
Machine learning (ML) is a once-in-a-generation innovation that seems like it should be applicable almost everywhere. It’s certainly revolutionized automotive safety, radiology and many other domains. In our neck of the woods, SoC implementation is advancing through learning to reduce total negative slacks and better optimize floorplans. But functional verification has been curiously resistant to the charms of ML. I know this is not for lack of trying. Some of the superficially “obvious” candidates, such as improving constrained random test generation, have proven not to be as easy or as effective as you might think.
ML for orchestration
That doesn’t mean there aren’t ways to use ML in this field. We just have to think more creatively. Formal verification has already breached the barrier by using ML to orchestrate use of 30 or more formal engines to prove (or disprove) assertions. Formal isn’t just one technique; there are many engines and methodologies to use those engines in order to work towards a proof. There’s not a fixed way to know in advance what will work. You try something for a while – if that isn’t getting you anywhere, you try something else. Orchestration is managing this process automatically. Knowing how to do this efficiently is quite dependent on experience, and therefore amenable to ML training.
ML for regression acceleration
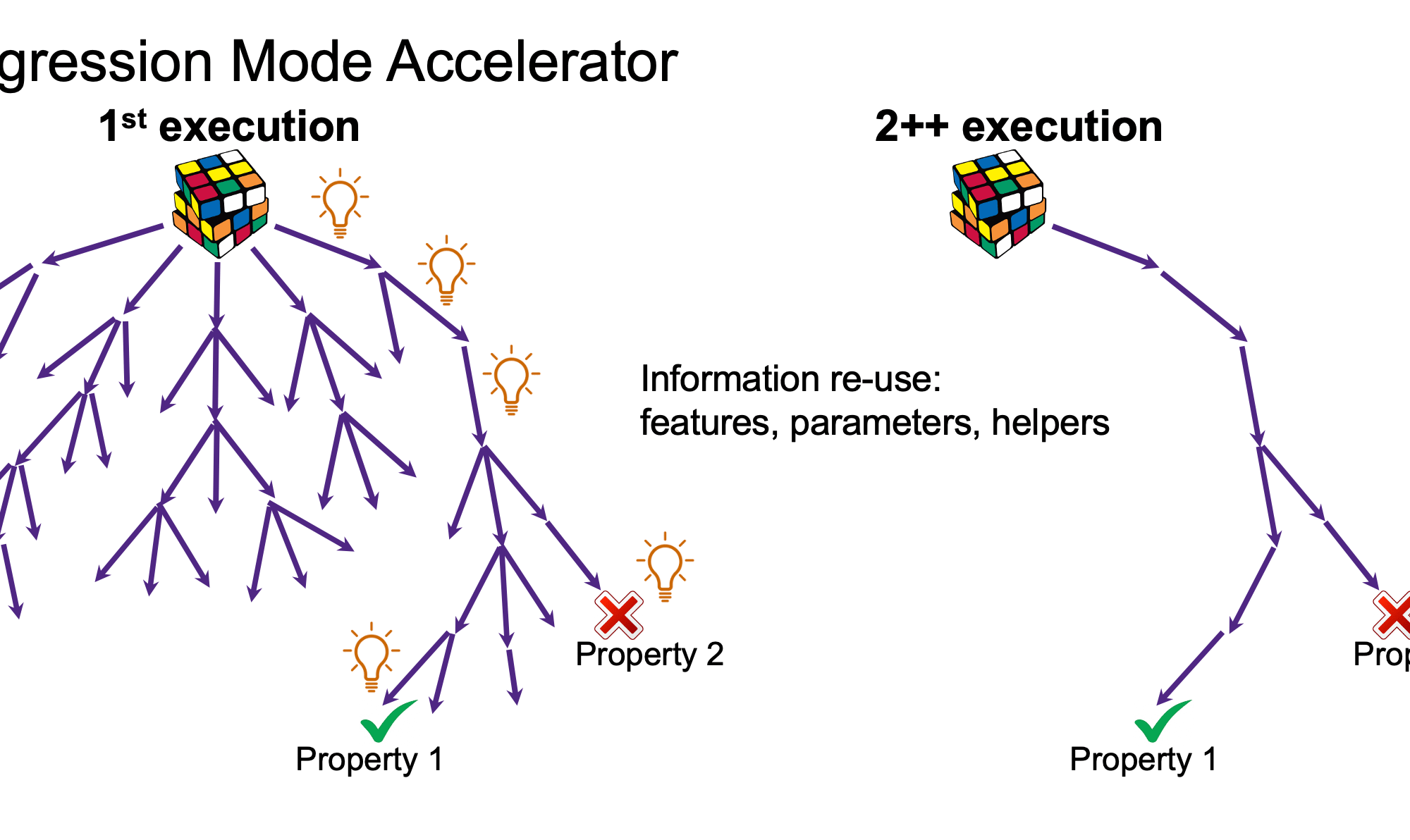
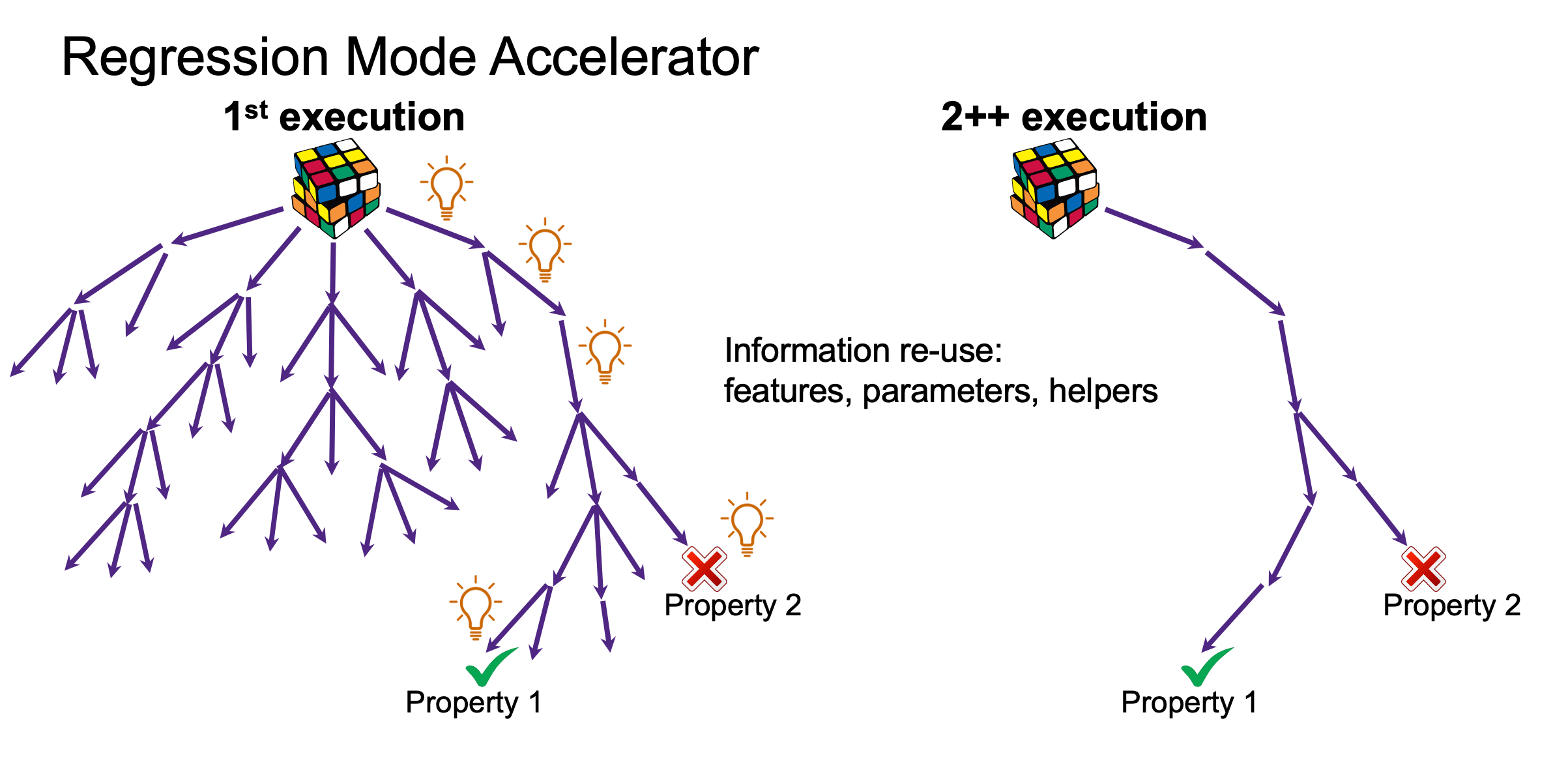
Another application is in accelerating regression runs. Regression is a natural for ML because the whole process is a continuous refinement with a growing database of results (until you make big changes). Synopsys recently posted a webcast detailing how they now offer ML-based regression mode acceleration (RMA) in VC Formal. The image above gives a simplified explanation of how this works. In the first run, proving/disproving progresses through multiple paths until proofs or counterexamples are found. On a subsequent run, those conclusive paths can be checked first to re-verify. If the checks are good, regression moves on to the next step. If not, the search can be expanded to find new proofs or counterexamples.
The impact is obvious. Regressed runs don’t have to start from “zero knowledge” each time. They can build on what they already know. With the caveat that where logic changed and therefore certain proofs did not work as before, engines need to back off to generate new proofs. Which then become the basis for new learning. From that point, subsequent regressions can start. This isn’t just theory. Synopsys show examples in which they get to very impressive speedups (24-65X) in simply re-running regressions. And in some cases are able to complete additional assertions which were previously inconclusive. Speedups in these cases are not as impressive, but hey, you completed more proofs than before. And next time around you should get those big speedups again!.
ML for bug hunting
The presenter (Sai Karthik Madabhushi, Sr Apps Engineer) also talked about applying this capability to bug hunting. This is a neat application for RTL developers while still in design. Testbench development at this stage is uncommon, however bug hunting is a very productive way to look for bugs early on. Here you create assertions you think should hold true, then run formal to see if you can find counterexamples. This can be very productive, but without intelligence, you keep retracing unproductive paths in subsequent runs as you try to extend the depth of your search. RMA can help here also, by following successful traces from previous runs to reach further out, to find deeper failures.
You can watch the webcast HERE.
Also Read:
Change Management for Functional Safety
What Might the “1nm Node” Look Like?
EDA Tool Support for GAA Process Designs
Share this post via:



Comments
2 Replies to “A New ML Application, in Formal Regressions”
You must register or log in to view/post comments.