

I can remember back in the 1980s how Apollo workstations were quite popular, because they accelerated the graphics display time for EDA tools much better than competitive hardware. Fast forward to 2022 and we have the same promise of speeding up EDA tools like PCB layout editing by using a GPU. At the 58th DAC there was a session called, Accelerating EDA Algorithms with GPUs and Machine Learning, where Patrick Bernard and Anton Kryukov of Cadence presented.
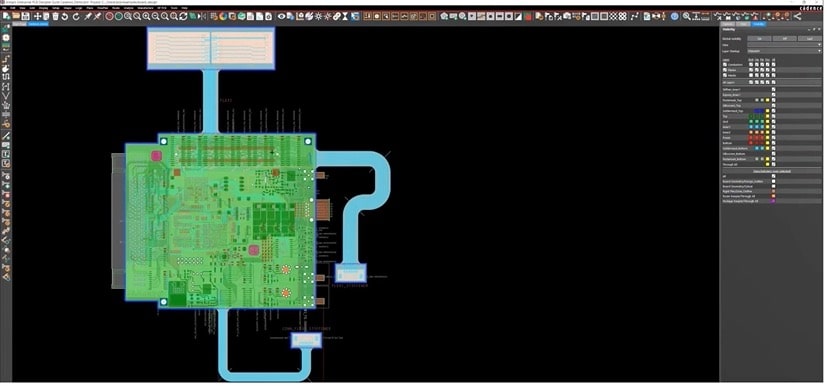
The Cadence PCB layout tool is called Allegro, and they added support to detect an Nvidia GPU to speed up rendering, something that benefits projects with large design sizes, like 100’s of millions of graphical objects and up to 200 layers. Just take a look at this 3D example from a small portion of a modern PCB to get an idea of the density of objects:
Every time that a PCB layout designer does a pan, zoom or fit operation, then there’s a render of each object, which takes time for the CPU to calculate new geometries. What Cadence developers did to speed up rendering times was to cache geometry in GPU memory, minimizing the calculations required.
Anton went into some of the details of how Allegro used the Nvidia GPU boards to accelerate the rendering times, and they used a Scene Graph (SG) data structure. A PCB has many layers, each shown in different color below:
Accelerated rendering is done through a pipeline of several internal steps:
- Allegro – incremental changes
- Scene Mapper
- Abstract Interface
- NV Plugin – renderer
- NV Plugin – QWindow + OpenGL context
- Create and place rendering window
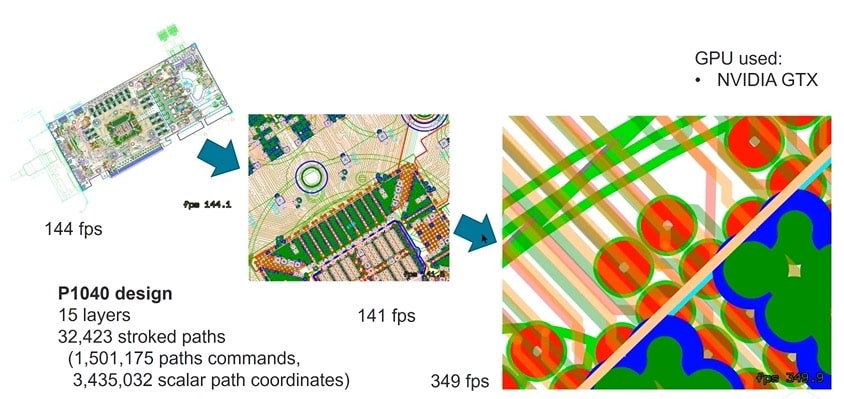
An example of how fast this GPU-based acceleration operates was shown with a 15 layer PCB design with 32,423 stroked paths, and Allegro had frame rates from 144 fps up to a whopping 349 fps, depending on the zoom level.
Even the text layers have acceleration for True Type Fonts with NV Path rendering. A technique called Frame Buffer Optimization (FBO) was also applied that understands the difference between a static and dynamic scene.
Results
Patrick shared that GPU results often rendered instantly when using an Nvidia Quadro P2000 card, compared to a few seconds for the old graphic engine speeds. Quality of zooming into graphics was also much improved:
With the old graphics approach there was a filter that identified objects less than 5-8 pixels, and simply didn’t show them at all. With the new GPU approach every single object is rendered, and there is no filtering, so there are fewer visual surprises to the designer when looking at their high-resolution monitors.
The Allegro tool ships with a demo board, and Patrick loaded that design and began to pan and zoom all around the board, with very little time spent waiting for all of the layers to render. The text was always crisp, and all objects were turned on.
You can expect the GPU-based acceleration to be applied to future PCB challenges, like:
- Shape engine
- Design Rules Checker
- Manufacturing output
- Simulations
Allegro automatically detects if your workstation is using one of the popular Quadro series of GPUs (P, GP, GV, T, RTX) or the Tesla (P, V, T), so you just enjoy faster productivity.
Summary
Over the years in EDA I’ve watched CPU performance improve, cloud computing emerge, and GPU acceleration techniques added. They all have their place in making engineers and designers more productive by not having to wait so much time for results to become visible. Development engineers at Cadence in the Allegro group have done a good job of speeding up graphical rendering times for PCB designers by support GPU cards from NVIDIA.
Now the CAD department can buy NVIDIA GPU cards for their PCB designers and see immediate productivity improvements in Allegro operations. The bigger the project, the bigger the time benefits.
View the full 38 minute video online at Nvidia.
Related Blogs





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}