Siemens EDA is clearly on a mission to help verifiers get more out of their tools and methodologies. Recently they published a white paper on UVM polymorphism. Now they have followed with a paper on using UVM Connect, re-introducing how to connect between SystemC and SystemVerilog. I’m often mystified by seemingly overlapping or adjacent efforts between verification capabilities and standards, here in support of co-simulation. My contribution in this article (I hope) is to resolve my own confusion and to answer why this problem is important. I’ll leave the Siemens EDA white paper to handle the details.
Groping through the fog
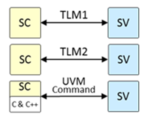
UVM Connect sounds like it would be a feature of UVM or UVM-SystemC, right? Wrong. UVM Connect is an independent open-source UVM-based library from Siemens EDA, introduced in 2012, enabling TLM communication between UVM/SystemVerilog and SystemC. Conversely, the UVM-SystemC Library 1.0-beta4 was released very recently. However, UVM-SystemC does not support language mixing (as of the current beta release). On the other hand, Siemens EDA is very clear that UVM Connect will continue to be valuable even in the presence of UVM SystemC.
Like I said, confusing. There are areas of apparent overlap, but maybe that overlap isn’t important. UVM Connect is an extension to the UVM standard, invented long before UVM-SystemC, to solve a real problem. Will that solution continue to be relevant? Based on the Siemens-EDA white paper it seems the answer is yes, whatever may happen to UVM-SystemC. Maybe UVM and UVM-SystemC will eventually settle into one standard. In which case I would expect the functionality of UVM Connect to be absorbed in some manner.
Why connect SystemC and SystemVerilog?
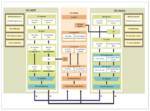
Architectural designers work in SystemC (or C/C++). Implementation designers work in Verilog – SystemVerilog if they are designing testbenches. How do they check/debug the implementation testbench? Ideally by running the architectural model under that testbench. How do they check the implementation model matches the architectural model? Through co-simulation, requiring that they run and compare the SystemC model and the implementation model under the UVM testbench. Both methods can benefit from UVM Connect, connecting the SystemC model to the UVM/SystemVerilog environment and vice-versa.
Equally, having that connection allows verification to use both RTL-based and SystemC-based VIP, expanding and accelerating testbench development. Also some might argue this capability enables UVM to stretch up system level verification. Allowing constrained random tests generated in UVM to be applied to SystemC models. Today, I think that is more of a PSS domain, but the UVM Connect approach certainly works in principle.
Why not use DPI?
Isn’t this getting a little too complicated? SystemVerilog provides a Direct Programing interface (DPI). DPI offers a standard way to connect between SV and C++. Since SystemC is C++, a solution exists; why add another solution? My guess is that the DPI approach is a bit too low level for many of these applications and solutions will invariably be non-portable. In contrast, transaction level modeling (TLM) is a well-established paradigm for handling data exchange between different domains. SystemC is intrinsically TLM-based and UVM provides TLM communication interfaces. UVM Connect simply formalizes this connection in a nice, easy to use way.
My takeaway? UVM Connect is a practical way to connect SystemC models into a UVM testbench in support of implementation verification. Certainly much easier than DPI. More ambitious goals to blend UVM with SystemC and perhaps SystemVerilog may be the long term goal but are not an answer to today’s needs. You can learn more about UVM Connect HERE.