In an ANSYS seminar held at DesignCon 2019, Dr. Larry Williams, ANSYS Director of Technology, outlined how 5G design innovation can be accelerated through simulation. He posited that 5G will become a general-purpose technology that affects an entire economy, drastically alter societies and unleash a cascade of complementary innovations (*).
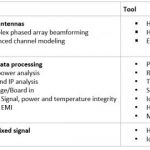
For starters, advanced simulation can help 5G in the analysis of advanced antennas, data processing, and complex mixed signals. The types of analysis and the tools used to accomplish them are summarized in this table below.
5G Phased Arrays produce multiple beams and null out interfering unrelated users. The 5G new radio provides each user their own beam, and with massive MIMO can support multiple simultaneous users in the same bandwidth.
The Array Design Methodology includes antenna element design which includes quick performance prediction and analysis when standalone or when integrating into a finite array or a unit cell (i.e. infinite array). The finite array analysis captures all effects including edge effects, mutual coupling, and active S-parameters. Finally, the Array Design methodology includes Array Platform integration and real-world phased array performance effects including platform effects.
Encrypted 3D components can incorporate the original simulation model which may include sensitive and proprietary IP allowing sharing with 3rd parties while preserving the fidelity of the fully encapsulated and encrypted original model allowing geometry visibility and defined fields and making possible a 3D EM simulation. Installed antenna performance analysis can thus occur without exposing sensitive IP.
Simulation for 5G (28GHz) base station performance requires a physics-based simulation of large-scale environments with SBR (Shooting Bouncing Ray) for efficient simulation of electrically large environment allowing an accurate representation of antenna array through FEM simulation.
System performance evaluation will include the antenna array, site evaluation, beamforming, and null steering algorithms, received power at the user equipment and base to base station interference or unintentional jamming. Received power includes a line of sight and multi-path propagation. A device traveling in dense urban areas between coverage zones of two base stations can have its received power observed allowing site evaluation and base station to base station interference.
Complex mixed-signal systems
According to Skyworks’ CTO Peter Gammel (**), mobile operators can achieve 5G speeds on a 4G network by enabling Carrier Aggregation. Schematic-based and error-prone tedious methods can be replaced with assembly modeling automating the process allowing scripted steps that reduce the time and eliminate system wiring errors.
Full mesh assembly is now possible in ECAD and MCAD allowing an accurate and efficient mesh creation and capturing full network parameters for all nets including small pitch and/or meandering traces and with accurate coupling and isolation.
Data Center Electronics
By 2022, autonomous vehicles are estimated to use 4TB/day/car for an average hour of operation. By 2022, Mobile users are estimated to pull 25GB/day/person. By 2023, mobile data traffic is expected to reach 18 Exabytes per month in North America. Issues facing new data centers include the need for extremely fast channel Signal Integrity analysis of SerDes (25-100Gbps), PAM4 (56-112Gbps), Power Integrity (0.65V with 5% tolerance) and finally Thermal Integrity analysis including thermal stress in boards and components due to the increased power required to operate data centers.
Virtual prototypes analysis includes virtual compliance and Printed Circuit board reliability analysis which include electrical and thermal assessment, temperature distribution, power map, mechanical and thermal stress, potential die cracking, flip chip attachment, package deformation, and solder joint reliability due to thermal cycling.
Ansys has new electronics reliability tools that include an EMI scanner for EMC/EMI design rule check (in HFSS and SIwave) and electromigration analysis allowing calculation of Mean Time to Failure (MTBF) in addition to the existing thermal tools (Icepak in AEDT, Ansys Mechanical Thermal).
Semiconductors now require improved reliability for HPC electronics and rigorous safety for automotive electronics allowing long system lifetimes and mandating zero defects in harsh thermal environments. Autonomous vehicles require Radar, Camera, and LiDAR sensor models that must be tested with vehicle control systems and algorithms to validate safe operation. Radar is susceptible to the environment like induced degradation with snow, rain, dirt, road/wind/weather conditions. Full system simulation is needed. Ansys acquired France-based Optis which has a tool that allows just that.
5G is shaping to be ‘the biggest thing in wireless since wireless’ as Dr. Williams states, with insight, breakthrough thinking, and innovation possible with simulation.
Advanced FinFET Designs Enabling 5G Electronics System Reliability
Following that, Dr. Norman Chang, ANSYS Chief Technologist, addressed enabling 5G Electronics system reliability for advanced FinFET designs. The trends for integration include increasing IP content, 2.5/3D IC packaging. In the power/performance arena trends include 112G SerDes, WideIO, 5G mmWave high frequency and fan-less cooling. Making system reliability an increasing focus with needed lifetimes greater than 15 years, aging, thermal/EM/ESD/EMC reliability, substrate and RFI noise challenges. This mandates accurate electrical models for on-chip components such as a spiral inductor and clock-tree/transmission lines.
Aging in FinFET is accelerated by two major device degradation mechanisms:
- Negative Bias Temperature instability (NTBI)
- Hot Carrier Injection (HCI) and Time Dependent Dielectric Breakdown (TDDB)
This requires aging aware SoC timing closure to ensure long term reliability
Substrate noise coupling can affect analog circuitry. Noise coupling causes spikes in the FM spectrum and impacts audio quality and performance. Other needs exist for ESD/EMC simulation for Chip-Package-System which include ESD/EMC sign-off at IOs/IP and SoC levels. ESD rules are checked Board-to-Chip, Chip-to-Chip, Board-to-Board. Pin-to-Pin ESD connectivity, resistance checks, current density checks, driver receiver checks, and dynamic ESD checks result in an ESD IP model that feeds into an IC ESD model run through CECM allowing EMC/System-level ESD simulations.
System-level ESD simulations are critical for 5G/ADAS systems. The target is system level ESD signoff with CECM for IEC61000-4-2 testing. What-if analysis allows system level ESD optimization. The solutions needed are IO/IO Ring Modeling, Full chip layout modeling, and power grid extraction, ESD device modeling, chip ESD modeling, and system level ESD analysis with CECM.
Dr. Chang closed by stating that moving forward Machine Learning and Deep Learning will be instrumental in enabling EM/Timing Assistants for reliability and timing check through an integrated ML stack also allowing for user-driven ML-Apps.
Call to Action URL: https://www.ansys.com/resource-library/article/speeding-5g-network-infrastructure-design-aa-v13-i1
________________
(*) According to Erik Brynjolfsson, Director of the MIT Initiative on the Digital Economy
(**) Skyworks Whitepaper: “5G in Perspective – A Pragmatic Guide to What’s Next”