
AI is quickly becoming the new killer app and everyone is piling on board as fast as they can. But there are multiple challenges for any would-be AI entrepreneur:
- Forget about conventional software development; neural nets require a completely different infrastructure and skill-sets
- More and more of the interesting opportunity is moving to the edge (phones, IoT, ADAS, self-driving cars). The cloud-based AI we routinely hear about is great for training, not so much for the edge where inference is primary, must be very fast, very low power and can’t rely on big iron or (quite often) a communication link
- The hardware on which these systems run is becoming increasingly specialized. Forget about CPUs. The game starts with GPUs which have become very popular for training but are generally viewed as too slow and power-hungry for the edge. Next up are DSPs, faster and lower-power. Then you get to specialized hardware, faster and lower-power still. Obviously, this is the place to be for the most competitive neural net (NN) solutions.
The best-known example of specialized hardware is the Google TPU, which is sucking up all kinds of AI workloads on the cloud. But that doesn’t help for edge-based AI – too big, designed for datacenters, not small form-factor devices and anyway Google isn’t selling them. But now CEVA is entering this field with their family of embedded NeuPro processors designed specifically for edge applications.
You probably know that CEVA for some time has been active in supporting AI applications on the edge through their CEVA-XM family of embedded DSPs. In fact they’ve built up quite a portfolio of products, applications, support software, partnerships and customers, so they already have significant credibility in this space. Now, after 25 years of developing and selling DSP-based solutions in connectivity, imaging, speech-related technologies and AI, they have added their first non-DSP family of solutions directly targeting neural nets (NNs) to their lineup, pursuing this same trend towards specialized AI hardware.
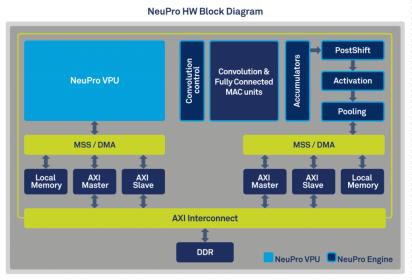
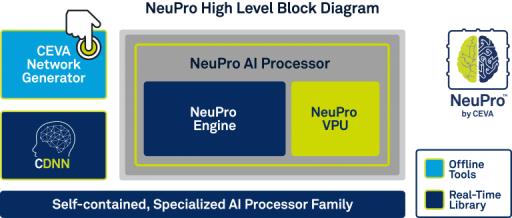
The solution, and it is a solution in the true sense, centers around a new processor platform containing a NeuPro engine and a NeuPro vector processing unit (VPU). The engine is an NN-specific system. This supports matrix multiplication, convolution, activation and pooling layers on-the-fly so is very fast for the fundamental operations you will have in any NN-based product. Of course NN technology is advancing rapidly so you need ability to add and configure specialized layers; this is supported through the VPU and builds on the mature CEVA-XM architecture. Notice that the engine and the VPU are tightly interconnected in this self-contained system, so there can be seamless handoff between layers.
So what does this do for you on the edge? One thing it does is to deliver pretty impressive performance for the real-time applications that will be common in those environments. The product family offers from 2 TOPS to 12.5 TOPS, depending on the configuration you choose. On the ResNet-50 benchmark, CEVA has been able to show more than an order of magnitude performance improvement over their XM4 solution. And since operations run faster, net energy consumed (e.g. for battery drain) can be much lower.
Another very interesting thing I learned when talking to CEVA, and something for which they provide great support, concerns precision. Low-power NNs use fixed-point arithmetic so there’s a question of what precision is optimal. There has been quite a bit of debate around how inferencing can effectively use very short word-lengths (4 bits or lower). Which is great if you only need to do inferencing. But Liran Bar (Dir PM at CEVA) told me there are some edge applications where local re-training, potentially without access to the cloud, is needed. Think about a driver-monitoring system (DMS) which uses face ID to determine if you are allowed to start the car. You’re out in the middle of nowhere and you want your wife to drive, but she isn’t yet setup to be recognized by the DMS. So the system needs to support re-training. This is not something you can do with 4-bit fixed point arithmetic; you need to go to higher precision. But even more interesting, this doesn’t necessarily require a blanket word-size increase across all layers. Individual layers can be configured to be either 8-bit or 16-bit to optimize accuracy along with performance, depending on the application. CEVA supports modeling to help you optimize this before committing to an implementation, through their CDNN (CEVA Deep Neural Net) simulation package.
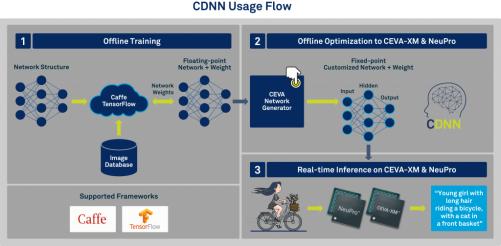
You should know also (if you don’t know already) that CEVA has been making waves with their CDNN including the CEVA Network Generator ability to take trained networks developed through over 120 NN styles and map these to implementation nets on their embedded platforms. That’s a big deal. You typically do training (in many contexts) in the cloud, but those trained networks don’t just drop onto edge NNs. They have to be mapped and optimized to fit those more compact, low-power inference networks. This stuff is pretty robust – they’ve been supporting it with the XM family for quite a while and they’ve won several awards for this product. Naturally, the same system (no doubt with added tuning) is available with NeuPro.
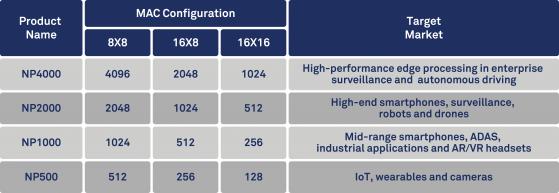
So this isn’t just hardware, or hardware supporting a few standard NN platforms. It’s a complete edge-based solution, which should enable all those AI-on-the-edge entrepreneurs to deliver highest performance, lowest power/energy solutions as fast as possible, leveraging all the investment they have already made or plan to make in cloud-based NN training. NeuPro is offered as a family of options to support a wide range of applications, from IoT all the way up to self-driving cars and with precision options at 8-bit and 16-bit. Availability for lead customers will be in Q2, and for general release in Q3 this year. This is hot off the press, so see CEVA at CES next week or checkout the website.




Comments
There are no comments yet.
You must register or log in to view/post comments.