
Frequent Semiwiki readers are well aware of the industry momentum behind machine learning applications. New opportunities are emerging at a rapid pace. High-level programming language semantics and compilers to capture and simulate neural network models have been developed to enhance developer productivity (link). Researchers are pursuing various hardware implementations to accelerate throughput of both the dataset training and subsequent inference steps. These hardware projects include: a processor architecture for software-based execution of neural network models (CPU- and GPU-based); an ASIC specifically developed for ML applications (e.g., a TPU), or deploying commercial field-programmable logic arrays.
To date, however, the main production-level ML applications have been exercised on datacenter-class resources. The effective throughput is derived from evaluating the NN model on a batch of input samples, to compensate for the delays in loading the NN layer weights and activation functions from memory. Yet, the data is generated at the edge, and the connectivity bandwidth, latency, and power consumption to communicate with the central processing datacenter for inference evaluation simply does not scale. Thus, the R&D focus is shifting to innovations required in the (distributed) edge computing architecture.
The forecasts for the edge computing market are extremely robust – e.g., 35%+ CAGR, TAM exceeding $30B in 5 years. The application areas being pursued are diverse. (Although edge computing is often associated with the Internet of Things, I’ll stick with edge computing in this article – several of the application examples given below are not usually associated with the IoT.)
The most publicized edge computing AI activity is certainly the development work on autonomous vehicles. Another fast-growing ML area is in the field of factory automation and robotics. There are applications where a human operator is currently glued to a monitor, where machine learning technology can accelerate and alleviate the task of classification. Increasingly, video surveillance technology will incorporate more sophisticated ML inferencing computation. The detection of an attempted network intrusion security breach will also expand the adoption of ML decision support.[1]
An interesting area that I recently read about is the opportunity to provide emergency call centers and responders with more accurate information. Analysis and classification of various patient inputs (e.g., breathing, voice patterns) will improve the triage steps immediately pursued. In these examples, note that the primary characteristic is that the inferencing throughput must be optimized for batch = 1.
Perhaps the best indication of the tremendous growth and interest in edge computing for AI applications is the introduction of an industry conference specific to the topic – the Edge AI Summit – recently held in San Francisco. One of the presentations at the conference was from the team at Flex Logix, who provided details of their NMAX embedded FPGA IP, optimized for edge AI applications.
Last month, the Flex Logix team shared an overview of NMAX with me (link). Recently, I met with the team again to review the details of their Edge AI Summit presentation.
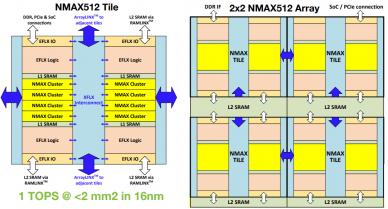
NMAX is a field-programmable logic architecture specifically developed for edge AI (batch = 1). The NMAX “tile” building block for embedded IP integration consists of:
- MAC logic (64 8-bit MAC’s in each cluster, 8 clusters per tile)
From the detailed (floating point-based) training weights, the NMAX edge AI MAC utilizes a scaled int8 implementation, with minimal loss in classification accuracy.
- traditional programmable logic
The activation function calculations for each neural network layer are mapped to this EFLX logic. The state machine control for layer-by-layer evaluation and NN model reconfiguration sequencing is also mapped to this logic.
- internal L1 SRAM
The L1 SRAM stores the node weights – more on that shortly.
- connectivity to embedded L2 SRAM
The composite NMAX tile array can be integrated with a range of L2 SRAM sizes (link). The L2 stores NN layer data values while the tiles are being reconfigured for successive layers. As will be discussed shortly, developers will optimize the tile array and SRAM configuration for their NN model.
- high embedded IP I/O pin count for external connectivity
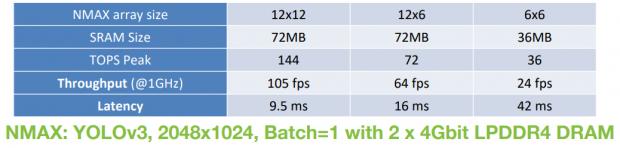
The goal of the NMAX implementation for edge AI is to minimize the number of (and latency to) external DRAM, to retrieve the layer configuration data, weights, and store intermediate results. Real-time NN object classification examples provided in the Edge AI Summit presentation illustrate images/second classification results on the YOLOv3 benchmark using only 2 LPDDR4 DRAM modules, achieving 24 fps with a 6×6 tile array plus 36MB L2 SRAM @ 1GHz. (YOLOv3 is a demanding image classification benchmark – i.e., utilizing >100 layers, >60M weights, requiring 800B calculations/image.)
- compiler support, from a NN model description to full physical eFPGA programming
The figure below illustrates the functionality of the NMAX compiler. The user provides the NN model (e.g., TensorFlow, Caffe), and the proposed tile array plus SRAM topology.
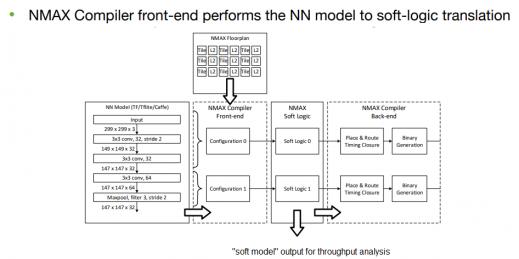
The intermediate compiler output provides the allocation and sequencing of NN model layers to the hardware in the tiles, allowing the user to quickly optimize the area versus throughput tradeoff. The final compiler output data provide the physical programmable logic assignment and interconnect implementation throughout the tile array.
Specifically, the NMAX compiler addresses NN throughput using several unique algorithms. Cheng Wang, Senior VP of Engineering at Flex Logix, indicated that there are features to provide an optimal assignment of layer nodes to the tiles, as well as overlapping of model reconfiguration steps. For example, while a layer is executing, the weights for the next sequence of nodes to be configured are pulled from L2 SRAM (or external DRAM) into L1 memory. Once the next logic reconfiguration is complete, the corresponding set of node weights are transferred to L0 inside the tile MAC to execute.
Geoff Tate, Flex Logix CEO, indicated that his discussions with Edge AI Summit participants showed great interest in larger NMAX configurations, able to contain multiple NN layers in the tile array, executing in a direct pipeline without the latency of reconfiguring the tile logic and weights for successive layers.
FPGA logic offers a unique hardware alternative for ML applications, with improved performance over software-centric architectures. For the transition to ML inference at the edge, embedded FPGA IP is an excellent fit, as long as the following characteristics are available:
- optimized for the high MAC demand
- integrated with a significant capacity of L2 SRAM
- wide connectivity to L2 and external DRAM to minimize latency to load new network input data and layer configuration information
- expandable to allow optimization of area, power, and computational throughput (especially the ability to represent multiple network layers without logic reconfiguration)
The NMAX architecture from the Flex Logix team strives to meet these requirements for edge AI applications (link).
-chipguy
References
[1]Xin, Y., et al., “Machine Learning and Deep Learning Methods for Cybersecurity”, IEEE Access, Volume 6, p. 35365-35381, 2018.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.