
Current technology news is filled with talk of many edge applications moving processing from the cloud to the edge. One of the presentations at the recently concluded Linley Group Fall Processor Conference was about AI moving from the cloud to the edge. Rightly so, there were several sessions dedicated to discussing AI and edge processing software and hardware solutions. One of the presentations within the Edge IP session was titled “High-Performance Natural Language Processing in Constrained Embedded Systems.” The talk was given by Jamie Campbell, software engineering manager at Synopsys.
While the bulk of data nowadays is generated at the edge, most of it is sent to the cloud for processing. Once the data is processed, applicable commands are sent back to the edge devices for implementing the applicable action. But that is changing fast. Within a few years, a majority of the data is expected to be processed at the edge itself. The drivers for this move are reduced latency, real-time response requirement, data security concerns, communication bandwidth availability/cost concerns, etc., The applications demanding this are natural language processing (NLP), RADAR/LiDAR, Sensor Fusion and IoT. This is the backdrop for Jamie’s talk which focuses on NLP in embedded systems. He makes a case for how NLP can be efficiently and easily implemented in edge-based embedded systems. The following includes what I gathered from this Synopsys presentation at the conference.
Jamie starts off by introducing NLP as a type of artificial intelligence which gives machines the ability to understand and respond to text or voice. And he classifies natural language understanding (NLU) as a subtopic of NLP which is focused on understand the meaning of text. The focus of his presentation is to showcase how an NLP application can be implemented within an embedded system.
Embedded System Challenges
As fast as the market for edge processing is growing, the performance, power and cost requirements of these applications are also getting increasingly demanding. Embedded systems within edge devices handle specific tasks, balancing accuracy of results at power/performance/area efficiencies. The challenge is to select algorithms appropriate for implementing those tasks, execute within the constraints of the embedded systems and still deliver the performance and accuracy needed. Choosing the optimal execution models and implementation hardware is key, whether it is an NLP application or any other application within embedded systems.
Demonstration of NLP Implementation
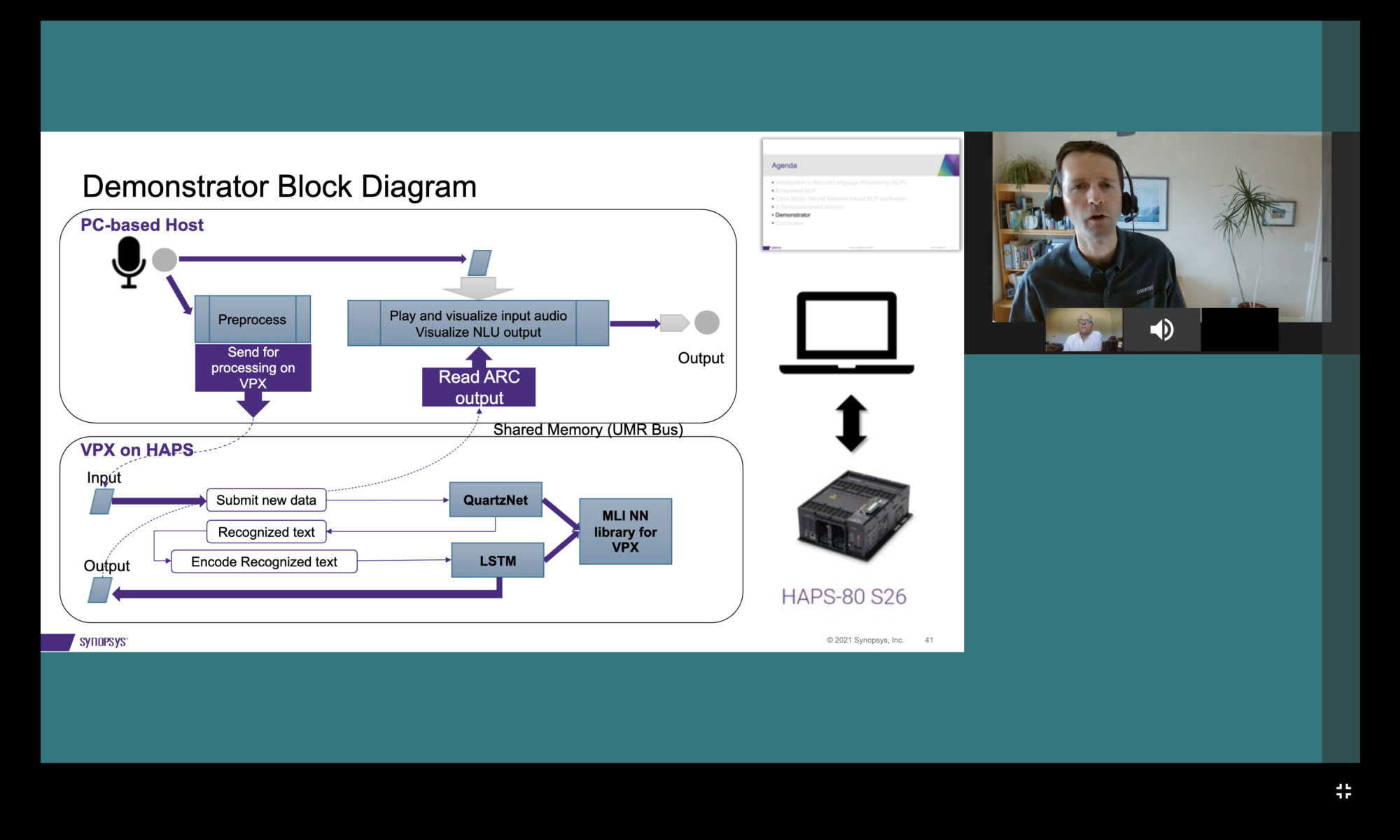
Jamie explains the project that they embarked on at Synopsys is to demonstrate that a useful NLP system can be implemented in a power constrained, low-compute-capacity environment. The use case they chose is an automotive navigation application that can be operated through natural language commands. The goal is to understand queries such as “How far is it from suburbs to city center” and “is road from city center to suburbs icy.” The expected output from the application are two things: Intent and Slots. Intent defines what is needed to execute the query. Slots are qualifiers that augment the Intent. In the case of the two sample queries stated above, the intent is “Get Distance” and the slots are the “Waypoints”. The application is to extract intent and slots from the text output derived from automatic speech recognition (ASR).
The demonstration system uses a 3-step process for the NLP implementation. The three steps are
- Audio feature extraction
- Automatic Speech Recognition (ASR)
- Intent and Slots Recognition
Selecting the Models
For the audio feature extraction, the widely used voice recognition algorithm (MFCC feature extraction technique) was chosen.
For the ASR and conversion to text, the QuartzNet ASR Model was chosen as it requires a lot less memory (~20MB) than many of the other models considered. It delivers a good Word Error Rate (WER) and it does not require a language model to augment the processing.

For the intent and slots which is the NLU step, a lightweight LSTM encoder-decoder model was chosen.
Selecting the Libraries and Hardware
While there are many processors to choose from, the Synopsys VPX processor family was selected for use in the embedded NLP demonstration project. The VPX family implements a next-generation DSP architecture optimized for a data centric world and is well suited for NLP use cases. An earlier blog covers lots of details of the functionality and features of the VPX processor family. Following is an excerpt from that blog to explain the choice of the VPX processor for this use case demonstration project.
“Earlier this year, Synopsys announced an expansion of its DesignWare® ARC® Processor IP portfolio with new 128-bit ARC VPX2 and 256-bit ARC VPX3 DSP Processors targeting low-power embedded SoCs. The announcement was about their VPX DSP family of processors for Language processing, Radar/LiDAR, Sensor Fusion and High-end IoT applications. In 2019, the company had launched a 512-bit ARC VPX5 DSP processor for high-performance signal processing SoCs. The ARC VPX processors are supported by the Synopsys ARC MetaWare Development Toolkit, which provides a vector length-agnostic (VLA) software programming model. From a programming perspective, the vector length is identified as “n” and the value for n is specified in a define statement. The MetaWare compiler does the mapping and picks the right set of software libraries for compilation. The compiler also provides an auto-vectorization feature which transforms sequential code into vector operations for maximum throughput.
In combination with the DSP, machine learning and linear algebra function software libraries, the MetaWare Development Toolkit delivers a comprehensive programming environment.”
Implementation
For convenience, Synopsys uses a PC-based host along with a HAPS® FPGA platform for implementing the NLP-based automotive navigation demonstration. All of the processing happens on the HAPS platform where the VPX5 processor is implemented. The demonstration shows that real-time performance is achieved on a 30MHz FPGA system. If this use case were to be implemented with an ASIC, a VPX2 processor can easily meet the performance requirements. And with the VLA programming model supported through the MetaWare Development Toolkit, customers can easily migrate from a VPX5 to a VPX2 implementation.

Conclusion
Migrating an NLP/NLU application from a powerful cloud server environment to a standalone, deeply-embedded system is possible without sacrificing real-time performance and without requiring lot of memory resources. The choice of the neural network models selected and the hardware chosen to implement the solution play a big role in successful migration to the edge. To learn more about the VPX DSP processors, you can visit the product page.
Also read:
Lecture Series: Designing a Time Interleaved ADC for 5G Automotive Applications
Synopsys’ ARC® DSP IP for Low-Power Embedded Applications
Synopsys’ Complete 800G Ethernet Solutions
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.