General Motors’ announced shut down of the Maven car sharing service was hardly a surprise, especially coming in the midst of the COVID-19 pandemic. By the time of its demise, Maven was only operating in four or five cities, down from a high of 17. The venture was doomed from the start, and its departure is a cautionary tale for Toyota, Renault, BMW, Daimler and other auto makers flirting with car sharing.
General Motors told the Automotive News that it learned a lot from Maven and its sister division Maven Gig. The group did collect vehicle data to track charging and usage of Bolt EV’s on the Maven Gig platform and GM got its first real taste of running a connected fleet of vehicles and directly managing a B2C service.
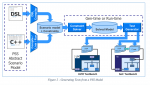
The reason that Maven was doomed from day one is the fact that it was born an orphan. Maven was never part of existing GM operations. Though run by executives drawn from GM’s fleet division it was not part of GM’s fleet operation. Though leveraging OnStar’s connectivity and call center, Maven relied on its own add-on hardware for vehicle access and customer service was separate from OnStar.
Stunning to me from day one was the introduction of the Maven brand itself. Though vaguely clever, GM’s marketing executives must have realized that it would take millions of dollars to build the Maven brand into a recognizable corrolary brand under the General Motors umbrella.
By opting for the Maven brand and standing up a separate team outside of any existing division and without sufficient marketing support or C-level support within the larger organization, Maven was left to subsist on its own with no particular direction. What was Maven’s purpose in life? Was it intended to attract new customers to the brand? Was it intended to open new markets? Was it a platform to trial new technologies and business models? Was it intended to fend off competitive threats? Was it intended to supply cars to Uber/Lyft/Via drivers? Was it intended to provide loaner cars for dealers – potentially displacing existing Uber/Lyft or rental car providers?
None of this was clearly defined. Making matters more confusing was the failure to integrate the Maven strategy with the $500M investment in Lyft – that is now looking more ill-conceived than ever.
A Lyft-Maven one-two punch might have been a powerful launch statement for the car sharing offer. GM could have announced its $500M Lyft investment along with the Maven launch with incentives for drivers to use Maven vehicles at attractive rates. Needless to say that didn’t happen.
Neither Maven nor Lyft brands were leveraged on the OnStar platform or as part of GM’s Global Connected Consumer group, within which OnStar resides. There might have been a scenario where every GM vehicle was enabled for Lyft or Maven activation. In fact, the OnStar brand – in which GM has invested hundreds of millions of dollars over more than two decades – could have been repositioned as a mobility brand.
Such a strategy would have superseded Elon Musk’s plans to launch Tesla Network automated shared vehicles via over-the-air software update. OnStar could have begun its evolution and return to being a brand-defining service for General Motors. But, no, that didn’t happen either.
Without a plan to leverage Maven through GM’s fleet operations, its dealer operations, or as a brand builder and customer finder, Maven meandered into irrelevance and found its meaning as a cost center – a science experiment. Maven couldn’t absorb large volumes of off-lease vehicles; it couldn’t pioneer new car models to be shared from splashy city center showrooms; it couldn’t redefine car sharing.
Maven was a careful, cautious, foray into an arena dominated by local community supported car sharing operators, pure plays, and rental car companies. Rental car companies, in particular, kept the pressure on in what is a low margin marketplace.
Car sharing is a capital intensive business requiring millions of dollars to support wheels on the street. Add in the logistical element of cleaning, insuring, repairing, recovering, and paying for parking and parking infractions and there is precious little cash left over.
The final blow for car sharing operators lacking patience is the inability to drive volume. Yandex is one of the few operators in the world that has found the magic wand to drive customer interest in shared cars – super cheap rates. For GM, such a strategy would only stimulate the bleeding. It would also undermine the company’s primary business: selling cars.
The challenge for car companies is to aggressively promote car sharing when what they really want to do is sell cars. Car companies spend billions of dollars on advertising and incentives to sell cars. Car sharing is a hobby and it is a hobby that, should it become too successful, could threaten the primary business.
In the end, it all comes back to Tesla. Tesla has already solved this problem. Tesla Network has car sharing and ride hailing baked into its long-term plans as an inherent function built into the vehicle. Car sharing and ride hailing, when available directly from Tesla, won’t require additional hardware, a new organization or a new brand – it will simply be an extension of the Tesla value proposition.
This was the opportunity presented by Maven – to be an inherent part of all GM vehicles and an integrated part of the GM value proposition – perhaps under the OnStar brand. This is the core of the missed opportunity.
The shuttering of Maven is an ominous note to be struck within the wider GM family. GM is burning $250M/quarter at its Cruise Automation self-driving car unit in San Francisco.
GM has its own, in-house automated driving initiative in Super/Ultra Cruise. Super Cruise and Ultra Cruise Level 2 automated driving features are already being deployed on GM vehicles – with 22 models expected to be outfitted with the technology by the end of 2021. Super and Ultra Cruise are being developed with unique mapping and localization technology unlike anything Cruise Automation is working on.
GM has clearly indicated that the Cruise Automation path to market is not an aftermarket kit or fitment on mass produced, consumer-oriented vehicles – it is a full-blown robo-taxi. GM’s in-house team – at the Warren Tech Center – is already delivering a value proposition, Super Cruise, for which consumers are paying…happily.
By comparison, Cruise is looking like an expensive distraction and, like the $500M Lyft investment, a gamble. As a separate operation, like Maven, Cruise may find itself cut loose if not shut down – though Softbank, Honda, and other investors will have a say. With the termination of Maven, GM has shown, once again, it is able to cut its losses. In the time of COVID-19, though, we are starting to get close to the bone.