
In the superheated world of AI and Neural Nets (NN), many of us are familiar with object recognition in images: cars, pedestrians, cats and dogs and thousands of other applications. But there’s another class of applications, also growing rapidly, around audio AI. Early generations for command recognition in infotainment systems (eg navigation control) and smartphones (through eg Siri) were arguably more entertaining than compelling. In my view, what turbo-charged the audio AI market was Alexa. Now you can find products and active development in smartphones and personal assistants, watches, voice-activated TVs, appliances, headsets, hearables and head-mounted displays for VR/AR/MR. A FutureSource survey claims that growth in the audio market is now almost entirely driven by smart audio with a 15% CAGR from 2015 to 2018, accelerating to 30%+ from 2019 to 2023 (Yole Development).
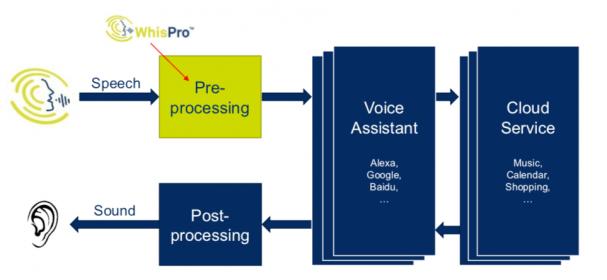
When you think of an Alexa, Siri or similar, you might assume that all the smarts for these systems are in the cloud. That’s certainly the case for the more advanced functions (natural language recognition is one example), but it makes sense to keep some of the AI on the edge node, for all the usual reasons: latency, power or continuing to operate when a link is down. Consider always-on trigger-phrase recognition (“Alexa”, “OK Google”, …). It would be insane to go to the cloud to check every noise the device picks up, so trigger recognition has to be localized on the device. Or think about voice control for a home appliance such as a microwave or a thermostat where you don’t need to support an extensive vocabulary. Why go to the cloud at all? Why not handle all the recognition you need in the appliance (rather than “Sorry kids, cold leftovers tonight. The Internet’s down so I can’t turn on the microwave” :cool:).
CEVA has been active in the audio space for a long time, as you might expect for a company whose core expertise is built on DSPs. As smart assistants have taken off, they have become particularly strong in far-field voice pickup, the essential front-end of smart assistants and TVs for example. There’s a lot of technology here before you even get to neural nets because sound pickup isn’t quite as easy to deal with (in some ways) as light. First, it’s not as simple to figure out where a sound came from, which can be important if you want to separate the source from say TV sound. Figuring that out takes multiple microphones and beamforming. Then sound environments are generally a lot noisier that visual environments, not just thanks to multiple sources but also because sound echoes off surfaces; you have to filter out those secondary sources. A battery-operated device shouldn’t turn on even these stages unless it believes it has detected a human voice, so the first stage is a voice activity detector (VAD). CEVA has already introduced technologies to handle these aspects of voice pickup, in their ClearVox software running on various CEVA DSP platforms.
The next step is to take that clean, directionally-localized audio signal and run it into trigger phrase recognition – is this a command for me? At CES this week, CEVA announced availability of their WhisPro software which does precisely this. The software runs exclusively on a number of CEVA platforms and operates in always-on mode at ultra-low power. This is a big deal for battery operated devices. If you remember Amazon’s early introduction of battery-operated Echo devices, they worked fine but had to be recharged every few hours, even when minimally activated, because they were still burning power just listening for “Alexa”. Coupled solutions like WhisPro+CEVA DSPs are ultimately the only way to get to really low always-on power.
WhisPro is trained to recognize “Alexa” and “OK Google”; Moshe Sheier (VP Marketing at CEVA) tells me that it currently supports English and will soon support Mandarin and that CEVA will add training for other words/phrases at customer request. So a product could work equally well in multiple markets.
Important metrics in voice recognition are accuracy, noise resilience and privacy. You don’t want your smart assistant or TV turning on and asking you questions in the middle of the night. You also want to know that your commands won’t be misdirected en-route to the cloud. Moshe tells me that WhisPro, front-ended by ClearVox, delivers a recognition rate of 95%, comparable to Amazon and Google and is very noise resilient. Accept/Reject rates are also comparable to those providers. Also, these comparisons are at relatively short range; ClearVox extends the usable range to around 7 meters in noisy environments, which is likely better than other solutions can offer. And of course localizing initial recognition on the device naturally enhances privacy, just as it does in other AI at-the-edge applications.
WhisPro is available for licensing today for use on the CEVA-TeakLite-4, CEVA-X2 and CEVA-BX DSP platforms and is compliant with the main tier-1 voice services. You can learn more HERE.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.