- Huawei’s 7NM chip? This wasn’t supposed to happen
- Are Chips a weapon for U.S. or China? Role reversal?
- Will Taiwan turn from protected asset to unwanted liability?
- Are sanctions so porous that US has already lost to China?
While EUV is critical to advanced chips there are workarounds
Many people either thought or assumed that lacking EUV scanners would act as a complete roadblock to Chinese semiconductor companies seeking to go beyond 14NM technology. After all, this is obviously the case with Global Foundries in the US which after voluntarily abandoning EUV & R&D has been stuck in the technological dark ages of 14NM.
This has clearly proven to not be the case as Huawei has a new 7NM chip which has (surprisingly) shocked many people. Even without EUV, SMIC has been able to do what Global Foundries (and others) seemingly can’t, that is produce 7NM chips.
You don’t need EUV for 7NM
The mistaken assumption on the part of many in the industry and the US government is that blocking access to EUV scanners would by default limit further progress on Moore’s Law beyond 14NM or 10NM. This is patently untrue…..
The reality is quite different. Back when 7NM was being developed, years ago, EUV technology was a lot less certain than it is today. There were still many questions about its readiness for HVM, and whether it would work as needed at the costs hoped for.
All the major chip makers, TSMC, Intel & Samsung etc; had a “dual path” approach to 7NM, that they worked on in parallel. One path was multi-patterning using dual and quad patterning without EUV at all, and the other path was using EUV. Work on 7NM process started way back in about 2013 long before EUV was a settled issue.
Even after EUV was proven as a viable technology, the dirty little secret in the industry is that a number of chip makers still used multi-patterning at 7NM.
Obviously EUV will be the eventual winner as we progress down Moore’s law so everyone wants to get on board and start using it at 7NM and below.
ASML also made a very strong case that EUV was cheaper and it was obviously less complex with fewer steps in the process flow than multi-patterning…..so the choice to transition to EUV seemed clear.
While its quite clear that EUV has a better, simpler process flow, we are not so sure about it actually being significantly cheaper as ASML suggests as there have been a number of public papers that suggest that multi-patterning at 7NM is cheaper (when we get to 5NM, EUV is definitely cheaper).
SMIC can produce 7NM without EUV
Given that a lot of engineers have left TSMC to go to SMIC and likely taken with them all that they learned at TSMC its no surprise that they have been able to take the non-EUV fork of the dual path approach. Also, when you look at the cost basis, its likely not a significant cost hit to make the chips without EUV. After all a 193 scanner is less than a quarter of the cost of an EUV scanner.
Ex TSMC engineer left TSMC to help SMIC 7NM effort
The only thing we don’t know is how good the yields are…..However, with lots of metrology and inspection tools made by KLAC, NVMI, ONTO etc; which are still shipping into China in huge volumes, they can likely figure out the process over time.
Don’t be surprised when SMIC does 5NM
Yes, you can do 5NM without EUV, which means that SMIC can do 5NM. The process flow does however get quite complex and it will certainly cost more than EUV with likely lower yields. But it is indeed “doable” at some high cost & lower yield.
If you have no other choice and need the technology you will do whatever it takes to get access to that technology.
Given that SMIC has figured out multi-patterning for 7NM they can likely figure it out for 5NM.
Blocking EUV scanners is clearly not enough
SMIC has clearly proven that it can get around the EUV ban. With multi-patterning and enough advanced deposition (ALD) tools, etch tools and metrology/inspection tools.
Applied Materials, Lam, KLA and others are still shipping tons of tools to China which is their largest market by far and growing, as memory has shrunk and TSMC has slowed, China is still buying anything not nailed down and obviously getting enough advanced dep, etch and metrology tools to do 7NM
As we have suggested in the past, the current sanctions are likely very porous. The proof of the porosity is SMIC’s ability to do 7NM which would not be possible without advanced dep, etch & metrology….its just that simple.
In many cases older generation tools are simply no longer made by tool makers and current generation tools may be just “software restricted” to older technology nodes. In many cases the difference between an advanced tool and a less capable tool is just a “software switch”.
In lithography there is a clear, crisp line between EUV and 193, in other tools, not so much. As we have mentioned in the past the only sure way to limit technology is to limit to 200MM (8 inch) rather than 300MM as that is not porous and easily verifiable.
So if we truly want to limit China we need to get serious about sanctions and not put it all on ASML and the scanners.
It would be a lot easier for China to just develop a new litho tool than to have to copy litho, dep, etch & metrology and everything else needed to do 7NM so the real sanction would be across the board.
Has the US already lost the Chip war?
If SMIC is at 7NM, they are likely about 5 years or so behind TSMC and maybe a couple of years behind Intel & Samsung. Already close enough for many applications such as 5G and going to 5NM will get them firmly into AI applications.
So if the goal was to keep China out of 5G and AI, by definition, we have already lost the war.
We lost the war due to lack of resolve and bad technology assumptions….
Will Taiwan become a liability?
We have suggested in prior notes a while ago that China taking over Taiwan would be a “hollow victory” as all someone has to do is drop a grenade or satchel charge in the EUV scanners as they are leaving the fab during the invasion by China. China would thus be left with useless fabs and a somewhat hollow victory.
We think that logic may have already been turned on its head…..
The real question is who needs Taiwan more? The US or China? China now has 7NM (not too far behind Intel). They will likely get 5NM in the not too distant future. They can do 5G and AI with that.
Intel isn’t yet doing real AI and doesn’t have 5G like TSMC does. So if Taiwan were to go away tomorrow the US has no domestic fabs that can do a foundry based AI device nor does its have a 5G foundry device…..China in contrast now has a 5G capable 7NM process and probably 5NM AI capable in the future.
China has been ramping semiconductor capacity in a huge way, the US still hasn’t figured out who gets CHIPS act money and TSMC’s Arizona fab is delayed and Intel doesn’t yet have its foundry act together.
Right now it would be China that would have the advantage in semiconductors. All China would have to do is launch a few low yield missiles into TSMC’s Taiwan fabs and the US and the rest of the world would be screwed while China would not be that bad off as they are essentially cut off from TSMC anyway (so why let the rest of the world get the chips that they can’t have). So who needs Taiwan more?
After the fabs are knocked out, so goes the Taiwanese “silicon shield” as there would be nothing left to protect and Taiwan would become a liability rather than an asset to the US as there would be no semiconductors left to protect and the US government likely doesn’t care about the Taiwanese people just the strategic value of semiconductors to the US and global economies.
You may say….but wait!, there’s still Samsung….and I would say that Samsung’s fabs are just about in artillery or short rocket range of North Korea (China’s puppet & buddy) which would then have similar leverage to China under the control of someone even worse than Xi ……
Not too many good options, no quick fixes, likely a decade or two and more away from the US increasing its long lost semiconductor independence, even if we tripled the CHIPS Act.
For the political, intellectually challenged like Ramaswamy who think the US will be semiconductor independent by 2028, I have a bridge in Brooklyn for sale, cheap……
The stocks
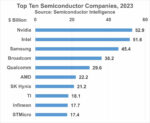
We think that the latest news out of SMIC increase the odds of sanctions being tightened ever further, and not just on ASML, as 7NM has proven that enough other dep, etch & metrology/inspection equipment that is advanced enough is getting into China to produce advanced devices. That means AMAT, KLAC, LRCX in the US and TEL, ASMI and others. We are nearing the one year anniversary of the October sanctions of 2022 and so far its a big fail……as SMIC & Huawei have thumbed their noses at the US.
The down cycle is far from over as TSMC’s recent delay of tools underscores. Memory still sucks, although pricing seems to have bottomed we are a very, very long way from needing to increase memory chip production.
However, the stocks are still near all time highs and the recent ARM IPO was a raging success and likely carried semiconductor valuations which were already high even further.
We still see a lot of risk everywhere and not much of it reflected in semiconductor stocks. We think the ARM IPO while great was more of a sign of “cabin fever” being released on the first big tech IPO in a while with everyone wanting a piece at any price.
We’ll see if the apparent failure of sanctions on the one year anniversary has any reaction…..and what that may be….
About Semiconductor Advisors LLC
Semiconductor Advisors is an RIA (a Registered Investment Advisor),
specializing in technology companies with particular emphasis on semiconductor and semiconductor equipment companies.
We have been covering the space longer and been involved with more transactions than any other financial professional in the space.
We provide research, consulting and advisory services on strategic and financial matters to both industry participants as well as investors.
We offer expert, intelligent, balanced research and advice. Our opinions are very direct and honest and offer an unbiased view as compared to other sources.
Also Read:
SMIC N+2 in Huawei Mate Pro 60
ASML-Strong Results & Guide Prove China Concerns Overblown-Chips Slow to Recover
SEMICON West 2023 Summary – No recovery in sight – Next Year?
Micron Mandarin Memory Machinations- CHIPS Act semiconductor equipment hypocrisy