

The great thing about competition in free markets is that vendors are always pushing their products to find an edge. You the consumer don’t have to do much to take advantage of these advances (other than possibly paying for new options). You just sit back and watch the tool you use get faster and deliver better QoR. You may think that is the least you should expect, but remember in effective monopolies (cable for example?) you don’t even get that. Be happy there is real competition in EDA 😎

For quite a while Synopsys held the pole position in logic simulation with VCS. The top metric by far in this domain is speed and here Cadence recently upped their game with Xcelium. Around the same time, Synopsys recently announced their next step in acceleration with fine-grained parallelism (FGP) support in VCS and it looks to me like we’re back to a real horse race. I have no idea who has the better product today – that’s for the market to decide – but VCS FGP looks to me like a worthy runner.
VCS FGP gets to faster performance through parallelism – no big surprise there. The obvious question is how well this scales as the number of processors increases. One thing I like about Synopsys is that they let us peek behind the curtain, at least a little bit, which I find helps me better understand the mechanics, not just of the tool but also why emerging design verification problems are increasing the value of this approach.
First, a little on platforms for parallelism. Multi-core processors have been around for a while, so we’re used to hearing about 8-core processors. In what seems to be an Intel-ism (apologies, I’m not a processor guru), when you get above 8 processors, the label switches to many-core, reflecting no doubt advances to support higher levels of inter-CPU support (even more sophisticated cache coherence, etc.). Most important, the number of cores per processor is growing quickly and expected to reach ~200 by 2020, providing a lot more scope for massive parallelism within a single processor. Processors at this level are commonly used in exascale computing and are also promoted as more general-purpose accelerators than GPUs (after all, not every modern problem maps to neural net algorithms).
Which brings me back to simulation. Earlier acceleration efforts at the big EDA vendors were offered on GP-GPUs, but it seems telling that both have switched back to CPU platforms, perhaps because of wider availability in clouds/farms but presumably the GPU advantage for this application can’t be too significant versus many-core acceleration.
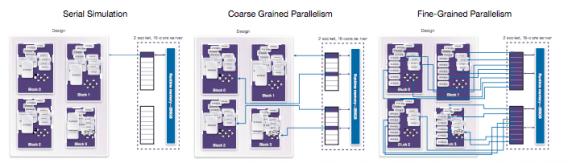
Synopsys give (in a webinar HERE and a white paper HERE) a nice intro to their use of this level of parallelism in simulation. The basic (non-parallel) case runs on one processor. All event modeling and I/O is serial in this case. The first step towards parallelism divides RTL (or gate-level) blocks between cores; within a core, modeling and I/O remains serial but now you have parallelism between cores. This is multi-threading in which each block goes into a thread and there can be as many threads as there are cores. Synopsys calls this coarse-grained parallelism. The next step is to partition at the task level (always block, continuous assign, ..). This fine-grained (hence FGP) distribution should allow for optimum use of parallelism, especially across many more threads/cores, if tasks are optimally distributed.
How they do that is something Synopsys chooses not to share, unsurprisingly. But they do share (in the webinar) some guidelines on how to best take advantage of VCS FGP. Designs that will benefit most will be those with a high level of design activity across the design (a common theme with other solutions). Examples they cite include graphics, low power designs, multi-core (surprise, surprise) and networking designs, all at RTL. They also cite gate-level PG simulations and scan test simulations. All should have a lot of activity across the chip at any given time – lots of IPs lit up a lot of the time, the way many modern designs operate.
Procedural and PLI/DPI content are less friendly to this kind of parallelism. Which doesn’t mean your design can’t use these constructs; they’ll just limit potential speed-up. In theory you might expect that high-levels of communication between tasks in different threads would also limit performance gains. This seems to be an area where vendors like Synopsys have found a pragmatic approach which offers significant speed-up for many realistic designs and objectives, even though it can’t provably do so for all possible designs/objectives (reminds me of the traveling salesman problem and practical routing solutions which work well in physical design tools).
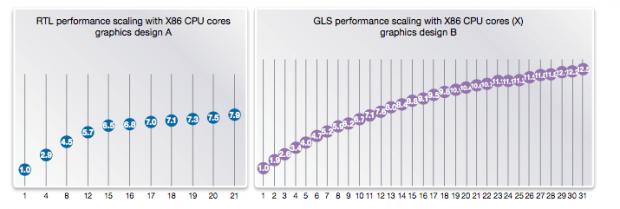
Of course some level of inter-thread communication is unavoidable if the design is to do useful work so the benefit of adding more cores for any given design and workload will saturate somewhere. Synopsys show this in the above curves for an RTL design and a gate-level design. But this kind of limit will apply to all approaches to parallelization.
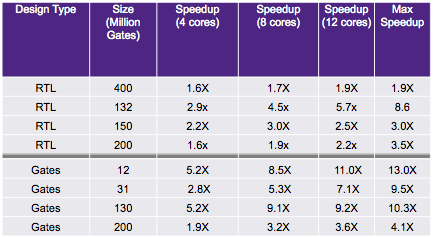
Synopsys has posted some pretty impressive performance gains across a variety of designs (results shown here are the latest, not seen in the webinar or the white-paper, as of the time I saw it). Settle back and enjoy the gains!




Comments
There are no comments yet.
You must register or log in to view/post comments.