
You may be under the impression that anything to do with neural nets necessarily runs on a GPU. After all, NVIDIA dominates a lot of what we hear in this area, and rightly so. In neural net training, their solutions are well established. However, GPUs tend to consume a lot of power and are not necessarily optimal in inference performance (where learning is applied). Then there are dedicated engines like Google’s TPU which are fast and low power, but a little pricey for those of us who aren’t Google and don’t have the clout to build major ecosystem capabilities like TensorFlow.
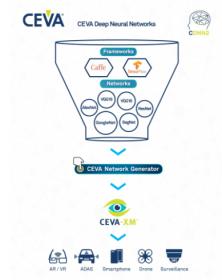
Between these options, lie DSPs, especially embedded DSPs with special support for CNN applications. DSPs are widely recognized to be more power-efficient than GPUs and are often higher performance. Tying that level of performance into standard CNN frameworks like TensorFlow and a range of popular network models makes for more practical use in embedded CNN applications. And while DSPs don’t quite rise to the low power and high performance of full-custom solutions, they’re much more accessible to those of us who don’t have billion dollar budgets and extensive research teams.
CEVA offers a toolkit they call CDNN (for Convolutional Deep Neural Net), coupling to their CEVA-XM family of embedded imaging and vision DSPs. The toolkit starts with the CEVA network generator which will automatically convert offline pre-trained networks / weights to a network suited to an embedded application (remember, these are targeting inference based on offline training). The convertor supports a range of offline frameworks, such as Caffe and TensorFlow and a range of network models such as GoogLeNet and Alex, with support for any numbers and types of layers.
The CDNN software framework is designed to accelerate development and deployment of the CNN in an embedded system, particularly though support functions connecting the network to the hardware accelerator and in support of the many clever ideas that have become popular recently in CNNs. One of these is “normalization”, a way to model how a neuron can locally inhibit response from neighboring neurons to sharpen signals (create better contrast) in object recognition.
Another example is support for “pooling”. In CNNs, a pooling layer performs a form of down-sampling, to reduce both the complexity of recognition in subsequent layers and the likelihood of over-fitting. The range of possible network layer types like these continues to evolve, so support for management and connection to the hardware through the software framework is critical.
This framework also provides the infrastructure for these functions you are obviously going to need in recognition applications, like DMA access to fetch next tiles (in an image, for example), store output tiles, fetch filter coefficients and other neural net data.
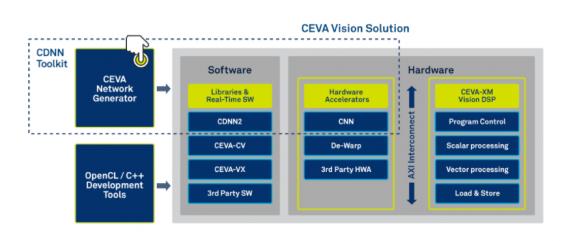
The CDNN hardware accelerator connects these functions to the underlying CEVA-XM platform. While CEVA don’t spell this out, it seems pretty clear that providing a CEVA-developed software development infrastructure and hardware abstraction layer will simplify delivery of low-power and high-performance for embedded applications on their DSP IP. An example of application of this toolkit to development of a vision / object-recognition solution is detailed above.
Back to the embedded / inference part of this story. It has become very clear that intelligence can’t only live in the cloud. A round-trip to the cloud won’t work for latency-sensitive applications (industrial control and surveillance are a couple of obvious examples) and won’t work at all if you have a connectivity problem. Security isn’t exactly enhanced in sending biometrics or other certificates upstream and waiting for clearance back at the edge. And the power implications are unattractive in streaming the large files required for CNN recognition applications to the cloud. For all these reasons, it has become clear that inference needs to move to the edge, though training can still happen in the cloud. And at the edge, GPUs characteristically consume too much power while embedded DSPs are battery-friendly. DSPs benchmark significantly better on GigaMACs and on GigaMACs/Watt, so it seems pretty clear which solution you want to choose for embedded edge applications.
To learn more about what CEVA has to offer in this area, go HERE.
Share this post via:



Comments
4 Replies to “DSP-Based Neural Nets”
You must register or log in to view/post comments.