

Back in 2020 I first learned from Synopsys about how they had engineered a better way to do optimize layouts on digital designs by using machine learning techniques, instead of relying upon manual approaches. The product was named DSO.ai, standing for Design Space Optimization, and it produced a more optimal floor-plan in less time than a human could, saving many man-months of effort. The world’s leading Android-based smart phones is Samsung, and they’ve used DSO.ai to optimize the design of their Exynos chips. Last week I followed up by Zoom to hear from two experts at Synopsys about the next steps in using machine learning, Thomas Andersen, VP, AI and Machine Learning and Stelios Diamantidis, Sr Director, AI Solutions.
At the highest level it is said that software is eating the world, with all of the activity in AI, increases in video use, and the growing number of data centers. Recently we see that AI is eclipsing software, and that is driving engineers to create new kinds of compute to meet the challenges. Chip designs are now being optimized to run the most prominent apps.
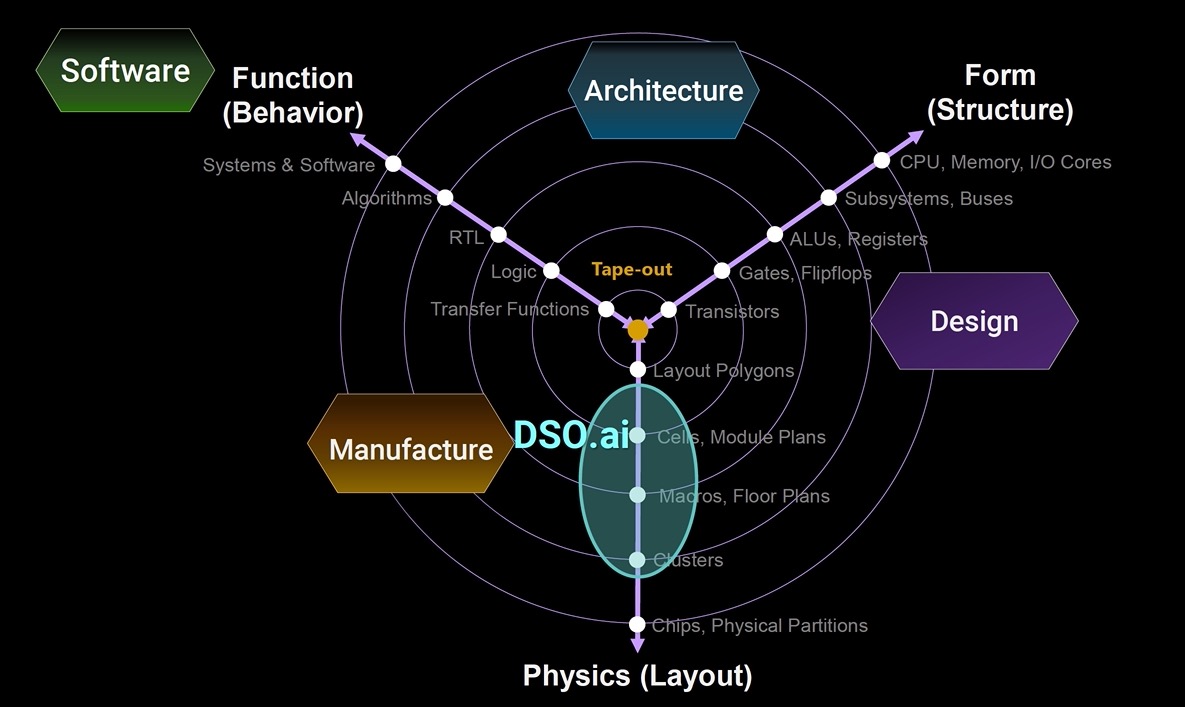
The first generation of DSO.ai could optimize a layout, then show you metrics like leakage power versus timing, allowing you to choose the best design. Shown below is the classic Y diagram, made famous by Gajski-Kuhn back in 1983. The area where DSO.ai works is shown highlighted in green:
The optimizations within DSO.ai are controlled by an engineer setting multi-objectives and search spaces, then the tool runs using reinforcement learning and results are visualized in a plot. Systems companies like Google and NVIDIA have likewise done work in applying AI to their internal tool flow for macro placement of blocks, so this is a promising area to follow.
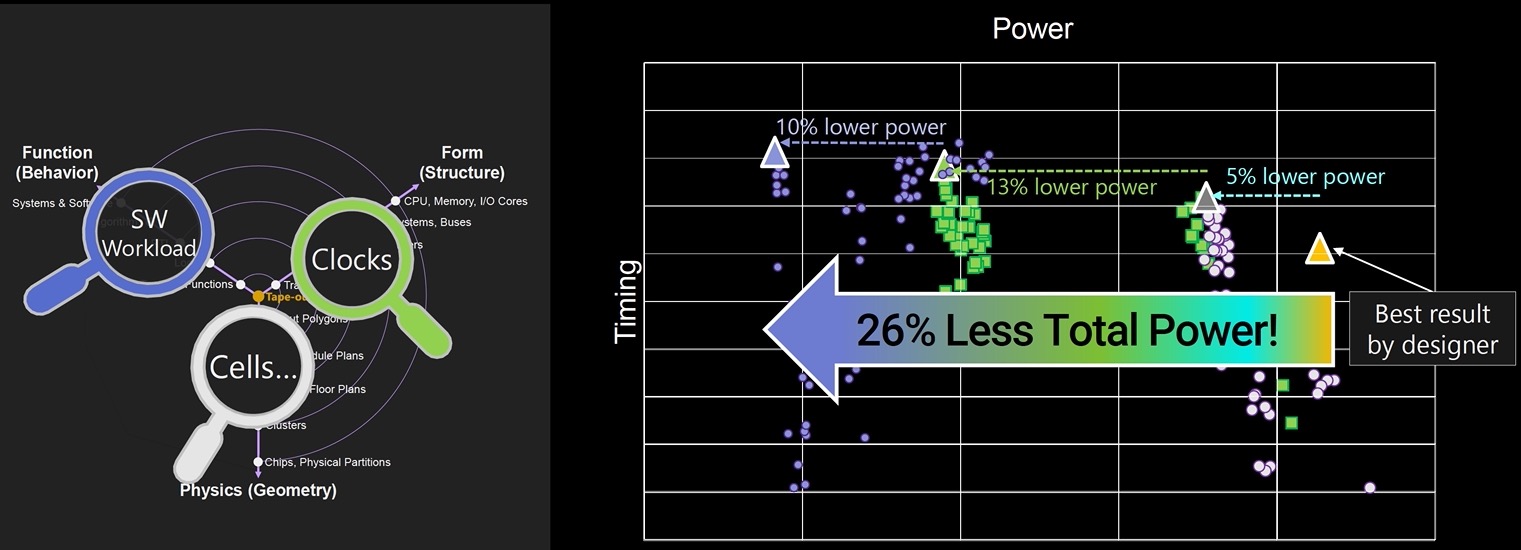
At the recent Hot Chips conference, Synopsys revealed that DSO.ai was now expanding beyond just optimizing layout, to optimizing clock gating and clock structuring in the RTL code. Furthermore, when you want to optimize for power, you can run your chip on an emulator as it executes an app, to drive the optimization. OK, so the concept sounds interesting, but where’s the data to prove the value?
An SoC design example was presented, where using just the layout optimizations showed a 5% power reduction versus a hand-crafted approach. Adding the clock optimizations by changing the RTL coding provided another 13% lower power number. Finally, using the actual power activity from running an app on the SoC through an emulator, the optimization achieved another 10% power reduction. Here’s the results:
I just needed to clarify that while these new optimizations in DSO.ai are on actual customer designs, you’ll have to wait for any official product update announcement from Synopsys. The trend is clear though, engineers are going to enjoy less manual effort involved in the chip design process, because concepts like machine learning are suited to automate some of the tasks in the tool flow. Engineers still need to specify the constraints for the optimizations, and then build up on the a result, all while saving time in the process. Synopsys is the first EDA vendor to demonstrate the use of AI across all three axis: Behavior, Structure and Geometry.
I asked about the learning curve of DSO.ai, and was told that most teams are becoming productive within their first week. You will see the biggest benefits from using an all-Synopsys flow, although other vendor tools could be mixed in the flow, but the optimization engine doesn’t have as much ability to control a non-Synopsys tool. I wonder if other EDA vendors will want to get their point tools certified to be DSO.ai aware, in order to fit better into a Synopsys flow. Time will tell.
Each run with DSO.ai runs design tools, so iterating to create dozens of possible designs takes some time, however convergence is much faster compared to the manual approach. The concurrent optimization approach across behavior, structure and geometry is a bold idea.
Summary
No, we’re not at the point of AI designing new chips from scratch, even though that concept makes for a popular SciFi movie plot. Reinforcement learning has been successfully applied with the DSO.ai technology to optimize concurrently across three domains: behavior, structure and geometry. Early results look quite promising with this optimization approach.
Also Read:
How Hyperscalers Are Changing the Ethernet Landscape
On-the-Fly Code Checking Catches Bugs Earlier
Upcoming Virtual Event: Designing a Time Interleaved ADC for 5G V2X Automotive Applications







{kind=link}
{kind=link}