To many of us, if we ever think about interconnect on an SoC, we may think delay, power consumption, congestion, that sort of thing. All important points from an implementation point of view, but what about the functional and system implications? In the early days, interconnect was very democratic, all wires more or less equal, connecting X to Y wherever needed. If you had a data bus, you’d route that more carefully to ensure roughly equal delays for each bit, which works pretty well when you don’t have a lot of on-chip functions. But there’s more to it than that. This blog is a quick introduction to interconnect basics.

Interconnect Basics: Crossbars
As process sizes shrank, we jammed more functions onto each chip, each handling fatter data busses. This created a lot more connectivity around the chip. Masses of wiring didn’t scale down as fast as the functions. Connecting X to Y wherever needed was no longer practical because, in the ad-hoc approach, the number of connections scales up much more rapidly than the number of functions.
Enter the crossbar switch. Like old-style telephone switches, everyone connects to a central switchboard. But this switchboard can only allow one active call at a time. If X wants to talk to Y, it has to make a request to a central controller – the arbiter, which may be busy handling a conversation between A and B, so X and Y have to wait until that earlier conversation is complete. Still, you no longer need a rats-nest of connections, making the whole thing more scalable, at the expense of becoming more bureaucratic and waiting for your turn in line.
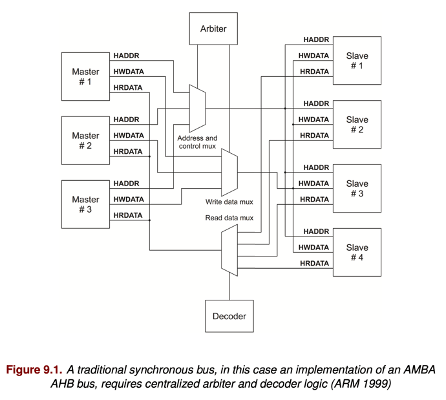
As soon as we see bureaucracy, we want to streamline it. We can have more than one switchboard, so local calls in different regions don’t tie each other up. Then we have separate switchboards for long-distance calls. We can even interleave calls (at least for data). In the Arm AMBA architecture, you can have multiple switches, each with its own protocol supporting different levels of sophistication. But each is still (mostly) a one conversation at a time switch, perhaps with interleaving. This can make it challenging to manage the quality of service, such as guaranteed response times in safety-critical systems. Also, while crossbar switches are way better for managing congestion than ad-hoc wiring, they still can get pretty bulky when they have to support the fat busses we see these days (64 bit or more).
Interconnect Basics: Networks on chip (NoCs)

Which brings me to networks on chip (NoCs). These are inspired by computer networking concepts (though not as complex), with a layered architecture separating physical, transaction and transport layers and using data packetization and routing. Pretty obvious in hindsight. PCI-Express was one early example. Arteris IP introduced the first commercial NoC IP implementation in 2006 and saw rapid adoption in some of the leading SoC vendors because those vendors had no choice but to move to a more effective interconnect to meet their PPA and quality of service goals. (I’m sure in some cases there was also an internal NoC versus purchased NoC debate. Evidence suggests Arteris IP won most of those battles.)
This NoC approach provides obvious advantages over the earlier methods. First, because data is packetized with header data, it’s much easier to control the quality of service through rules. There’s no chance that one communication hog can lock up the whole network until it’s done. You can control protocols for those who get priorities and for how long before the next conversation gets a shot. Similarly, it’s much more scalable than crossbars. Network interface units handle packetization at each IP interface to the network. The network doesn’t bear any of that load, which means that the transport and routing can be very lightweight and fast.
Implementation control
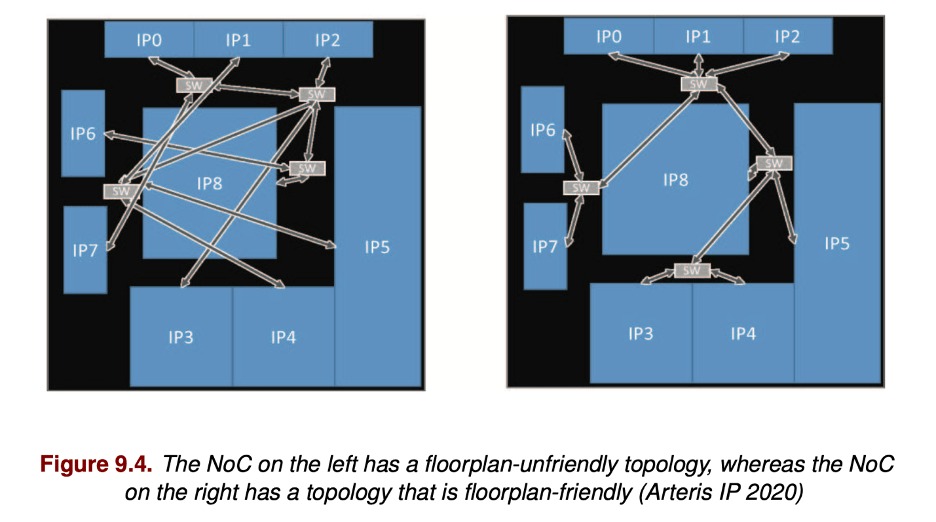
Because the physical layer is separate from transport and transaction, you are free to optimize implementation choices locally (such as using one wire or more than one) to best serve performance needs versus congestion. This is, I think, one of the deal closers for NoCs, something that is next to impossible for crossbar architectures. In a NoC, you can adjust topology locally (between routers) to best manage floorplan needs. Equal deal closers are attainable quality of service with your own transport rules, and ease of timing closure in the Arteris IP architecture because they use a globally asynchronous, locally synchronous (GALS) approach in the network.
NoCs aren’t just for the top-level
I could go on, but I’ll leave you with one more thought. For a while, serious SoC developers thought “OK, we’ll still use crossbars inside our IPs and subsystems, but we’ll use a NoC at the top-level.” Now the NoCs are starting to move inside the subsystems too, particularly as AI accelerators are moving onto these systems. For all the same reasons: networks needing to span huge designs, controllable quality of service, controllable timing closure, etc., etc.
To learn more, here’s a great peer-reviewed Springer paper that describes a real-world example of how to set up quality of service with a NoC, using Arteris IP FlexNoC as the interconnect: “Application Driven Network-on Chip Architecture Exploration & Refinement for a Complex SoC”
Also Read:
Where’s the Value in Next-Gen Cars?
AI, Safety and Low Power, Compounding Complexity
Share this post via:



Comments
2 Replies to “Interconnect Basics: Wires to Crossbar to NoC”
You must register or log in to view/post comments.