Caching intent largely hasn’t changed since we started using the concept – to reduce average latency in memory accesses and to reduce average power consumption in off-chip reads and writes. The architecture started out simple enough, a small memory close to a processor, holding most-recently accessed instructions and data at some level of granularity (e.g. a page). Caching is a statistical bet; typical locality of reference in the program and data will ensure that multiple reads and writes can be made very quickly to that nearby cache memory before a reference is made outside that range. When a reference is out-of-range, the cache must be updated by a slower access to off-chip main memory. On average a program runs faster because, on average, the locality of reference bet pays off.
For performance, that cache memory has to be close to the processor and therefore small; it can only hold a limited number of instruction or data words. As programs and data size get bigger, added levels of caching (still on-chip) became important. Each hold a larger amount of data at the price of progressively slower accesses, but still much faster than main memory access. These levels of cache were named, imaginatively, L1 (for level 1, closest to the processor), through L2, L3 and in some cases L4. Whichever of these is closest to the external memory interface is called the last-level cache.
Then we started to see multi-processor compute. Each processor wants its own cache for performance but they all need to work with the same main memory, introducing a potential coherence problem. If processor A and processor B read/write to the same memory address, you don’t want them getting out of sync because actually they’re each working with a local copy in their own caches.
To avoid chaos, all accesses still have to be synchronized with the central main memory address space. Delivering this assurance of coherence between caches depends on a lot of behind-the-scenes activity to snoop on locations written/read in each cache, triggering corrective action before a mismatch might occur.
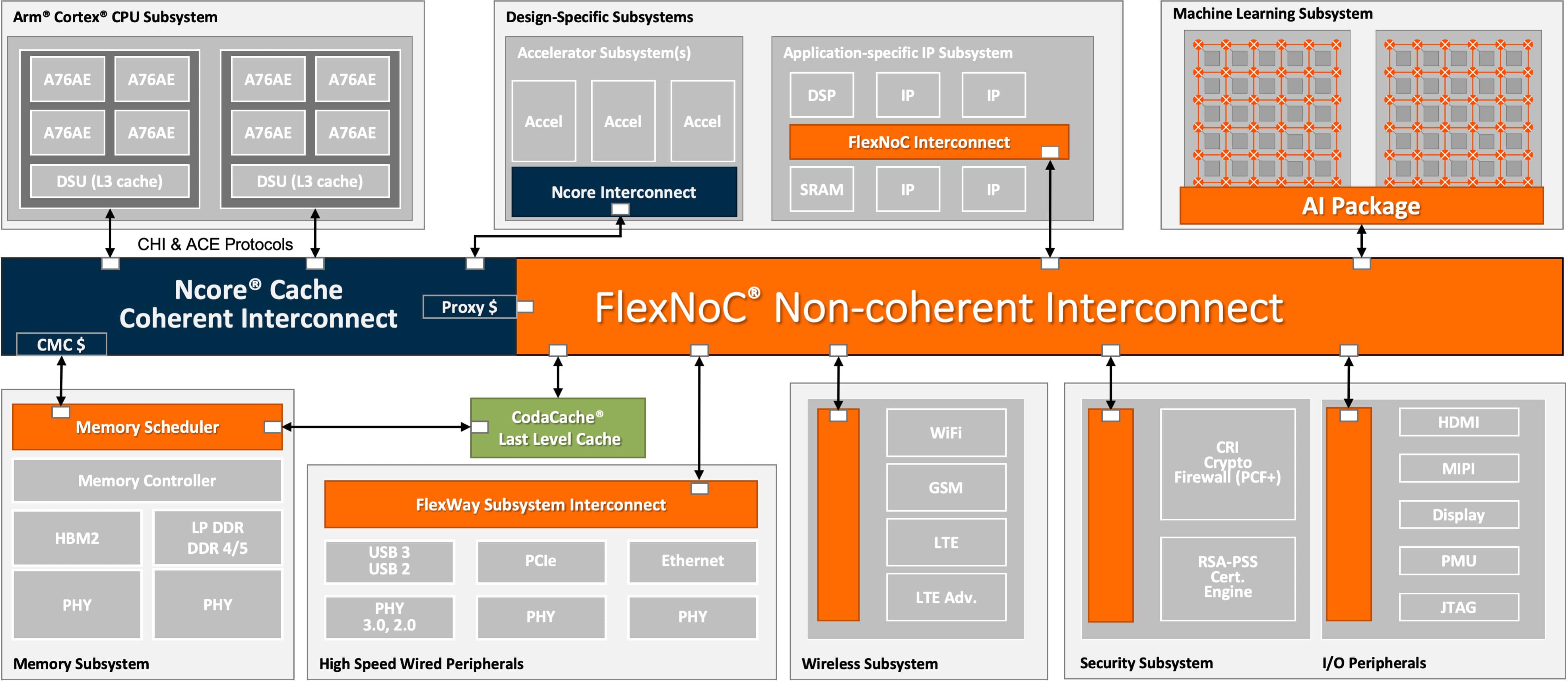
For SoCs, Arm provides a cache-coherent communications solution between their processor IPs called the DynamIQ Shared Unit (DSU), solving the problem for fixed clusters of Arm CPUs. But for the rest of the SoC you need a different solution. Think of an AI accelerator for example, used to recognize objects in an image. Ultimately the image (or more likely stream of images) is going to come through the same memory path for processing by AI and non-AI functionality alike.
So AI accelerator accesses must be made coherent with the rest of the coherent subsystem. Arteris IP provides a solution for this through their Ncore cache coherent NoC interconnect which provide proxy caches to coherently connect non-coherent AI accelerators with the SoC coherent subsystem. You can do this with multiple accelerators, even multiple AI accelerators, a configuration which apparently is becoming popular in a number of devices.
Next consider that a number of these accelerators are becoming pretty elaborate and pretty big in their own right. Now the Ncore interconnect is not just a way to connect the accelerator to the SoC cache subsystem but a full coherent interconnect supporting multiple caches inside the accelerator.
This is needed because AI accelerators depend even more heavily on localized memory for throughput; a grid-based accelerator might have local cache associated with each processing element or group of processing elements. This coherent interconnect performs a similar function to the Arm coherent DSU but inside a non-Arm subsystem and using a NoC architecture which can more practically extend over long distances.
Then think further on those long distances and the fact that some of these accelerators are now reticle sized. Maintaining coherence directly over that scope would be near-impossible without significantly compromising the performance advantages of caching. What does any good engineer do at that point? They manage the problem hierarchically with multiple domains of local coherence connecting to higher-level coherent domains.
Finally and more back down to earth, what about the last-level cache, the one right before you have to give up and go out to main memory? Arteris IP provides the CodaCache solution here which can sit right by the memory controller. This is highly configurable for size, partitioning, associativity and even scratchpad memory to allow AI users to optimize tuning to the dataflow they expect to have with their AI app, perhaps to pre-fetch data they know they will need soon.
Caching has come a long way from those early applications. Arteris IP is working with customers in each of these areas. You can learn more about their Ncore cache coherent interconnect HERE and CodaCache HERE.
Share this post via:



Comments
One Reply to “How Should I Cache Thee? Let Me Count the Ways”
You must register or log in to view/post comments.