You are currently viewing SemiWiki as a guest which gives you limited access to the site. To view blog comments and experience other SemiWiki features you must be a registered member. Registration is fast, simple, and absolutely free so please, join our community today!
Safety is a complex topic, but we’re busy. We take the course, get the certificate. Check, along with a million other things we need to do. But maybe it’s not quite that simple. I talked recently with Kurt Shuler (VP of marketing) and Stefano Lorenzini (functional safety manager) at Arteris IP and concluded that finding enlightenment in safety is more of a journey than a destination. I’m going to share with you a few stories they told me which highlight this journey. Because journeys / stories are my favorite way to share an idea.
We know safety; this is just a bigger design
If you’ve been building auto components for years, what’s new? A common problem, still, is in missing something in the Assumptions of Use (AoU). That part of the spec describing how the consumer of a chip expects to be able to use your system. Paradoxically, this can be more of a problem among established experts in automotive design. They already know safety; they’re just scaling up, integrating more IP and a bigger interconnect. The chip safety experts get involved late in the game; someone checks the fine print in an AoU and figures out, “Oops, we missed something.” They ask their IP supplier for help. The supplier pulls out all the stops and figures out a solution.
A few months later, the same integration team contacts them again, “Hey, we found another AoU problem.” Most of us are ready to bail out a favored customer once. Twice is asking too much. Kurt sent one customer a big quote; the second time around wouldn’t be free.
A somewhat related problem is this, “I need a solution, but what we’re doing is secret, so I can’t tell you exactly what I need. Why don’t you propose a solution, and I’ll tell you if it will work. If not, propose a different solution.” An open-ended discovery for no extra $$. It happens; it’s frustrating and expensive for a supplier who didn’t create the problem. And unhealthy for the integrator’s schedule.
I’ve just finished training; it must be done exactly this way
At the other end of the scale, in some ways, is the safety manager who insists on everything being presented precisely the way they were trained. FMEDA spreadsheets must have exactly the same columns, in the same order, with the same headers. No room for deviation. This confuses the standard with a regulation. Different users (semiconductor and Tier1 certainly) have their own preferred ways to organize data. Maybe it might be nice if they all did it in exactly the same way, but they don’t. Absent the force of a regulation, suppliers can’t bridge the gap by providing a different format for every customer preference.
The message here is – take a deep breath. What’s important is that the intent be satisfied, not that formats match exactly with the training course you took. Which introduces a subjective element, not always comfortable to our engineering brains, but that’s the way it is.
The RTL is frozen; we’ll fix it in software
You found a problem, but you already closed the door on RTL changes. Maybe you have a safety coverage problem in one function where you didn’t add safety mitigation logic. Now what do you do? You could potentially add a software fix. If the potential issue is a transient fault, you could run the step twice and compare. All software-driven. The tradeoff is that you add latency or throttle bandwidth a little when doing that. Especially if this is something you are doing through the NoC.
So now you need to have a talk with your customers’ safety manager. You missed a safety mechanism in design; as a result, your coverage is, say, 0.2% lower than it could have been. That’s one option. Or you could make a software fix which would raise the coverage back up. But performance would take a hit. You have run tests to characterize what impact that would have. What do they think?
You could argue that this was a particularly tricky case, and you’ve put a process in place to make sure it won’t slip past you in the future. Maybe you get lucky. Your customers also have tight schedules. And it is just 0.2%. They tell you OK, but this better not become a pattern. They expect continuous improvement.
Enlightenment
Kurt and Stefano agreed. It’s important to meet the intent – the spirit of the standard, not word by word precision. Worthy partners may be willing to bail you out, but don’t abuse that privilege. Finally, recognize that safety is a journey of collaboration and continuous improvement. The best of us will get better together. Those who aren’t willing to shoulder their share will have to find their own way.
You can learn more about Arteris IP investment in safety HERE.
The move to true 3D IC, monolithic 3D SOC and 3D heterogeneous integration may require one of the most major design tool architecture overhauls since IC design tools were first developed. While we have been taking steps toward 3DIC with 2.5D designs with interposers, HBM, etc., the fundamental tools and flows remain intact in many cases. 3D IC designs that fully utilize and optimize silicon across all three dimensions offer big payoffs in performance, power and area (PPA) efficiency. This shift will also require IC tools and flows that work in a fully 3D manner.
Recently I had a chance to speak with Kenneth Larsen, director of product marketing at Synopsys, about the changes necessary to accommodate the move to 3D IC. Simply put, up until now the tools for 2D design and even those for 2.5D design have mostly worked in two-dimensional space. While there is a 3D component in all semiconductor designs, the operational paradigm has been to rely on 2D tools for design and layout accompanied by a lot of verification. It has been this way since the 1970s. With true 3D design, where several active chips are stacked together for the best solution, this will no longer be the case. New tools, like 3DIC Compiler Design Platform from Synopsys, that can drive PPA optimization across the cubic space of the 3D silicon stack will be needed.
There are many reasons to move to 3D IC design. In the case of systems-on-a-chip (SOCs), it means that instead of building a large monolithic die that has everything in one process technology, the optimal process technologies can be used for each specific subsystem while maintaining short interconnections and increasing density. The smaller subsystem dies from the disaggregated SOC can be selectively included in the final product. Even if separate processes are not needed, yield can increase with the use of small chip dies. Also, for SOCs that have different end-markets, SOCs can be disaggregated into so-called chiplets that can be reused and shared among several projects, amortizing cost so they can be shared over more designs.
Improved PPA Using 3D IC
Kenneth touched on the increased complexity that arises and how Synopsys 3DIC Compiler provides an environment that can handle the new workload. Bouncing between tools for digital implementation, custom implementation, packaging, analysis and test can create inconsistencies and lost transactions which exacerbate with increasing 3D design complexities. It is evident that similar to 2D IC design today, 3D IC design can also benefit from a unified flow environment that enables co-design of IP, silicon dies and package.
A 3D IC design will have through silicon vias (TSVs) and lateral die-to-die connections as signals move up and down in the Z-direction. There will be die-to-die connections with billions of bonds. According to Kenneth, the Synopsys 3DIC Compiler design management and data environment has been optimized for three-dimensional designs with more than 500 billion objects. Kenneth reviewed several approaches that are being used in the industry today, such as TSMC 3DFabric, Samsung X-Cube and Intel Foveros. The big takeaway was that there will be increasing flexibility in the way dies are connected within 3DICs and the software will need a native 3D representation to accommodate this.
The kinds of analysis and verification that are needed include multi-die thermal, signal and power integrity, static timing, as well as extraction and physical verification. The Synopsys 3DIC Compiler Design Platform integrates the leading golden sign-off tools from Synopsys and partners including Ansys via its 3D tool interoperability framework. The platform has been deployed into production use and has multiple tape-outs that have proven its value since its launch less than a year ago.
The leap from 2D to 3D has been a long time coming, but the days of hacking 2D applications for 2.5D designs are over. My conversation with Kenneth was informative and showed how heavily Synopsys has invested in creating a flow and environment that can support this new design approach. The case for 3D IC based design is compelling. More information on 3DIC Compiler from Synopsys is available on their website.
FinFETs devices are reaching their limits for scaling. Horizontal Nanosheets (HNS) are a type of Gate All Around (GAA) device that offers better scaling and performance per unit area. HNS is the logical next step from FinFETs because HNS processing is similar to FinFETs with a limited number of process changes required.
At the VLSI Technology Symposium, Imec presented on their Forksheet (FS) work that offers enhanced HNS scaling and performance. I had an opportunity to discuss the work with Naoto Horiguchi of Imec.
Authors note, The height of standard cells used to create logic layouts is determined by the metal pitch and number of tracks high the cell is.
Cell Height = Metal Pitch x Tracks
If you look at a 5-track HNS cell a significant amount of the height is taken up with the n to p device spacing, see figure 1. left side. In a FS process a dielectric wall is introduced between the n and p devices enabling reduced n to p spacing, see figure 1. right side (for example ~40nm to ~17nm).
Figure 1. HNS Versus FS Structure.
The reduced n-p spacing can be utilized in two different ways. The first option is to utilize the additional space in the cell to make the sheets wider improving drive current. The dielectric wall introduced for FS also reduces capacitance. Figure 2. Illustrates the layout and performance advantages.
Figure 2. Power – Performance – Area (PPA) Advantage.
The second option is to keep the sheet width the same and reduce the tracks. FS can enable a 4.3-track cell and even 4-track cells are possible with a special Middle-Of-Line (MOL) construct.
FS do degrade the electrostatic control of the device slightly versus the GAA structure of a HNS, FS can be thought of as a FinFET turned on its side with gates on three sides as opposed to GAA structures. Authors Note, FinFET gate length (Lg) is generally limited to ~16nm due to leakage issues whereas HNS Lg can scale to ~13nm. In this work HNS and FS were created on the same wafer and the SSSAT (Subthreshold Slope) and DIBL (Drain Induced Barrier Lowering) were identical, but the Lg was a relatively long 22nm
TCAD work is underway to evaluate shorter Lg. Figure 3. illustrates the SS degradation for a 16nm Lg and shows how the degradation can be mitigated by recessing the channel.
Figure 3. FS Electrostatic Degradation.
In addition to enabling improved scaling and performance, FS have two other advantages over HNS.
When creating multiple threshold voltages, multiple types, and thicknesses of work function metals (WFM) are deposited and patterned. The high aspect ratio of the HNS devices can result in wet etch undercut of the WFM. The introduction of the dielectric wall provides a WFM etch barrier preventing undercut, see figure 4.
Figure 4. FS Dielectric Barrier.
Another advantage of the FS is the dielectric wall provides additional mechanical support to the channel nanosheets. I asked about drying concerns with HNS structure and was told that with the FS support longer channels were still mechanically stable and current hot IPA drying techniques were sufficient.
Of course, an obvious question is how complex it is to implement FS in a HNS process and the answer is it is very simple. You simply must deposit a conformal dielectric layer, in this case Silicon Nitride (SIN) and then etch the film back. Wherever the devices are closely spaced the SiN dielectric wall is left in place. Figure 5 illustrates the dielectric wall process.
Figure 5. Dielectric Wall Formation.
In conclusion the FS is a promising extension to HNS offering improved scaling and performance with minimal additional process complexity.
Why should the interface IP category see such a high growth rate until 2025? IP vendors revenues totaled $1068 million in 2020, compared with $872 in 2019. That is 22.4% YoY growth rate and confirm that last year YoY value of 18% was the sign for a long-term growth, as IPnest shows in “Interface IP Survey 2016-2020 & Forecast 2021-2025”, just released.
The answer is data-centric application, hyperscalar, datacenter, storage, wired and wireless networking and emerging AI. All these applications share the need for higher and higher bandwidth, driving the growth for interface protocols like PCIe, Ethernet and SerDes or memory controller IP. Why this need from the industry for higher data bandwidth?
At end-user level, any picture (or movie) is using more advanced protocol every year, 4K than 8k, requiring more data. Social networks are recruiting more users every year (as this is a mark of success), and these users exchange or post more images.
To connect these users and transfer and store these data, professional application like Base stations, Networking, Datacenter, Storage will have to be constantly upgraded. This means using faster Ethernet (800G replacing 400G), moving from PCIe 4 to PCIe 5, and at SoC level DDR4 to DDR5, or implementing HBM protocol.
At system level, we have seen large tech companies (Google, Amazon, Baidu and more) deciding to develop their own datacenter or hyperscalar and searching for better performance by using AI algorithm and implementing AI accelerator, based on GPU, FPGA or ASIC. All these data-centric systems have to be interconnected together using more performant protocols, pushing for adoption of PCIe 5 (32 Gbps) and 112 Gbps PAM4 SerDes (soon 224 Gbps) at replacement rate faster than ever.
At SoC level, the limit of Moore’s law is pushing innovation with SoC disaggregation and the use of chiplet, which may impact functional IP in the near future, complex IP becoming stand-alone IC integrated into MCM to create more performant SoC. New interface protocol are developed to support chiplet, either parallel with forwarded clock (HBM-like running up to 5 GHz) or serial with ultra-short reach (XSR) 112 Gbps SerDes. For interface IP category, this means more sales of expansive IP created from scratch, adding more growth to this healthy business.
The above pictures are showing TSMC revenues by application, in 2017 and 2020. We clearly see that the HPC segment has moved from 17% to 33% of revenues (almost doubling). Moreover, HPC shows the highest growth rate with 39% in 2020. If you consider that TSMC revenues per year was $32B in 2017, growing to $46B in 2020, or 44% growth, revenues generated by HPC have grown by 135% between 2017 and 2020!
Unlike for smartphone segment where a very few actors share the application processor market (less than ten), HPC segment is very dynamic and if we consider networking, storage, datacenter and AI, they are several dozens fabless starting SoC design every year (in the range of 100 to 200 design starts). For IP business, sales of IP license are made at SoC tape-out, and production volume is not the major factor for IP revenues (even if they generate royalties later in the product cycle).
That we see in interface IP revenues 22.7% growth in 2020 is clearly linked with data-centric application explosion, the next step was to calculate the 5 years forecast, as usual made by protocol.
As you can see on the above picture, most of the growth is expected to come from three categories, PCIe, memory controller (DDR) and Ethernet & D2D, exhibiting 5 years CAGR of resp. 24%, 19% and 29%. It should not be surprising as all these protocols are linked with data-centric applications! This forecast call for top 5 interface IP protocol to pass the $2.5B mark in 2025, or 2.5 multiplication factor in 5 years. It’s a 19% CAGR for 2025 to 2020 revenues… Very impressive!
In the last couple of months, the IP industry has reflected this impressive behavior of the interface IP segment, with a succession of IPO and M&A. On May 13, 2021, Alphawave IP, leader of the 112G PAM4 SerDes, has made an IPO on the London LSE market and raised $3 billion, also announcing $190 booking for H1 2021 only. Just to remember, in 1998 ARM raised $1 billion for their IPO.
This came a few days after MorethanIP acquisition by Synopsys for $25 million, helping them to strengthen their Ethernet offer, with 400/800 MAC IP. And before announcement from Rambus (June 16th ) of the acquisition of PLDA (IP vendor for PCIe controller) for $60 million in cash plus stocks and of Analogx (SerDes IP vendor) for $49 million (mix of cash and stock).
This is the 13th version of the survey, started in 2009 when the Interface IP category market was $250 million (in 2020 $1070 million), and we can affirm that the 5 years forecast stayed within +/- 5% error margin! So, when IPnest predict in 2020 that the interface IP category in 2025 will be in the $2500-$2600 range, being the #1 category followed by CPU, DSP, GPU and other IP categories, this affirmation is back-up by experience…
If you’re interested by this “Interface IP Survey” released in June 2021, just contact me:
At Veriest we host VERIFICATION MEETUPS periodically to share verification wisdom. In our virtual meetings we’ve had hundreds of attendants from the US, Europe, Israel, India, and China. Most recently we were able to host a live event in Israel – I want to share feedback from that meeting.
We started with two presentations: Elihai Maicas from NVIDIA discussed “Improved Solutions for Register Solutions”, and Avidan Efody from Intel, outlined a vision for “Post-UVM”, with a double meaning of something that could replace part of UVM functionality, based on Python-based post-processing of the verification database. A lively panel discussion followed. Avidan moderated, with Elihai, Efrat Shneydor (Product Engineer at Cadence), Guy (Verification Manager at a major system house) and an enthusiastic audience.
What are the advantages of UVM?
Avidan asked the panel if they could imagine a world without UVM. What would be the upsides and downsides? Elihai summarized the obvious upsides nicely: the common layer, base classes, etc; without these we’d be reinventing that wheel. Ramp time reduces for each engineer. “Sometimes”, he said, “I find 15-year-old code developed for internal methodologies where the authors left long ago. What am I supposed to do with that?” A base UVM layer at least gives a common starting point above raw Verilog.
Guy added that UVM also gives us a common base for sharing know-how. “I have no sentiments for SV/UVM, but it’s what most of the industry has agreed on and it facilitates problem solving. Without that, how could we or the EDA industry invest in developing solutions to next level common problems?”
Avidan asked Efrat whether vendors really develop tools to solve UVM issues. “Sure”, she answered, “for example RAL was developed by vendors and is actively used today!” She added “I remember the days before UVM. There was always one recurring problem – no design for re-use. Maybe it’s still not ideal but we’re moved forward. People avoid basic mistakes. Stimulus generation is greatly improved, for example through sequences.”
Elihai added another benefit of a common methodology is the availability of VIPs, the fact we can take a USB VIP off-the-shelf, and it works! (This prompted a separate discussion about how hard is to integrate a VIP these days. That will be another blog.)
What are the disadvantages of UVM?
Shimon Cohen, an experienced verification team leader with Microchip jumped up: “SV/UVM is way too complex! Young electrical engineers starting here are in shock! It’s so overwhelming! I prefer to recruit people with C++ and JAVA knowledge rather than hardware background. I don ‘t care if they don’t know what a flip-flop is. SV and UVM are much more like software.”
Avidan remarked on the challenge with standards: Many people must sign-off on any change. Is this stalling innovation in the field? Guy agreed: “The software world”, he compared, “experienced many revolutions, one after the other, constantly innovating, AI, new tools and methodologies, constantly sharing knowledge. If you look at SV/UVM, or more broadly at verification methodology, you see little change – basically the same methodology that was used 10 years ago. Some cosmetic improvements only. It seems the industry has aligned itself to the lowest common denominator.”
Comparisons with the software world
Guy returned to his initial comparison to the software world. They could obsess about C++ and assembler improvements, but instead keep inventing new things! Why can’t we follow the same path in verification?
Guy remembered that “when SV started 10 years ago, there was a sense of innovation, there was excitement. That resulted in the benefits we talked about – ease to switch between projects/companies, VIP development, etc. In recent years, I don’t feel a similar spirit of innovation. On the software side, I see a lot of new ideas and conferences. If you attend an UVM conference 10 years ago and today – I don’t think you’ll find it that much different.”
This is a favorite topic of mine. At the last DVCon Europe conference, I gave a keynote comparing the verification world to the software world. Here, I asked if they thought the deadlock derives from SV/UVM standardization or tools on those standards coming only from the EDA vendors? What is holding us back – standardization or commercialization? Does it matter in the end?
Efrat said that one of the key problems is that verification people don’t share so the only source for advances is the EDA vendors. Someone in the audience suggested that people working in very large companies, are not allowed to share. This is not exactly true. Google – as an example – contributes a lot of open-source software, and even hardware code. Then again, Guy added he worked most of his career in startups, but they were in no hurry to share, either! However, there were at least two speakers at this meetup from large companies who openly contribute their ideas, if not code.
What about open source?
Elihai suggested that maybe the risk in open source is too high. “If a VIP has a bug, it could kill your Tapeout!” However, Shimon said/claimed? That bugs in open source tend to disappear quickly. “I am constantly downloading python applications from the internet, and I never had a problem.” Itai, an engineer who joined Veriest from a SW background added: “In the software world, every question I had, I googled it and in a second, I had an answer. On the hardware side, I may spend two hours searching the net for an answer, and I either find nothing or something that is not related at all, and I need to develop it myself.”
Why is this acceptable in the software world and not in the hardware world? Not sure we got to the bottom of this question.
In general, we believe that standard methodologies in Chip Design have brought and still bring many blessings to our industry. To thrive we need to have full understanding and command of the different features and possibilities. On the other hand, Veriest as a services company is involved in so many different advanced projects and must be open to out-of-the-box thinking to make ourselves more effective and efficient!
We’d like to hear your views on this important topic. Please leave your comments below.
In this article we take an objective view of Virtual Prototyping from the engineering lens and the “quest to find bugs”. In this instance we discuss the avoidance of bugs in terms of architecting complex ASICs to be “correct by design”.
AI Challenges
It is not surprising to find out that other areas of human endeavour, beyond semiconductor design, struggle with complexity, cost and tricky problem solving…
“One of the main problems in the realization and testing of system is the time and costs associated to the iterative process that starts from the conceptual design, the preliminary (approximated) simulations, the realization of a prototype and eventually the modification of the initial design if some of the performance is not satisfactory”.[1]
This excerpt doesn’t come from a paper talking about ASIC design challenges, it is actually referring to design of end-effectors (think robotics) on space exploration vehicles and modules! Design for space, or for other planets, brings nasty challenges like lack of gravity, no atmosphere, radiation and zero-fail requirements; the list is long, but the use of Virtual Prototypes is almost a given.
A fabulous example of a device designed for out-of-this-World conditions is NASA’s rover, Perseverance. Due to the long delays communicating with the rover, all of the on-board systems have to run autonomously starting with the landing control, through control of scientific experiments to navigation control in a hostile environment!
Perseverance is the ultimate autonomous driving system and it’s in use on Mars before we have large numbers of cars using it here on Earth.
Running vehicles autonomously is the next big challenge for the automotive industry – avoiding obstacles, judging conditions and taking critical decisions are what prevents serious accidents happening.
The common thread through both these autonomous systems is control by AI systems[2]. The Perseverance autonomous navigation systems work at speeds far slower than if humans were on board to drive them on the Martian surface and the challenge is to accelerate the AI systems to do more. Back on Earth, Autonomous Driving Systems (level 3 and above) face a similar data “capture-process–decide” challenge; In both cases, much more data is required to perform correctly, including the processing of huge numbers of images and other sensory information.[3]
The challenge for the semiconductor world is to design the AI ASICs that are able to handle the very demanding data processing, performance and algorithmic targets that autonomous tasks require. And the stakes are very high;
A failed chip on Mars means a failed mission, or science experiment, so making sure that AI ASICS are bug free carries a huge premium. On Earth, failures cost lives…
As we have seen with Perseverance, or an autonomous vehicle travelling down Highway 101, a central challenge is how to deal with very large quantities of data coming from an array of sensors and other inputs. The same is also true in martial field (warfare), with important decisions being driven by information about surveillance, reconnaissance and personnel. Utilising this data relies on computational algorithms and underlying compute running at a huge scale.
ASICs are one route to managing the computational and data demands, but they tend to cost vast sums of money, are slow to develop and limited to the one task they are designed to be good at. DARPA and other organisations are turning to Software Defined Hardware, which can be defined as domain-specific programmable and configurable SoCs, optimized for a selected set of applications. In other words, “software-defined hardware” applies the principle of “form follows function” to chip design, such that the desired functionality determines a SoC’s architecture.
Correct-by-design analysis
Not all bugs can be found due to the complexity of modern ASIC designs and the challenges of verification as explained in “The Dilemmas of Hardware Verification”. We need to understand how to avoid bad architecture decisions through better architecture design practices.
We need a correct-by-design approach.
Traditionally, architectural analysis has been carried out using spreadsheets, a predominantly static approach that is highly limited. However, perhaps we should be deploying more dynamic architecture design analysis approaches to enable a far more complete, measurable and robust analysis of design choices?
So, what do we mean by dynamic? Dynamic effects arise from workloads changing over time, or multiple applications sharing the same resources. This can result in dynamic scheduling and pre-emption; many-core systems, leading to multiple initiators, which give rise to arbitration on shared interconnect; dynamic memory access latency due to caches and DDR memories (latency depends on address pattern). Hence, dynamic effects make it difficult to predict performance with static analysis.
In the same way, dynamic residency of workloads on resources leads to dynamic power consumption making it difficult to estimate average and realistic peak power. Dynamic power management (e.g. DVFS) creates a closed control loop: application workload drives resource utilization, which is influenced by the power management. This makes prediction of power and performance even more difficult, as the elements of the loop become interdependent.
Moving from Mars rovers to Earth-bound ASICs, does architecture design analysis using Virtual Prototyping help to avoid hard-to-find hardware and software bugs that emerge late in the development lifecycle? These bugs are costly to find and fix, or really disastrous if they emerge once the product is deployed and in the field!
Virtual Prototyping mitigates downstream problems by solving architectural design bugs early, before any RTL is written.
So why are these techniques less common in the design of ASICs and what are the compelling reasons for considering them, if they are not in use today? AI design is one of the areas where this is changing. The design task is to make “correct” early architectural decisions that avoid failures to meet product requirements (let’s call them architecture design bugs) in silicon.
So, what are Architecture Design Bugs?
digital safety concept electronic computer bug isolated, 3D illustration
Architecture design bugs are one of the most impactful categories of bugs and can lead to end products that miss performance, power or security goals. If bad architecture design choices do not become apparent until significant RTL design has been implemented, the cost of architectural change can be perceived as too great, with significant consequences on the schedule to make radical changes. Instead, these architecture issues are worked-around. Complexity ensues and technical debt accumulates.
You can end up with a fragile and compromised design where the ratio of bugs to lines-of-code is high, and you may never be satisfied that the design is fully robust.
The design goals may be difficult to meet as the RTL is iterated to achieve power and performance targets which could have been correctly addressed at the architectural stage. These late design specification changes are a common root cause of difficult bugs (see “The Origin of Bugs”).
The objective of Virtual Prototyping is to underpin the development of a clean and stable high-level architecture, that has been validated to meet functional, performance and power requirements. Architectural design bugs are avoided early on. This stable high-level design saves time and reduces risk in the latter RTL development stages. Implemented RTL can be benchmarked against this model.
Architecture design warrants validation and verification in the same way as the RTL HW and the SW does, in the effort to eliminate architecture design bugs.
Let’s consider some different classes of architecture design bugs.
Where are HW bugs created, and where are they found?
The following figure shows what a typical hardware design flow looks like in terms of where bugs are created and where they are found. Bugs are generally injected in the initial RTL coding phase, and further bugs are injected downstream as the RTL is refined for bug fixing and performance optimizations. This is often seen as a series of diminishing ripples in the RTL codebase and the bug tracking as the verification transitions through the verification abstraction levels. Some architecture design bugs may be injected in the architecture design phase and may not be found with traditional static spreadsheet based analysis. Non-functional bugs/flaws in the architecture are typically only discovered in the sub-system/system validation stages. Fixing them at this late stage can then cause rework and risk of further bug injection at the unit stages.
These architecture design bugs can be found and eliminated during architecture development by using a Virtual Prototyping based architecture design and validation strategy.
Eliminating bad architecture decisions at this early stage will then reduce performance and power optimization based code churn/bug injection at the sub-system/system stages and the corresponding risk of bugs at the silicon stage. Bug fix cost at this early stage of the development lifecycle is the lowest, with the cost to fix and the impact costs escalating exponentially as you transition through to hardware acceleration and eventually onto prototype silicon. See “The Cost of Bugs”.
Source – Acuerdo and Valytic Consulting
Identify bad decisions…
The following flow-chart visualizes a Virtual Prototyping enabled ASIC development flow, where a set of product requirements lead to an overall system architecture design which can be explored using Virtual Prototyping. This is turn drives the development of the hardware and software specifications. At the architecture level, decisions are made about the hardware/software split; What functionality needs to be delivered in hardware and what functionality should be delivered in system software to achieve the functional, performance and power goals of the product. Different categories of bugs (requirements, architecture/specification, RTL, implementation, software, and even bugs in the VP models) can originate at multiple points throughout this flow.
Bad decisions made at the system architecture design phase can lead to downstream problems in the hardware and software that may be difficult to fix without major disruption to hardware RTL design, or software that has already been written.
Virtual Prototype enabled ASIC development
Source – Acuerdo and Valytic Consulting
In the workflow above, a Virtual Prototype is developed in the early stages in a loop that iterates around the system architecture exploration. The VP for architecture analysis is developed from a combination of TLM library components with appropriate cycle timing (e.g. processors, bus interconnects, memory systems) plus any custom design components that are developed for the target product (e.g. an AI accelerator). System architecture exploration can also drive iteration of product requirements.
Virtual Prototyping can also deliver VP Kits which can be deployed easily to shift-left both system software and application software development. Further, elements of the Virtual Prototype or the TLM library (e.g. fast processor models) can be exploited for hardware verification acceleration and other use cases. Software-driven system validation consumes the system software that has already been validated using the VP Kit. We will discuss these use cases further in a forthcoming article”.
Consequences
Often, development teams will seek to find workarounds just to avoid major re-writes, and this can compromise the quality of both hardware and software. Technical debt accumulates as patches are applied to patches, complexity increases, and design integrity can decrease. This leads to hard-to-find corner-case bugs that you may (or may not) find pre-silicon and pre-production.
If you wait until beta hardware and software availability (fully functional) to validate the system architecture, then you’ve left it too late. You might have to live with the architecture bugs!
Virtual Prototyping is empowering; it facilitates the exploration of designs in terms of function, performance and power, and enables more deterministic decisions on what configuration of the design topology and hardware/software split is going to deliver the optimum solution. In the process, it helps avoid unforeseen or non-obvious problems with the architecture that might present as a Quality-of-Service (QoS), or Denial-of-Service (DoS) issues. You now have a crucial feedback loop between the fast Virtual Prototype model and the architecture design spec. Architecture bugs can be eliminated (avoided!) before they ever make it through to the hardware and software development stages.
Exploring the options
There may be a number of architecture questions that need to be answered in order to arrive at a validated architecture solution.
Solving the architecture up-front, saves time and cost and reduces risk, and leads to successful “Correct by Design” hardware and software development.
Consider some of the architecture variables and questions you might need to review: –
Does the chosen architecture meet the non-functional requirements?
Combinations of CPUs, GPUs or AI accelerators should be selected to balance performance, power and area.
On-chip bus fabric and bus protocols deliver the product performance requirements (in terms of latency and bandwidth)?
Multi-core architectures meet the product performance requirements for the lowest energy consumption?
Caching hierarchy, associated sizes, and algorithms appropriate for the target workloads?
Which memory controller best fits the required latency and bandwidth requirements of the product?
Which interrupt controller offers the right latency for a real-time design?
Architecture best suited to deliver a secure system?
Should team develop key algorithms in software, or map those algorithms to hardware accelerators?
Power architecture that best meets low-power targets for the product?
Software architecture (compilers, system software and application software) required to meet product specification?
Will architecture behave well under conditions of peak-traffic/peak processing loading?
There will be many more….
Architecture sweeping
A design-exploration approach is needed to investigate the matrix of options and analyse the resulting function and performance. This analysis must be able to dynamically observe all aspects of behaviour and performance to achieve full insights into the characteristics of the “architecture-under-test”. For example, this might entail observation of the following: –
Software execution trace
Task tracing for accelerator units such as a DNN component
IP block utilization tracing
Bus throughput tracing (latency, bandwidth, congestion)
DDR utilization levels
Relative power tracing
The architecture designer will be able to utilise all of these analyses to debug and reason about which iterations offer the optimum architecture solutions against the product requirements. There may be some KPIs that will determine the overall best fit such as inference-latency for an AI enabled product, for example. These KPIs can be tracked and tabulated by sweeping across the matrix of selected configuration choices.
Source: Synopsys
The figure above shows an example KPI analysis from this architecture sweeping process, showing how different memory system choices impact runtime, power and energy measurements taken from each set of VP analyses.
Don’t propagate bad decisions…
Virtual Prototyping is well known for its ability to “shift-left” the software development activity by decoupling it from the hardware RTL development. VPs can be further used to speed-up hardware verification environments in simulation, emulation and FPGA which in turn can shift-left the hardware development. However, we hope we have convinced you that architecture choices also need to be validated, and the earlier the better!
The benefit of doing this up-front, before committing to expensive hardware and software development, is that time will be saved downstream, and the reliability and quality of the end-product will be higher; Correct by Design. Bad architectural decisions should not be allowed to propagate beyond the design exploration stage, and Virtual Prototyping is the ideal methodology to do this… especially if planning a trip to Mars.
Dan and Mike are joined by Moshe Zalcberg, CEO of Veriest. Moshe discusses the changing landscape of semiconductor design and the critical enabling role of companies like Veriest. He reviews the complexity increases that we’ve all seen and suggests ways that Veriest can enable the new and pervasive use of semiconductors through innovation and collaboration. Moshe makes some interesting and relevant comparisons between the semiconductor and pharmaceutical industries.
The views, thoughts, and opinions expressed in these podcasts belong solely to the speaker, and not to the speaker’s employer, organization, committee or any other group or individual.
At the 2021 Symposium on VLSI Technology and Circuits in June a short course was held on “Advanced Process and Devices Technology Toward 2nm-CMOS and Emerging Memory”. In this article I will review the first two presentations covering leading edge logic devices. The two presentations are complementary and provide and excellent overview of the likely evolution of logic technology.
CMOS Device Technology for the Next Decade, Jin Cai, TSMC
Gate length (Lg) scaling of planar MOSFETs is limited to approximately 25nm because the single surface gate has poor control of sub surface leakage.
Adding more gates such as in a FinFET where the channel is constrained between three gates yields the ability to scale Lg to approximately 2.5 times the thickness of the channel. FinFETs have evolved from Intel’s initial 22nm process with highly sloped fin walls to todays more vertical walls and TSMC’s high mobility channel FinFET implemented for their 5nm process.
Taller fins increase the effective channel width (Weff), Weff = 2Fh + Fth, where Fh is the fin height and Fth is the fin thickness. Increasing Weff increases drive current for heavily loaded circuits but excessively tall fins waste active power. Straight and thin fins are good for short channel effects but Fw is limited by reduced mobility and increase threshold voltage variability. Implementing a high mobility channel (authors note, SiGe for the pFET fin) in their 5nm technology gave TSMC an ~18% improvement in drive current.
As devices scale down parasitic resistance and capacitance become a problem. Contacted Poly Pitch (CPP) determine standard cell widths (see figure 1) and is made up of Lg, Contact Width (Wc) and Spacer Thickness (Tsp), CPP = Lg + Wc + 2Tsp. Reducing Wc increases parasitic resistance unless process improvements are made to improve the contacts and reducing tsp increases parasitic capacitance unless slower dielectric constant spacers are used.
Figure 1. Standard Call Size.
As the height of a standard cell is reduced the number of fins per device has to be reduced (fin depopulation), see figure 2.
Figure 2. Fin Depopulation.
Fin depopulation reduced cell size increasing logic density and provide higher speed and lower power, but it does reduce drive current.
Transitioning from FinFETs to stacked Horizontal Nanosheets (HNS) enable increased flexibility by varying the sheet width (see figure 3.) and the ability to increase Weff by stacking more sheets.
Figure 3. Flexible Sheet Width.
Adding sheets adds to Weff, Wee = N*2(W+H), where N is the number of sheets, W is the sheet width and H is the sheet height (thickness). Ultimately the number of sheets is limited by the performance of the bottom sheet. The spacing between sheets reduces parasitic resistance and capacitance as it is reduced but must be big enough to get the gate metals and dielectric into the gap. There is a bottom parasitic mesa device under and HNS stack that can be control by implants or a dielectric layer.
In FinFET nFET electron mobility is higher than pFET hole mobility. In HNS the mobility is even more unbalanced with higher electron mobility and lower hole mobility. Hole mobility can be improved by cladding the channel with SiGe or using a Strain Relaxed Buffer but both techniques add process complexity.
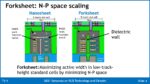
Imec has introduced a concept called a Forksheet (FS) where a dielectric layer is put between the nFET and pFET reducing the n-p spacing resulting in a more compact standard cell, see figure 4.
Figure 4. Forksheet.
Beyond a HNS with FS, there is the Complementary FET (CFET) that stacks the nFET and pFET eliminating the need for horizontal n-p spacing.
Figure 5. CFET.
CFET options include monolithic integration where both nFET and pFET devices are fabricated on the same wafer and sequential integration where the nFET and pFET are fabricated on separate wafers that are then bonded together, both options have multiple challenges that are still being worked on.
Beyond CFET the presenter touched on 3D integration with transistor integrated into the Back End Of Line (BEOL) interconnect. These options require low temperature transistors with polysilicon channels or oxide semiconductors presenting a variety of performance and integration challenges.
In the Front End Of Line (FEOL) options beyond CFETs are being explored such as high mobility materials, Tunnel FETs (TFET), Negative Capacitance FETs (NCFET), Cryogenic CMOS and low dimensional materials.
Low dimensional materials make take the form of nanotubes or 2D Materials, these materials offer even shorter Lg and lower power than HNS but are still in the early research phase. Low dimensional materials also fit into the HNS/CFET approach with the option to stack up many layers.
Nanosheet Device Architecture to Enable CMOS Scaling in 3nm and beyond: Nanosheet, Forksheet and CFET, Naoto Horiguchi, Imec.
This section of the course expanded on the HNS/FS/CFET options discussed in the previous section.
As FinFETs are being scaled to the limits, fins are getting taller, thinner and closer. Fin depopulation is reducing drive current and increasing variability, see figure 6.
Figure 6. FinFET scaling.
The state-of-the-art today is a 6-track cell with 2 fins per device. Moving to single fins and narrower n-p spacing will require new device architectures to drive performance, see figure 7.
Figure 7. 6-Track Cell
To continue CMOS scaling we need to transition from FinFET sot HNS to HNS with FS and then CFETs, see figure 8.
Figure 8. Nanosheet Architectures for CMOS Scaling.
Transitioning from FinFETs to HNS offer several advantages, great Weff, improved short channel effect which means shorter Lg and better design flexibility due to the ability to vary the sheet width, see figure 9.
Figure 9. FinFET to HNS.
The presenter went on to go into detail on HNS processing and some of the challenges and possible solutions. A HNS process is very similar to FinFET processing except for four main modules, see figure 10.
Figure 10. HNS Process Flow.
Although a HNS flow is similar to a FinFET flow the key modules that are different are difficult. The release etch and achieving multiple threshold voltages is particularly difficult. There was a lot of good information on the specifics of the process modules changes required for HNS that is beyond the scope of a review article like this. One thing that wasn’t explicitly discussed is that in order to scale a HNS process to a 5-track cell Buried Power Rails (BPR) are required and that is another difficult process module that is still being developed.
As seen in the previous presentation further scaling of HNS can be achieved by FS. Figure 11 presents a more detailed view of how a dielectric wall shrinks a HNS cell.
The FS process requires the insertion of a dielectric wall to decrease the n-p spacing, figure 12 illustrates the process flow.
Figure 12. Forksheet Process Flow.
Beyond FS, CFET offers zero horizontal n-p spacing by stacking devices. Figure 13. Illustrates the CFET concept.
Figure 13. CFET Concept.
CFETs are particularly interesting for SRAM scaling. SRAM scaling has slowed and is not keeping up with logic scaling. CFET offer the potential to return SRAM scaling to the historical trend, see figure 14.
Figure 14. SRAM Scaling with CFET.
As previously mentioned there are two approaches to CFET fabrication, monolithic and sequential. Figure 15 contrasts the two approaches with pluses and minuses for each.
Figure 15. CFET Fabrication Options.
Conclusion
This review presented some of the key points of the two presentations leading edge logic devices. This is just an overview of the excellent and more detailed information presented in the course. The course also covered interconnect, contacts, and metrology for logic, and emerging memory, 3D memory and DRAM. I highly recommend the short courses.
The successful transition to a new fabrication process from development to high volume manufacturing requires a collective, collaborative effort among process engineers, equipment manufacturers, and especially, chemical suppliers. Of particular importance is the chemistry of the photoresist materials and their interaction with the exposing photons/electrons representing the pattern data for each mask layer.
The transition to high numerical aperture (“high NA”) lithography for future process nodes will entail not only tremendous engineering innovation from the system provider (e.g., ASML), but also advanced development of suitable photoresist materials.
At the recent VLSI 2021 Symposium, James Blackwell from Intel’s Components Research Group provided an extremely insightful look into the selection and optimization of potential photoresists for the upcoming high NA EUV transition.[1]
The clear take away from his talk is that finding a suitable photoresist is still a very active area of research, which must proceed concurrently with the system development (using a EUV source other than a full scanner system). This article summarizes the highlights of the presentation, specifically focusing on the challenges ahead to enable high NA EUV to achieve high volume manufacturing.
Background
A watershed moment in our industry over the past decade was the introduction of multipatterning lithography, to enable continued scaling of design pitch on critical layers. To achieve a pitch less than ~80nm, with 193nm wavelength exposure with immersion (193i), it was necessary to divide the mask data into distinct subsets. Shapes were “colored” with a subset designation – e.g. “A” and “B” mask data for double patterning lithography. Process design kit layout rules were extended to reflect support for the algorithms used to subset the full layer data. Design rule verification functionality was extended to perform “cyclic” checking, to confirm that the data decomposition into resolvable shapes would be successful at the mask house. For example, a cyclic decomposition error is illustrated below.[2]
The full layer patterning was realized with a sequence of “litho-etch” steps for each mask subset – e.g., LE-2, LE-3, and LE-4 designates a process flow for double, triple, and quad patterning, respectively.
Additionally, the mask-to-mask overlay tolerance at each multipatterning layer introduced a new source of process variation. The distance between adjacent wires on the same metal layer, and thus their coupling capacitance, varies with the LE-LE process window.
The evolution of multipatterning also resulted in increased fabrication cost; the trend in “decreasing cost per transistor” guided by Moore’s Law abated. As alluded to above, with continued adoption of multipatterning in successive process nodes, LE-2 evolved to LE-3 and LE-4, further contributing to higher costs, as depicted below.[3]
EUV
Frequent SemiWiki readers are no doubt familiar with the recent evolution of extreme ultraviolet (EUV) lithography systems with a wavelength of 13.5nm, to displace 193i litho. To intercept the rising cost trends of multipatterning, EUV systems have achieved production status, in terms of exposure throughput (wafers per hour), exposure intensity, and system uptime. As depicted in the figure above, active R&D work is underway to release a 2nd generation EUV system. This system will incorporate a higher numeric aperture (NA = 0.55) in the lensing path, enabling finer pitch resolution, and again recalibrating the cost per layer trend from EUV multipatterning with first generation NA=0.33 equipment.
EUV systems are a marvel of engineering, to be sure. Yet, an often underappreciated facet of the EUV litho evolution is the corresponding development efforts for a corresponding photoresist material.
Photoresist Basics
Briefly, selective exposure of a photoresist-coated wafer to high-energy photons (or high-energy electrons) results in a change in the chemical bonding configuration of the original material. For a (positive) organic photoresist polymer, the incident photon results in a “deprotection” chemical reaction; a subsequent step immerses the exposed wafer into a developer, which dissolves the deprotected polymer. While the dimensional targets are tighter with each new process node, the fundamental goals haven’t really changed:
high absorbance and selectivity to the photon wavelength/energy (E=h*f)
goal is a lower photon dose (mJ/cm**2), and greater exposure latitude
high contrast
low scattering of the chemical reaction
high developer selectivity to chemical configuration differences
goal is to reduce the “line edge roughness” (LER) of the developed image
low viscosity
ease of photoresist application; a thin, uniform PR layer (after spin-coat and pre-bake) is needed, as the depth-of-focus for EUV exposure is very small
good adherence to the wafer substrate surface
ease of photoresist removal, after the etch step
For recent process nodes, chemically-amplified resist (CAR) materials have been introduced. The CAR composition introduces a “photoacid generator” (PAG) to the resist. In simplest terms, a photoacid is a molecule which releases protons (H+) upon light absorption, called photodissociation. After exposure, a subsequent heating step releases the acid, which acts as a catalyst to the polymer fragmentation.
The acid is not consumed in the deprotection, and continues to diffuse through the resist to provide (hundreds of) reactions, thus amplifying the impact of the photon energy dose. An inhibitor (or “quencher”) compound is also incorporated into the CAR, attached to the resist polymer chain. This acid-soluble inhibitor mitigates the acid diffusion and improves the dissolution contrast, reducing the resulting LER.
The thin photoresist film thickness associated with the low depth-of-focus for EUV litho, combined with the goal of a reduced dose for improved system throughput/uptime, implies that EUV exposure is a stochastic process, with (random) variation in the incident photons/unit area density.
Non-uniformities in density of the polymer-CAG-inhibitor components are another source of variation. Another difficult tradeoff with the transition to thin organic photoresist films is the need to be sufficiently robust to the post-patterning etch (or implant) process step. Thicker PR layers would be more robust to the subsequent step, but would be more difficult to resolve at lower exposure dose. A high aspect ratio developed PR film is subject to “pattern collapse”, as illustrated below. [4]
The surface tension of the developer solution would collapse the spacing between adjacent, tall PR lines.
As a result, process engineers are focused on improved EUV metrology to uncover lithography defect mechanisms – e.g., incompletely developed lines and vias. Another indication of the strong interdependencies in the EUV evolution is the semiconductor equipment provider focus on fast, in-line lithography inspection.
Resists for High NA EUV
The data James presented were the result of a close collaboration between Intel, photoresist suppliers, academic institutions, and research labs. The figure below illustrates the targeted transition in photolithographic pitch enabled by high NA EUV, and the requirement for thinner resist coating for the reduced depth-of-focus.
Prior to the availability of high NA EUV systems, how does a materials engineer evaluate potential photoresist materials? James described a system that Intel developed specifically for photoresist research, as illustrated below.
A EUV source is connected to a wafer chamber. James highlighted the Fourier Transform Infrared Spectroscopy (FTIR) detection features added to the system. (FTIR uses the absorption of a material across an infrared spectrum exposure to provide an analysis of a material; it can provide real-time data on the concentration of reactants and products of a chemical reaction.) This system has enabled Intel to gain insights into the photoresist response to EUV exposure.
A unique facet of EUV photoresist R&D is the potential to use metal-oxide resist chemistry, as an alternative to the traditional polymer materials. These “inorganic” resists have high EUV absorptivity, and high etch resistance for subsequent processing. The figure below provides a simplified comparison of the metal-oxide versus organic resist chemistry.[5]
James described one option for a metal-oxide resist, utilizing Hf-O-C. (Oxides of Ti and Zr are also actively being investigated in the industry.) The chemical reaction sequence for the resist is depicted below – the FTIR analysis confirmed the presence of CO2 during the reaction, and the cross-linking of Hf-O-C clusters as the result.
Note the cross-linking after exposure differs from photodissociation described earlier, where the solubility “switch” is now associated with a negative resist.
James also described results with organic CAR resists for EUV exposure. An example of proposed resist (plus PAG plus inhibitor) chemistry, and a corresponding contrast versus dose curve are shown below.
As mentioned earlier, non-uniformity of the resist composition contributes to increased variation in the developed image. James described an experiment the Intel team had pursued to evaluate the homogeneity of the resist, as illustrated below.
In this case, secondary ion mass spectroscopy (SIMS) was used to analyze the thin film composition over a focused incident ion beam size, and aggregating a large number of samples to assess the PR heterogeneity.
In James’ words, “This SIMS method provided data to guide us to chemical changes that led to improved patterning uniformity. Better analytical methods are required to improve EUV resist design for the challenges introduced by high NA EUV – such as SIMS and FTIR for metal-oxide resists. And, close collaboration with suppliers is critical.”
Summary
The introduction of high NA EUV systems will be a key step in addressing the cost concerns associated with EUV multipatterning. Yet, as this Intel presentation at the VLSI Symposium 2021 illustrates, there clearly remains a considerable amount of development (and qualification) ahead to meet the corresponding photoresist materials requirements, especially addressing the tradeoffs between organic versus metal-oxide materials. It will be very interesting to see how the concurrent and strongly interdependent lithographic system and photoresist technologies evolve.
-chipguy
References
[1] J. Blackwell, “Mechanism and Materials for Advanced Patterning”, VLSI Symposium 2021, Workshop 4.
This is a story of contrasts and counter-intuitive results. Perforce recently published a white paper discussing enterprise scalability – what it takes, why it’s important and what can get in the way. The discussion will shake up some long-held notions regarding effective project management. The results can be significant, so it’s worth a look. Beyond the white paper, there is also a blog where you can learn more. Links are coming, but first let’s look at why achieving scalability means no more silos.
We Always Did It This Way
Managing tasks with a project-centric view is a natural way to keep track of things. Often, a new project starts by loading information into a requirements management tool. Bug tracking and design management tool are typically deployed in the early stages of a project as well. The whole process seems natural if you consider yourself working on one project at a time. Items like cost, resources, and timelines are also typically tracked in most enterprises on a project basis.
Projects are typically isolated from one another with this approach and that’s where the problems start.
What’s the Problem?
Because projects are isolated from one another, project “silos”, or local data repositories develop. These silos are typically not integrated with other project silos, so enterprise scalability becomes difficult. So does collaboration. The lack of integration also erodes the ability to perform traceability. Let’s examine a few of these challenges in more detail.
Most projects consist of a lot of IP reuse, so there is typically a need to access IPs and blocks from other projects. Lacking a central IP management system, this access is typically accomplished by linking to IPs and blocks using mechanisms like Git “submodules” or Subversion “externals”. Most project-centric data management tools support these functions, and the approach often works.
Or does it?
While this approach seems effective at first glance, challenges for the project and IT support teams can develop. Ad-hoc, peer-to-peer, untracked dependencies have many negative consequences. With each new project, a new design management server gets instantiated. These servers typically persist for a long time since no one wants to remove or delete the server, even after the project is finished. Fear of unknown consequences kicks in.
To make matters worse, many projects spawn other projects and can linger on for years, even decades. After a while, enterprises can have hundreds to thousands of servers running. It’s quite difficult for IT to characterize the impact and importance of any given server. More fear of unknown consequences.
Let’s stay with the IT challenges for a moment. Upgrading servers, performing security patches, and managing the hardware can all take days to weeks. Downtime creates a lot of stress. In the white paper, Perforce reported that one medium-sized customer commented that they had simply given up on updating their servers when the number hit 300 and eventually decided to scrap the system altogether.
You should start to see the problem with what seems like a perfectly reasonable approach to project management. The white paper goes on to discuss many more shortcomings with the typical approach. I encourage you to get your copy and read the discussion first-hand. A link is coming. To whet your appetite, here are some of the topics that are discussed:
Tracking complex project dependencies is difficult when there is no big picture
Collaboration becomes challenging – lots of interdependent permissions to manage
Licensing is hard to keep track of, potentially buying IPs the organization already owns or using IPs in applications that are not allowed
Issue tracking has limited impact – what other projects will see that bug?
Export control – no one wants to be on the wrong side of these rule
You should start to see the pitfalls of a perfectly reasonable approach to project management.
What Should You Do?
In a nutshell, break down your project silos. Adopting an IP-centric management approach addresses the headaches cited above and results in superior enterprise scalability. If your company will ever work on more than one project, you need to consider these strategies. The white paper outlines the benefits and suggests a way forward. You can even connect with an expert to discuss your options. You can get your copy of the white paper here. You can also learn more from a recent blog posted by Perforce here. Perforce has studied this problem for quite some time, and they bring a lot to the table. You can learn more about what they’re up to in SemiWiki’s coverage here. Now you know why achieving scalability means no more silos.