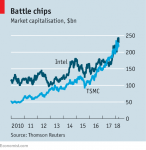
I wrote about Cadence AI IP not long ago when I covered the Cadence Automotive Summit at the end of July (Tensilica DNA 100 Brings the AI Inference Solution for Level 2 ADAS ECUs and Level 4 Autonomous Driving, Tensilica HiFi DSPs for What I Want to Hear, and What I Don’t Want to Hear). One of those two blogs remains one of my most widely read blogs. In those blogs I spoke quite a bit about the Tensilica DNA 100 processor. Since that event was targeting automotive topics, the focus was of course on delivering advanced automotive features, such as ADAS. At the Linley Processor Conferences, the context is different as the emphasis is on processors. So rather than simply just talking about what is needed for automotive features, Cadence went deeper into the system architecture options that are delivering these solutions using DNA 100, which can apply to far more than automotive. Lazaar Louis, Cadence’s Senior Director of Product Management, Marketing and Business Development for Tensilica IP, did a great job as a presenter, including a short Q&A session.
For AI edge inference, Cadence has three different types of processor IP. Users can choose the best solution for the specific workflow they are planning to use for each problem. This approach makes sense in automotive, where there are many different subsystems. It also makes sense when simply building a consumer IoT product where you want the correct processor for your price point and power budget. The Tensilica HiFi DSP product line is for audio, voice, speech, and AI applications. The Tensilica Vision DSP product line (including the recent Vision Q7 DSP) is for embedded vision processing, imaging, and AI. This year Cadence released the Tensilica DNA 100 as a standalone AI processor. With the increase in AI processing in consumer and automotive products, customers are implementing multi-core solutions with HiFi, Vision and DNA processor IPs to serve audio, vision and AI applications.
I cannot get into all the technical breadth of the Cadence-Linley presentation in this blog. If you want to see architectural details, I believe you can request a copy of the presentation through the Linley website, or simply contact your Cadence sales rep for more information. Lazaar’s presentation featured lots of details related to sparse computing, using a specialized neural network (NN) engine, scalability, high MAC utilization, using the Tensilica Neural Network Compiler, neural network libraries, minimizing accuracy loss due to quantization, and even more. It is rich and in-depth.
What I do want to remind you about is the need for a significant ecosystem. Software plays a large role in all AI/ML solutions. Beyond that you may need different types of semiconductor IP. Cadence is also part of Glow, Facebook’s community-driven approach to AI. Glow is a machine learning compiler for heterogeneous hardware. Cadence has committed to offering processor IP supporting Glow.
In August, I had focused more on the ecosystem around audio solutions as part of Cadence’s infotainment solutions. The list of partners in the embedded vision space is also impressive. Cadence highlighted eight of those partners at the conference, ArcSoft, MulticoreWare, Seemmo, Sensory, Visidon, Morpho, Almalence, and Irida Labs. These solutions can all be combined with Tensilica IP to make some truly amazing results.
Cadence is certainly “focused” (pun intended) on embedded vision. Cadence gave three presentations at the 2019 Embedded Vision Conference: Frank Brill, Portable Performance via the OpenVX Computer Vision Library: Case Studies; Pulin Desai, Highly Efficient, Scalable Vision and AI Processors IP for the Edge; and Shrinivas Gadkari, Fundamentals of Monocular SLAM. It will be interesting to see how cadence continues its effort in embedded vision in 2020.
On a final note, the Tensilica team has been supporting automotive standards for a long time. Rest assured that they have a handle on ISO 26262, ASIL levels, and everything related to automotive safety and reliability. What I pointed to in August, saw again at the AI Hardware Summit in September, at ARM TechCon in October, and at every technical conference I attend, there is one prevailing thought about AI/ML systems – “There is no safety without security.” Cadence’s partnership with Green Hills in this area is to be commended. Security will keep all this dream technology functioning without interference.
This is my final blog of three blogs from the Linley Fall Processor Conference for 2019. The first two blogs are here and here. If processors are your thing, or you just like staying current on the topic, you should consider going to the spring conference. Details are not yet announced, but you should be able to find them here once they are available.