I attended one of the Arm partner events in Cambridge many years ago, when they first talked about the coherent hub for managing cache coherence. I was impressed, but the obvious question even then was how any non-Arm IP was going to hook into this hub. They had a solution, of course, the ACE interface, and I left satisfied. As is the way with these things, that solution was good for a while. But System-on-Chip (SoC) architectures continued to evolve and get more complex. Pushing for cache coherence everywhere.
Now video and hardware accelerator streams dominate a lot of processing with high levels of parallelism, not only in the CPU cluster but also in AI accelerators among other IPs. As more processing elements are added the complexity of the software to simply manage the data flow explodes, so we’re starting to see hardware cache coherence everywhere across the SoC. (I was surprised to learn that even Mali is non-native on the CHI interface; it still connects through ACE.)
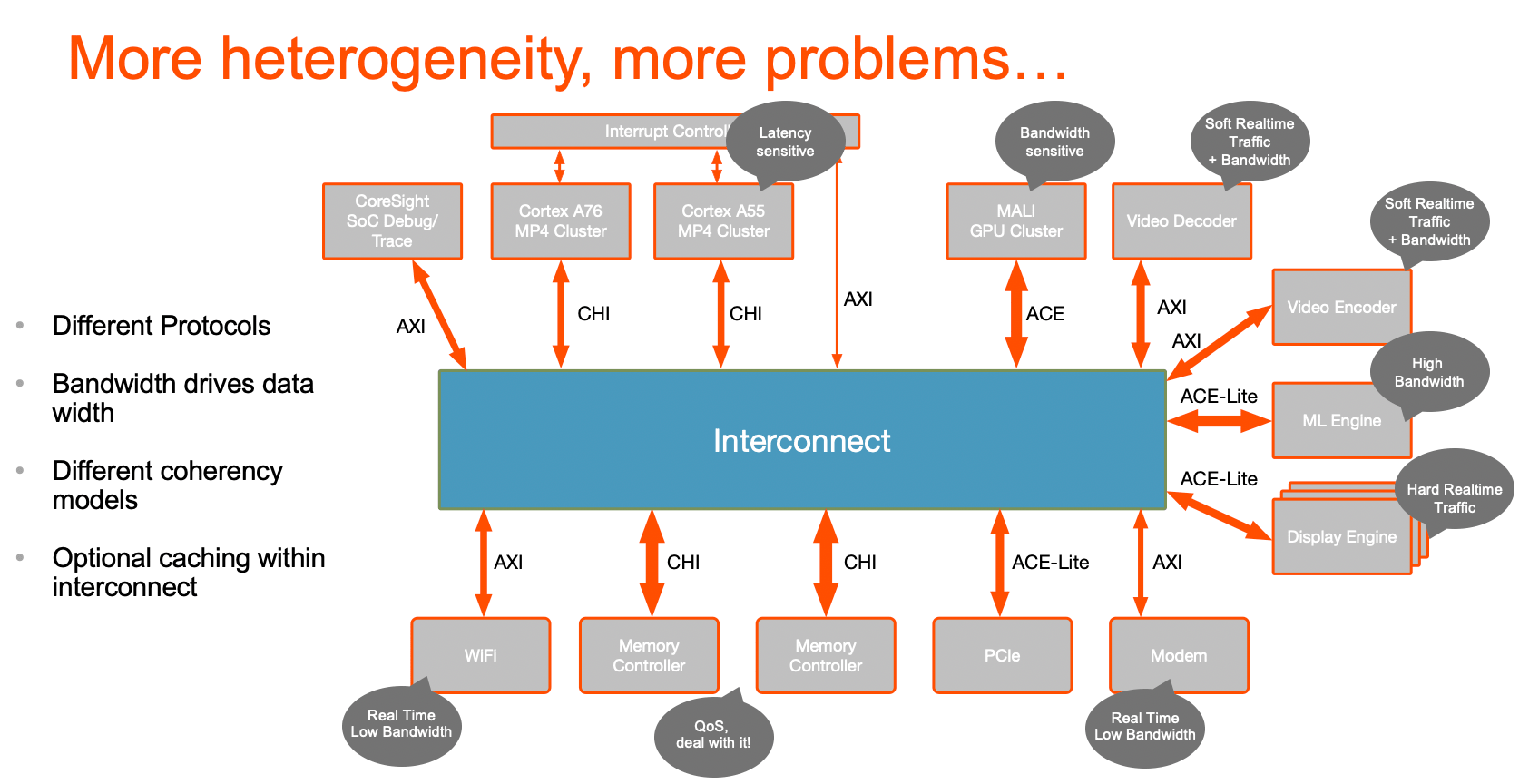
Coherency challenge in a heterogenous system
The figure here illustrates the challenge. Of course, you can connect all your own IP into the coherent interconnect as long as they support CHI, ACE or ACE-Lite interfaces. But being able to connect isn’t the end of your problems. The interconnect is no longer serving just the needs of that high-speed CPU cluster. Now it has to service a wide variety of bandwidth demands, varying levels of QoS need, and some traffic expecting real-time support. Anything that doesn’t have coherency support, you’ll have to do development work to add an appropriate interface. It shouldn’t be a surprise that meeting all these conflicting needs is going to be hard. Maybe impossible.
Topology challenges
There’s another problem – interconnect topology. SoCs of this type tends to be big, even extending to multi-die in package implementations. Generic mesh and crossbar connectivity would be wildly impractical, consuming huge levels of real estate. This is also true inside AI accelerators. So designers have explored different ways to structure interconnect topologies. Trees – popular in earlier crossbar-based designs. Mesh networks – Arm offers an option here. Rings and Torii. All ways to distribute connectivity across chip-scale distance without needing to overload a central point of coherence. Inconveniently, SoC integrators are saying they need mixtures of all these options to create an interconnect optimized for their requirements. Could you fake it with a mesh network? Apparently not as efficiently, in part because in a mesh, communication has to jump from node to node to node to cross long distances. You could drop otherwise unused nodes in the mesh, but apparently, that still can’t rise to the performance levels of other options.
The advantages of a coherent NoC
What you really want is coherency, but with all the distance spanning, low congestion, and tunable QoS advantages of a Network-on-Chip (NoC). A NoC in which the central transport function of the interconnect is independent of the IP protocols attached to it. Each interface – CHI, ACE, ACE-Lite and AXI (non-coherent) – can connect through an interface to the transport layer. Designer-guided tuning across the die can optimize impact on floorplan. And bandwidth, QoS and latency can be optimized through designer choices and configuration software automation on connections and choice of switches. Coherency in the network is managed through one or more snoop filters in directories. And IP with non-coherent interfaces (e.g. AXI) can connect through an adapter with a proxy cache to allow participation as equal citizens in the cache coherent system.
This is what Arteris IP offers in their Ncore 3 coherent interconnect. NoC reach, connect any protocol and QoS management with coherency. Pretty impressive. You can learn more about Ncore 3 here and at the upcoming Linley conference.
Also Read:
AI in Korea. Low-Key PR, Active Development
CEO Interview: Charlie Janac of Arteris IP
Interconnect Basics: Wires to Crossbar to NoC
Share this post via:



Comments
4 Replies to “Cache Coherence Everywhere may be Easier Than you Think”
You must register or log in to view/post comments.