According with IPnest, the Interface IP market, including USB, PCI Express, (LP)DDRn, HDMI, MIPI and Ethernet IP segments, has reached $532 million in 2016, growing from $472 million in 2015. This is an impressive 13% Year-over-Year growth rate, and 12% CAGR since 2012!
Who integrate functions to interface a chip with others IC or connector? The answer is simply that for any application, you need to interact with another chip (DRAM, SSD, Application Processor or ASSP), or with the outside world through a connector (from HDMI to PCIe or USB). If you consider chip design, you quickly realize that two kinds of functions are ubiquitous: processing and interfacing. This consideration is comforted by their respective weight in the IP license market (before royalty). In 2016, the license only market has weighted $1930 million. The license revenues generated by processor IP (CPU, GPU, DSP) of $680 million represent 35% of the total, when the interface IP license, weighting $532 million, is 27.5%. The addition of processor and interface IP generates 62.5% of the total (license) IP market.
If ARM is known to be the king of the processor IP market, and consequently, thanks to royalties, of the total IP market with 48.4% market share, Synopsys is the duke. Synopsys is now the clear #2 of the design IP market, and the undisputed leader of the interface IP market, with 51% market share and over $270 million revenues. In fact, if we look at this market by segment, USB, PCI Express, etc., Synopsys is also the leader in each of these 5 IP segments: USB, PCI Express, MIPI, HDMI, DDRn, with a market share between 50% to 75%.
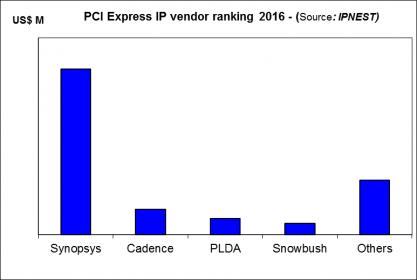
In the survey, IPnest is making a very comprehensive analysis, by protocol, including a ranking by IP vendor and competitive analysis, or a review of all the IP vendors active in the segment. It’s always possible to find a niche where a vendor, not necessarily leader, will enjoy good business. IPnest also analyze the market trends to predict the future adoption of a specific protocol in new applications. For example, PCI Express protocol was initially developed to support the PC, computing and networking segments. We have seen the pervasion in mobile, with Mobile Express definition in 2012, but also in storage (NVM Express) and the pervasion in automotive is now acted.
Such comprehensive analysis will help IPnest to build 5 years forecast, taking into account the growth of number of design starts including PCIe function, and also that we call “externalization factor”. The externalization factor is the augmentation of the proportion of PCIe IP being externalized, and this factor may change every year, even if the proportion of commercial IP is only growing, year after year.
Competitive analysis: IPnest propose, by protocol, a competitive analysis and a ranking, like for example for PCI Express:
Being part of the DAC IP committee and running IPnest, Eric Esteve was also the chairman of the panel “The IP Paradox” (The semiconductor industry is consolidating, and the number of potential customers is shrinking, but the IP market is still growing, in particular the interface IP market. How to explain this growth?). If we can answer this question, we will be able to more accurately forecast the IP market growth.
John Koeter, VP Marketing for Synopsys, has proposed an explanation: “We study the market and 60-70% of the IP is outsourced. When I look at IP, I think it is potentially the same size as the EDA market. EDA is fully outsourced, but IP is not there yet which means there is growth available.”IPnest 100% agree with this! If we try to model the IP market growth, we see that there is 10 to 15 years growth reserve for the IP market to be fully outsourced (assuming +/-3% value for the externalization factor).
A graphic view of the market evolution, by protocol, for 2012 to 2021:
It’s important to notice that IPnest is now the only company offering the “Design IP Report” (2015 and 2016 ranking of all the IP vendors by categories, from CPU to GPU, DSP, mixed-signal, memory compilers, libraries, interface, etc.) as Gartner has stopped to make it in 2016. IPnest is also the only analyst launching the “Interface IP survey & forecast”. In fact, this is the 9[SUP]th[/SUP] version of this report and was launched last week.
If you are interested by the Table of Content for the 2017 version of the report (2012-2016 Survey – Forecast 2017-2021), just send me a message on Semiwiki, or on Linkedin: Eric Esteve
We can also meet during ARM TechCon in Santa Clara (10/24 to 10/26), I will stay until 10/27.
Eric Esteve