
Machine learning applications in data centers (or “the cloud”) have pervasively changed our environment. Advances in speech recognition and natural language understanding have enabled personal assistants to augment our daily lifestyle. Image classification and object recognition techniques enrich our social media experience, and offer significant enhancements in medical diagnosis and treatment. These applications are typically based upon a deep neural network (DNN) architecture. DNN technology has been evolving since the origins of artificial intelligence as a field of computer science research, but has only taken off recently due to the improved computational throughput, optimized silicon hardware, and available software development kits (and significant financial investment, as well).
Although datacenter-based ML applications will no doubt continue to grow, an increasing focus is being applied to ML architectures optimized for “edge” devices. There are stringent requirements for ML at the edge – e.g., real-time throughput, power efficiency, and cost are critical constraints.
I recently spoke with Geoff Tate, CEO at Flex Logix Technologies, for his insights on ML opportunities at the edge, and specifically, a new product emphasis that FlexLogix is undertaking. First, a quick background on DNN’s.
Background
A “deep” neural network consists of multiple “layers” of nodes. At each node, a vector set of inputs is provided to a computational engine. The output of each node is further refined by a (potentially non-linear) activation function calculation, which is then forwarded to the nodes in the next layer. The final layer provides the DNN decision from the original input set – i.e., a “classification” result of an input image to a reference set of objects.
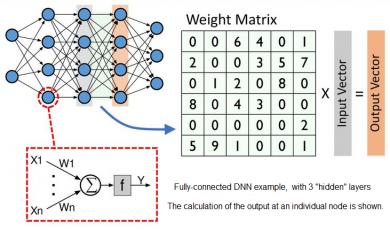
Figure 1. Illustration of a simple DNN, with 3 “hidden layers”. The computation at each layer is a matrix multiplication of the input vector and a matrix of weights.
Numerous DNN topologies are used in practice – the figure above depicts a simple, fully-connected multi-layer 2D design. (More complex “3D” topologies and implementations with feedback connections in the hidden layers are often used, which are optimal for specific types of inputs.)
Each node in the DNN above performs several computations, as shown in the figure below. At each node in the layer, a set of weights are multiplied against the input value, then summed – i.e., a “multiply-accumulate” (MAC) calculation. An (optional) bias value may be incorporated into the sum at each node. The MAC output is input to a normalizing “activation” function, which may also incorporate specific parameter values – activation function examples are illustrated below.
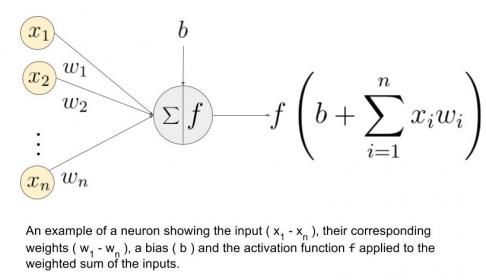
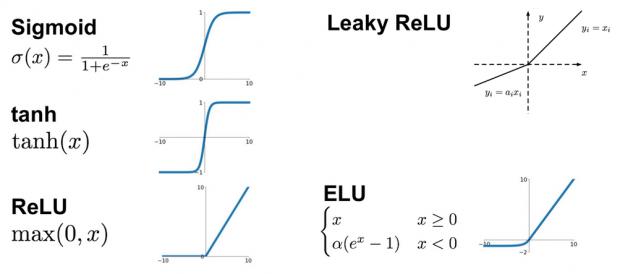
Figure 2. Expanded detail of the calculation at each node in a layer, and some examples of activation functions.
During the DNN training phase, a reference set of inputs is applied. The selection of the initial weights, biases, and activation parameters at each node is an active area of research, to optimize the training time. (The simplest method would be to pick values at random from a normalized distribution.) The input reference set proceeds throughforward evaluation and the DNN result compared to the expected output.
An error difference is calculated at the output layer. A backwards optimization phase is then performed, evaluating an error gradient dependence for the network parameters. Internal DNN values are then adjusted, and another forward evaluation pass performed. This training optimization iterates until the DNN classification results demonstrate acceptable accuracy on the input reference set.
The DNN values from training are subsequently used as part of the production inference engine, to which user data is now the input.
DNN in the Data Center
The initial DNN (training and inference) implementations in the datacenter utilized traditional von Neumann CPU and (DRAM) memory resources to perform the MAC and activation calculations. The DRAM bandwidth to the CPU core is typically the throughput bottleneck.
A transition to GPU-based cores for DNN calculation was then pursued, to leverage the SIMD dot product MAC calculations prevalent in GPU image processing. GPU’s have a drastically different architecture, with very wide internal vector datapaths – e.g., ~1024 bits wide. As a result, to improve core resource efficiency, a “batch” of inputs is evaluated concurrently – e.g., 32b floating-point DNN parameter values could be concatenated into a wide vector to evaluate a batch size of 32 inputs in parallel through the DNN layers. Yet, the local memory associated with each GPU core is relatively small (KB’s). Again, the (GDDR) memory bandwidth is a DNN performance-limiting factor.
New chip architectures are being aggressively pursued for ML applications – e.g., Google’s Tensor Processing Unit (TPU). And, due to the intense interest in the growing base of ML applications, numerous chip start-ups have recently received (initial round) VC funding – see the figure below.
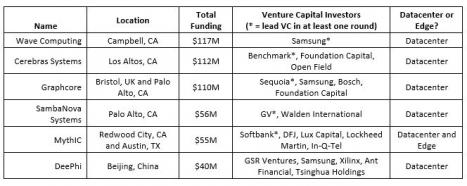
Figure 3. Examples of ML hardware startups (from [1]).
Additionally, cloud service providers are deploying FPGA hardware to offer effective, easily-reconfigurable DNN capabilities. [2]
DNN’s using conventional CPU and GPU hardware architectures are throttled by the access bandwidth to retrieve the weights and biases for each layer evaluation. Training presents an additional data constraint as these parameter values are required to compute both the forward evaluation and the backward optimization error gradients, as well. As an example, the ResNet-50 DNN is commonly used as a reference benchmark for image classification, a complex (3D) 50-layer convolutional network topology. A forward pass evaluation utilizes ~26M weights. [3] Depending upon the data precision of these parameters, the memory bandwidth required to access these values for use in a layer computation is very high.
ML Applications at the Edge
My conversation with Geoff at Flex Logix was very enlightening. First, he shared some of the characteristics of edge applications.
“An ML application will typically pursue DNN training at the datacenter, and then transfer the DNN parameters to edge hardware for inference.”
“Often, a DNN hardware implementation quotes a peak throughput, in trillions of operations per second (TOPS), and a related power efficiency (TOPS/W). Yet, it is important to analyze what memory bandwidth and batch evaluation assumptions are used to calculate that throughput.”
“Edge customers will typically be utilizing (sensor) input data corresponding to ‘batch_size = 1’. Maybe a batch size of 2 or 4 is applicable, say if there are multiple cameras providing video frames per second input. The datacenter architectures that merge parallel input sets into large batch size DNN evaluations to optimize MAC efficiency just don’t apply at the inference edge.”
“High batch count increases overall classification latency, as well, as the parallel input set is being merged – that’s of little consequence for typical datacenter applications, but additional latency is not appropriate at the edge.”
I asked Geoff, “How is Flex Logix approaching this opportunity at the edge? What elements of the existing embedded FPGA technology are applicable?”
Geoff replied, “We have announced a new product initiative, NMAX. This architecture builds upon many of the existing features of our embedded FPGA, specifically:
- a tile-based building block that is readily arrayed into an (m X n) configuration
- a combination of logic LUT cell and MAC engines in a DSP-centric tile
- a method for optimal embedding of SRAM macros of varying size between tiles (link)
- a rich set of external connectivity options when embedded within an SoC design
A block diagram of a single “NMAX512” tile is illustrated below.
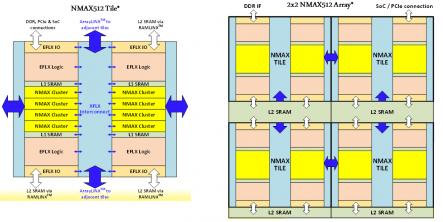
Figure 4. An architectural block diagram of the NMAX512 DNN tile, and an array of tiles depicting the L2-level SRAM between tiles.
Each tile contains 8 NMAX clusters. Each cluster contains 64 MAC’s using an 8b x 8b parameter data width (with options for 16b x 16b), with a 32b accumulate. There is a total of 512 MAC’s per tile. The programmable EFLX logic LUT’s perform the activation functions for the DNN layer. The weight and bias values for the layer are accessed from the local (L1) SRAM within the tile.
An embedded (L2) SRAM between tiles stores the intermediate DNN results and parameter values for successive layer calculations. New values are loaded into the L2 SRAM in the background during forward evaluation. The required data bandwidth for system DRAM memory is reduced significantly.
Geoff added, “The time to reconfigure the NMAX tile with new DNN layer with new DLL layer data (from L2) is very fast, on the order of 100’s of nsec.”
“How is the NMAX tile implementation for a DNN developed?”, I inquired.
Geoff answered,“ML developers utilize the familiar TensorFlow or Caffe languages to define their DNN topology. We will be releasing a new NMAX implementation flow. Users provide their TF or Caffe model, and the NMAX compiler fully maps the data and logic operations to the MAC clusters and reconfigurable EFLX LUT logic. All the sequencing of DNN layer evaluation is mapped automatically. The physical LUT placement and logic switch routing configuration is also automatic, as with a conventional embedded FPGA.”
Geoff continued, “Our preliminary performance models indicate we will be able to achieve ~1GHz clocking (TSMC 16FFC), or roughly ~1 TOPS throughput per tile(with LPDDR4 DRAM, L2 SRAM size optimized for the DNN). The distributed L2 SRAM helps maintain a very high MAC and activation function utilization.”
“Speaking of performance modeling, do you have NMAX benchmark data?”, I wondered.
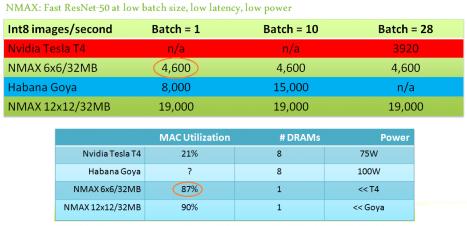
Geoff replied, “We prepared the following data for NMAX compared to other architectures, such as the Nvidia Tesla T4, for the ResNet-50 DNN benchmark with Int8 parameters. Note that the NMAX architecture enables a wide span of tiled array sizes, with corresponding throughput scaling for the batch_size = (1, 2, 4) of greatest interest to edge customers. The initial MAC utilization and total power dissipation is much improved over other architectures, as well.”
Finally, I asked, “What is the NMAX deployment schedule?”
Geoff answered, “We are starting to engage partners now, in terms of potential NMAX sizes of interest. Our engineering team will be finalizing IP area/performance/power specs in 1H2019, as well as finalizing the NMAX compiler. A tapeout release with a specific tile and SRAM configuration will occur in 2H2019, to provide evaluation boards to customers.”
There is clearly a lot of activity (and VC investment) pursuing optimized DNN hardware architectures for datacenter applications. There is certainly also a large market for (embedded IP or discrete) hardware focused on the power/perf/cost constraints of the low batch-size ML applications at the edge. Flex Logix is leveraging their expertise in reconfigurable (DSP plus logic) functionality in pursuit of this opportunity.
It will be an interesting R&D area to follow, for sure.
-chipguy
References
[1]https://origin-blog.appliedmaterials.com/vc-opportunities-ai-developer-ecosystem
[2]Putnam, A., “The Configurable Cloud — Accelerating Hyperscale Datacenter Services with FPGA’s”,2017 IEEE 33rd International Conference on Data Engineering (ICDE),https://ieeexplore.ieee.org/document/7930129/ .
[3]https://www.graphcore.ai/posts/why-is-so-much-memory-needed-for-deep-neural-networks
Share this post via:



Comments
2 Replies to “Architecture for Machine Learning Applications at the Edge”
You must register or log in to view/post comments.