
It is obviously a truism that somewhere in an SoC there is something limiting a further increase in performance. One area where this is especially noticeable is when a Tensilica core is used to create a highly optimized processor for some purpose. The core performance may be boosted by a factor of 10 or even as much as 100. Once the core itself is no longer the limiting factor, I/O bandwidth to get data to and from the core often comes to the head of the line. Traditional bus-centric design just cannot handle the resulting increase in data traffic.
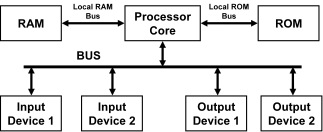
A long time ago processors had a single bus for everything. Modern processors separate that so that they have one or more local buses to access ROM and RAM and perhaps other memories, leaving a common bus to access peripherals. But that shared bus to access the peripherals becomes the bottleneck if the processor performance is high.
Tensilica’s Xtensa processors can have direct port I/O and FIFO queue interfaces to offload overused buses. There can be up to 1024 ports and each can have up to 1024 signals, boosting I/O bandwidth by thousands of times relative to a few conventional 32 or 64 bit buses.
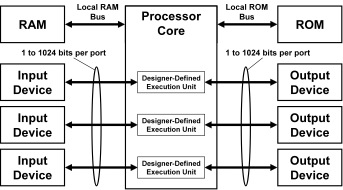
But wait, there’s more. Since Tensilica’s flexible length instruction extension (FLIX) allows designers to add separate parallel execution units to handle concurrent computational tasks. Each user-defined execution unit can have its own direct I/O without affecting the bandwidth available to other parts of the processor.
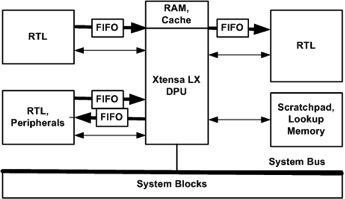
While plain I/O ports are ideal for fast transfer of control and status information, Xtensa also allows designers to add FIFO-like queues. This allows the transfer of data between the processor and other parts of the system that may be producing or consuming data at different speeds. To the programmer these look just like traditional processor registers but without the bandwidth limitations of shared memory buses. Queues can sustain data rates as high as one transfer per clock cycle or 350Gb/s for each queue. Custom instructions can perform multiple queue operations per cycle so even this is not the cap on overall bandwidth from the processor core. This allows Xtensa processors to be used not just for computationally intensive tasks but for applications with extreme data rates.
It is no good adding powerful capabilities if they are too hard to use. I/O ports are declared with simple one-line declarations (or a check-box configuration option). A check-box configuration is also used to define a basic queue interface although a handful of commands can be used to create a special function queue.
Ports and queues are automatically added to the processor and, of course, are completely modeled by the Xtensa processor generator, reflected in the custom software development tools, instruction set simulator (ISS), bus functional model and EDA scripts.
A white paper with more details is here.





TSMC CoWoS versus Intel EMIB Semiconductor Packaging