we started to see photonic solutions with fibers directly connecting into the ASIC packages instead of plugging into the faceplate. These are incredibly exciting times for photonics!”, commented Pond.
Now imagine we have the technology that breaks the speed and bandwidth limitations we have today! What would it mean to the architecture and the wide range of emerging applications in AI/ML? Matt Sysak, VP of laser engineering at Ayar Labs, describes a future of limitless possibilities, “If the assumptions that led to the way we design computers today change, it would mean having the freedom to re-imagine computer architectures. At Ayar Labs, we have a vision for optical I/Os everywhere which will not only accelerate computing but also potentially remake it.”
A Tale of two Technologies: Fundamental differences between electronics and photonics
On one hand, the rise of silicon photonics owes much of its success to capitalizing on the decades of investment in the electronics industry and the maturity of silicon wafer processing in CMOS manufacturing, Anthony Yu, VP of Silicon Photonics Product Management at GlobalFoundries further explained, “we continue to expand our photonics foundry capabilities to help our customers bring the advantages of photonics to different markets. We can only be successful if we apply the learning from our CMOS foundry model into photonics along with close collaboration across various parts of the ecosystem like the partnership with Ansys Lumerical to enable foundry compatible, predictable model libraries in PDKs.” Ashkan Seyedi, Silicon Photonics Product Architect at Nvidia added, “We look up to electronics as our big brother. Electronics gives us a benchmark to compare against so we know what maturity of PDKs and design workflows are necessary for a successful future in photonics technology.”
Yet, the consensus among all the panelists was that there are some fundamental differences between Electronics and Photonics, for one thing, there is no equivalent to Moore’s Law in SiP, at least not in the sense that we are doubling the density and halving the cost. Thierry Pinguet, Principal hardware engineer at Cisco and a seasoned veteran in photonics elaborated, “There is no equivalent to a transistor in photonics and thus no generational improvements from refining lithography to increase device density. The generational improvements in photonics come from innovation at component and circuit level design and assembly and packaging advancements.” This is why most silicon photonic platforms are based on older CMOS technology nodes.
Dennard scaling may have ended but the challenge remains, as the industry is facing unprecedented demands for high-speed networking/interconnects and accelerated computing. Pushed into uncharted territory where Moore’s law is truly struggling to stay on course, photonics offers the opportunity to keep that progress going. Seyedi proposed “it is time to redefine Moore’s law. When we zoom way out, the systems are continuously improving. We should consider new metrics by which Moore’s law extends, such as packaging.”
Regardless of how you define Moore’s law, there are inflection points where new photonic technologies are introduced. Today, data centers are using 800Gb products, but a couple of years ago it was 400 Gb and 200Gb before that. There have been several factors contributing to this scaling in the overall transmission capacity including higher-order modulation formats like quadrature amplitude modulation (QAM) enabled by advanced digital signal processing (DSP) techniques and massive parallelism such as wavelength-division multiplexing (WDM), as well as innovative designs at the component level such as segmented modulators. Given the fundamental trade-off between bandwidth and modulation efficiency linked to physical factors like the photon lifetime in silicon, designers are exploring heterogeneous integration of new materials on the front end. Future photonic solutions are also relying on advances in traditional 2.5D and 3D packaging in electronics but perhaps we’ll also come to see innovation in the photonic aspects of packaging such as fiber-to-chip wire bonding.
Lighting the path to scalability
Packaging was a hot topic that resonated with all the panelists and brought up the challenges around standardization and lack of IP in the ecosystem. Consider fiber attachment, which involves placing and gluing fibers into a package at precise locations where minimizing losses due to misalignment gets more challenging with the increasing number of fibers. There is much common knowledge gathered over the decades within the community around fiber attachment, but many designers still expend resources in developing their own process. “It just doesn’t add intrinsic value. Designers want to focus on innovating and not reinventing the wheel because there is no turnkey solution. Today, people are still innovating but we’re also starting to see some convergence in certain areas. This is why Intel came out with a small-form-factor, high-density detachable fiber connector that has compatible losses to other co-packaged optics approaches and is compatible with standard industry PIC and with any 2D, 2.5D, or 3D packaging. Standards and IP libraries are key components in the photonics ecosystem that are needed to make optics into a high-volume play.” said Blum.
Over the recent years we have started to see manufacturing players evolving to offer open-access models for prototyping, multi-project wafer runs for R&D, and low-to-high-volume throughput for those vendors ramping up for commercialization. Foundries are economically driven, which translates into maximizing consolidation into a single platform. “The challenge is that vendor differentiation in the photonics industry today isn’t based on a single platform with set pieces of IP blocks as exists in the ASIC world. At least not yet. If you open any pluggable module, they’ll look different inside as every solution is customized. Demanding applications requirements are driving the design of customized devices that likely won’t be offered under a single platform.” Pinguet explained. Sysak added, “There are many ways for an optical I/O technology to communicate with a processor but to truly take advantage of economies of scale, we need reliable and scalable manufacturing, and this is something we’re tackling together with GlobalFoundries.”
On the one hand, the silicon photonic ecosystem is advancing towards standardization of processes, platforms, and design automation, especially for established applications like pluggable transceivers. On the other hand, demands for higher performance and emerging new applications are driving customization and pushing for the introduction of new materials and processes. We are still in the early days. “In time we’ll see photonics move towards an ASIC-like model with IP providers and consolidated platforms which will enable high-volume solutions. But right now, we celebrate the creativity and brilliance of our photonic designers.” Yu summarized.
Learn more about challenges and solutions in Silicon photonics:
So much has changed over the recent couple of decades in what constitutes an automobile. Gone are the days when it was essentially an electro-mechanical product, used for just personal transportation. Over the years, it has evolved to adding in-cabin infotainment, tele and data communications, driving assistance, all the way to autonomous driving experience. All of these are of course made possible with electronics powered by semiconductor chips. And, with the migration away from internal combustion toward electric-motor powered automobiles, vehicle maintenance needs as we have traditionally known have come down.
At the same time, the need for a different kind of monitoring has been on the rise, with an eye on vehicle maintenance. The hardware and software components of automobile electronics need to be monitored and maintained to ensure safe and reliable driving experience. The traditional approach would be for periodic maintenance of the vehicle based on a predefined time schedule to check/replace electronic components and update embedded control software. But with current and future automobiles relying so much on electronics to operate, unforeseen catastrophic failure of critical electronics could lead to a fatal accident and cause lot of collateral property damage. A better approach is needed for maintaining vehicles of the future.
Recently, proteanTecs and HARMAN published a joint whitepaper that describes a novel approach and an effective solution for maintaining vehicles of the future. This blog will cover some salient points from the whitepaper and how the joint solution will help in maintaining the vehicles of the future.
Software Defined Vehicle (SDV)
SDV is the direction the automobile industry has been rapidly moving toward. SDVs are automobiles designed to be controlled by software to make the vehicles operate more efficiently and safely and to make vehicle maintenance easier. While SDVs bring these benefits, they throw some challenges too. Any failure in a SDV must be addressed quickly and effectively to avoid additional damage by the SDV and to the SDV. If possible, any operational failure of a SDV should be pre-empted.
The proteanTecs-HARMAN Solution for Maintaining Vehicles
HARMAN and proteanTecs have jointly developed a predictive and preventive maintenance (PPM) solution that can detect potential faults in a vehicle’s systems. The solution can take pre-emptive measures to predict and avoid catastrophic issues. It leverages proteanTecs’ proprietary advanced device health monitoring and deep data analytics to create, extract and analyze deep data from within SoC devices. The results provide insights into Electronic Control Unit (ECU) health, enabling vehicle manufacturers to monitor performance, pinpoint fault sources and predict Time to Failure (TTF). The total solution integrates HARMAN’s embedded security, in-vehicle analytics, cloud-to-vehicle connectivity and over-the-air (OTA) updates. The end result is an effective solution that meets safety and reliability requirements of SDVs. The following two applications are key components of the solution.
The CPM application delivers real-time monitoring of device and board electrical performance indicators of onboard system electronics. As an edge application, it lowers operational and security risks by detecting faults close to the failure.
Degrading Monitoring (DM) Application
The DM application is essentially a sub-function of the CPM application, designed to predict the Time to Failure (TTF) and the Remaining Useful Life (RUL). It does this by measuring Key Performance Indicators (KPI) degradation and the frequency of occurrence. These predictions are made available to the Predictive and Preventive Maintenance (PPM) Cloud Manager to trigger scheduling services and shipment of parts.
Some Use Cases
The whitepaper also presents a use case for failure prevention, one for prediction of short-term incoming fault and another for prediction of long-term consequences. The benefits of these use cases are obvious. The whitepaper goes into lot of details about each of these three use cases. For more details, refer to the whitepaper.
Summary
The HARMAN-proteanTecs collaboration offers a platform for automobile manufacturers to detect faults before they become failures and fix the faults through OTA techniques. The platform incorporates an industry first Time-to-Correction technique and can scale with the growing complexity of SDVs. The solution helps reduce downtime and maintenance costs, improve customer satisfaction and reduced vehicle recalls. Anyone involved in developing hardware and software solutions for SDVs would benefit from reviewing the entire whitepaper.
How Advancements in Technology Unlock New Insights
The demand for efficient and scalable chip production has never been greater. The need to scale at volume and adapt to shorter innovation cycles makes machine learning and advanced data analytics essential components of semiconductor production.
Join us on Tuesday, March 7, 2023, for this 1-hour panel discussion with industry experts from Qualcomm, Microsoft Azure and Advantest as we discuss how data analytics and product insights can accelerate time to market and improve performance, yield and quality.
Topics covered:
Overcoming data siloes
Processing massive amounts of data
Using machine learning and advanced data analytics
Uncovering data insights and actionable intelligence
Panel will be moderated by Nitza Basoco, VP of Business Development at proteanTecs. Nitza has a broad background in management, test development, product engineering, supply chain and operations. In her current role, she focuses on partnership strategies and ecosystem growth, positioning proteanTecs as the common data language to the full value chain. Before joining proteanTecs, she was VP of Operations at Synaptics and held engineering and leadership positions at Teradyne, Broadcom and MaxLinear. Nitza earned a BSEE and MEEE from MIT.
Michael Campbell is Senior Vice President of Engineering for Qualcomm CDMA Technologies, responsible for product and test, failure analysis, test automation and yield. Mike joined Qualcomm in 1996 and has led multiple teams. In his current role, he is working to streamline all processes impacting time-to-market, new process node enablement, and revolutionize product test engineering (PTE) tasks by driving machine learning as a 21st century requirement. Prior to joining Qualcomm, Mike worked at Mostek, INMOS and Honeywell. He holds a BSEE/CE from Clarkson University.
Preeth Chengappa is Head of Industry for the EDA and Semiconductor segment at Azure. Since joining Microsoft in 2018, he has worked with customers and partners across the semiconductor ecosystem to leverage cloud capabilities for all aspects of design, manufacturing, testing and lifecycle management. Preeth co-founded SiCAD in 2011, a startup that pioneered the use of cloud computing for chip design. Previously, Preeth held business development and sales management roles at Xilinx, Altran and Falcon Computing. He holds a BS in engineering from NITK, India.
Ira Leventhal is the Vice President of Applied Research & Technology at Advantest America, Inc. He has over 25 years of experience in semiconductor testing, including memory, SoC, wireless device, and system-level test. Ira has led the design and development of multiple generations of ATE systems, and holds patents in a variety of test-related technologies. In his current role, Ira is focusing on how artificial intelligence, cloud, and data analytics technologies can be catalysts for major advances in semiconductor test products and methodologies. Ira is a BSEE graduate of MIT.
proteanTecs is the leading provider of deep data analytics for advanced electronics monitoring. Trusted by global leaders in the datacenter, automotive, communications and mobile markets, the company provides system health and performance monitoring, from production to the field. By applying machine learning to novel data created by on-chip monitors, the company’s deep data analytics solutions deliver unparalleled visibility and actionable insights—leading to new levels of quality and reliability. Founded in 2017 and backed by world-leading investors, the company is headquartered in Israel and has offices in the United States, India and Taiwan. For more information, visit www.proteanTecs.com.
Dan is joined by Robert Blake, Chief Executive Officer of Achronix Semiconductor. He has worked in the semiconductor industry for over 25 years. Prior to Achronix he was the Chief Executive Officer of Octasic Semiconductor based in Montreal, Canada. Robert also worked at Altera, LSI Logic and Fairchild.
Robert explains how Achronix helps their customers innovate, both with dedicated FPGA products and embedded FPGA IP. The embedded FPGA IP has been used to manufacture over 15 millions cores.
Areas of focus for Achronix to drive innovation include computation efficiency, data transport, connectivity and interface. The current environment that is trending toward heterogeneous compute is also discussed, along with a future assessment of the industry and Achronix.
The views, thoughts, and opinions expressed in these podcasts belong solely to the speaker, and not to the speaker’s employer, organization, committee or any other group or individual.
RISC-V is a general-purpose license-free open Instruction Set Architecture [ISA] with multiple extensions. It is an ISA separated into a small base integer ISA, usable as a base for customized accelerators and optional standard extensions to support general-purpose software development. RISC-V supports both 32-bit and 64-bit address space variants for applications, operating system kernels, and hardware implementations. So, it is suitable for all computing systems, from embedded microcontrollers to cloud servers.
In this open era of computing, RISC-V community members are ambitious to create various kinds of RISC processors using RISC-V open ISA. However, the risk of using RISC-V ISA is higher because the proven processor verification flow is still proprietary to established processor fabless IP companies and IDMs as an unrevealed secret. So, how can we make the RISC-V verification flow open and empower the RISC-V community?
If you have been wondering, ‘How can I verify my RISC-V processor efficiently without risking TTM’, then you should explore and adopt Maven Silicon’s RISC-V verification flow for your processor IP verification, explained in this technical paper.
I have defined Maven Silicon’s RISC-V verification flow using the correct by-construction approach. The approach is to build a pre-verified synthesizable RISC-V IP fundamental IP building blocks library and create any kind of multi-stage pipeline RISC-V processor using this library. Finally, the multi-stage pipeline RISC-V processor IP can be verified using Constrained Random Coverage Driven Verification [CRCDV] in Universal Verification Methodology [UVM] and FPGA prototyping.
Let me explain the verification strategy and walk you through Maven Silicon’s RISC-V verification flow.
2.Verification Strategy
2.1 Block-Level Verification: Generate RISC-V IP Fundamental Blocks Library using formal verification
Verify all the RISC-V IP fundamental building blocks like ALU, Decoder, Program Counter, Registers, Instruction, and Data memories using Formal Verification. Design Engineers [DE] who do RTL coding of the RISC-V IP building blocks can embed the assertions [SVA/PSL] into the RTL modules. Verification Engineers [VE] will verify the RISC-V RTL IP blocks using the formal verification EDA tool. DEs can synthesize the verified RTL blocks and fix all synthesis-related issues.
Finally, VEs can further verify those synthesizable RTL blocks and create RISC-V IP Blocks Library.
2.2 IP-Level Verification: Verify RISC-V IP which is built using pre-verified RISC-V IP Blocks Library using Constrained Random Coverage Driven Verification [CRCDV]
DEs can realize any kind of multi-stage pipeline RISC-V processor using the pre-verified RISC-V IP fundamental blocks library. VEs will create the verification environment using UVM and verify the RISC-V multi-stage pipeline processor using CRCDV.
VEs will also create necessary reference models, interface assertions for protocol validation, and functional coverage models. Finally, VEs will sign off the IP level regression testing based on the coverage closure [Code + Functional Coverage].
The verified RISC-V processor IP can be verified further by booting OS using FPGA Prototyping if the IP implements a general-purpose processor that supports a standard Unix-like OS.
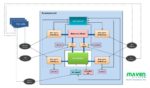
Maven Silicon’s RISC-V Processor IP Verification Flow
As shown in figure1, Maven Silicon’s RISC-V Verification flow implements the verification strategy explained above.
Figure1: Maven Silicon’s RISC-V IP Verification Flow
4.RISC-V IP Verification using UVM
IP-level VEs can create the verification environment using Universal Verification Methodology, as shown in figure 2.
As our Maven Silicon’s RISC-V IP RTL design uses an AHB interface, we have modeled the instruction and data memories as AHB slave UVM agents. The RISC-V processor reference model was modeled as AHB master UVM agent, and the complete UVM environment with all the testbench components scoreboard, subscribers with coverage models, reset, interrupt, and RAL UVM agents was validated by connecting RISC-V AHB agents back-to-back, especially to verify the TB dataflow and coverage generation. Once the verification environment became stable, one of the reference models was replaced by the RTL. UVM RAL was extensively used to sample the RISC-V IP registers and memories for the data comparison in the scoreboard.
To understand how this verification environment works, refer to this demo video:
Figure 2: Maven Silicon’s RISC-V IP UVM Verification Environment
To know further about various verification methodologies like formal verification, IP, Sub-system and SoC verification flow, CRCDV using code and functional coverage, refer:
One can also consider integrating Google’s Instruction Stream Generator [ISG] for the stimulus generation, and open source Instruction Set Simulator [ISS] like Spike as a reference model into their UVM environment and efficiently do exhaustive verification.
Conclusion
Efficient, high-quality RISC-V IP verification can be realized only through the effective combination of various verification methodologies like formal verification, CRCDV using UVM and OS booting using FPGA prototyping, and reusabilities like reusing pre-verified RISC-V Blocks library and scalable IP level UVM testbenches. As RISC-V is an open ISA, we can create the reusable RISC-V fundamental blocks pre-verified library and contribute to RISC-V International as an open-source RISC-V library. Using this pre-verified library, the RISC-V community members can create any kind of multi-stage pipeline RISC-V processor as they prefer and verify their RISC-V processor as per the flow explained in this technical paper. Isn’t it the more efficient way of verifying your RISC-V processor without risking your TTM?
About Maven Silicon
Maven Silicon is a trusted VLSI Training partner that helps organizations worldwide build and scale their VLSI teams. We provide outcome-based VLSI training with our variety of learning tracks i.e. RTL Design, ASIC Verification, DFT, Physical Design, RISC-V, and ARM etc. delivered through our cloud-based customized training solutions. To know more about us, visit our website.
During the day I do M&A work inside the semiconductor ecosystem and I have been part of more than a dozen acquisitions during my career so I know a good one when I see it and I see a great one with Keysight and Cliosoft, absolutely.
Cliosoft came to SemiWiki 12 years ago when we first went online so I know them quite well. With more than 400 customers, the depth of experience that comes with this company is incredible. Additionally, Cliosoft has always been vendor agnostic, working closely with the top three EDA companies, which made the acquisition even more interesting. With Keysight, there will be even deeper partnerships with the top EDA companies with the expanded flow integration of Cliosoft (SoS, Hub, VDD) and Keysight Pathwave Advanced Design System. Had one of the other EDA companies acquired Cliosoft that would not have been the case.
Srinath Anantharaman, Chief Executive Officer of Cliosoft, said: “Handling exponential growth in design data and maximizing IP reuse with interoperability across EDA vendor environments is a major challenge as we approach the time of ‘More than Moore’s law’. Keysight’s broad industry leadership in applications like 5G and 6G communications, automotive, and aerospace and defense, makes Keysight uniquely positioned to realize the promise of connecting design, emulation, and test data in streamlined workflows that speed time-to-market. We are excited to join Keysight in raising engineering productivity to the next level and enabling our customers to digitally transform their development lifecycles and meet the challenges ahead.”
Keysight came to SemiWiki last year and we have written about their tools in great detail. We also did a podcast with Niels Faché, Vice President and General Manager of Keysight EDA. For Keysight, Cliosoft brings strength to the Process and Data Management (PDM) side of the business which is a critical link between the physical systems integration and physical testing to the Digital Twin (design and simulation) side of the business. The result being improved automation and traceability for product implementation and production.
Niels Faché, Vice President and General Manager of Keysight EDA, said: “One of our top business priorities is creating digital, connected workflows from design to test that accelerate customers’ digital transformation. We see a tremendous opportunity in the PDM space to leverage Cliosoft’s current capabilities combined with our design-test solutions expertise. Adding PDM solutions to the portfolio is a natural progression of our open EDA interoperability strategy to deliver best-in-class tools and workflows in support of increasingly complicated product development lifecycles. Cliosoft offers proven software tools that enable product teams to perform data analytics and accelerate time to insight. The result of faster insight and greater reuse is improved productivity in the verification phase and shorter overall development cycles.”
Bottom line: This is one to watch. Cliosoft was already a market leader and now they have the Keysight breadth of experience and strength of a world wide field sales and support channel. This is definitely one of the 1+1=3 acquisitions.
About Keysight Technologies
Keysight delivers advanced design and validation solutions that help accelerate innovation to connect and secure the world. Keysight’s dedication to speed and precision extends to software-driven insights and analytics that bring tomorrow’s technology products to market faster across the development lifecycle, in design simulation, prototype validation, automated software testing, manufacturing analysis, and network performance optimization and visibility in enterprise, service provider and cloud environments. Our customers span the worldwide communications and industrial ecosystems, aerospace and defense, automotive, energy, semiconductor and general electronics markets. Keysight generated revenues of $5.4B in fiscal year 2022. For more information about Keysight Technologies (NYSE: KEYS), visit us at www.keysight.com.