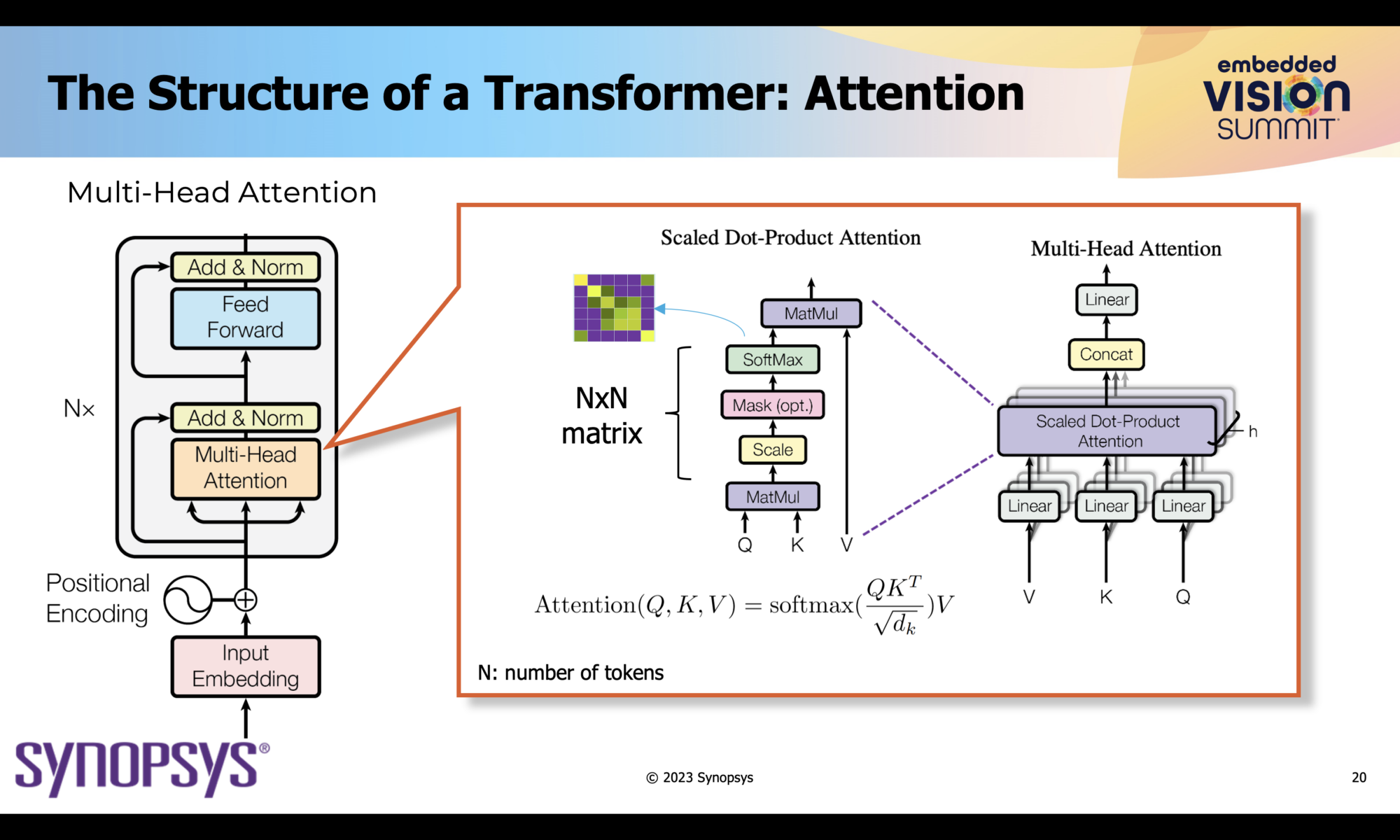

Over the last few years, transformers have been fundamentally changing the nature of deep learning models, revolutionizing the field of artificial intelligence. Transformers introduce an attention mechanism that allows models to weigh the importance of different elements in an input sequence. Unlike traditional deep learning models, which process data sequentially or hierarchically, Transformers can capture dependencies between elements in parallel. This makes it possible to train much larger models more efficiently.

While originally developed for natural language processing (NLP), Transformers have started to gain prominence and adoption in a number of different applications. One such application is computer vision, the field that enables machines to interpret and understand visual information from the real world.
Computer vision has evolved over the years, from techniques based on handcrafted features to the recent surge in deep learning models. The advent of deep learning, fueled by the availability of large datasets and powerful GPUs, has revolutionized the field. Deep learning models have surpassed human-level performance in tasks such as image classification, object detection, and image generation. This field has long relied on convolutional neural networks (CNNs) for its deep learning architecture. Researchers have realized that Transformers could be adapted to tackle spatial data too, making it a promising candidate for computer vision applications. This is the context for a talk given at the 2023 Embedded Vision Summit by Tom Michiels, Principal System Architect at Synopsys.
Why Transformers for Vision
Computer vision tasks, such as image classification, object detection, image segmentation, and more, have traditionally relied heavily on CNNs. While CNNs are effective in capturing spatial hierarchies and local patterns in images, Transformers excel at capturing long-range dependencies and global contextual information within an image. This is essential for understanding relationships between distant image regions, making them suitable for complex vision tasks. Transformers process all elements in parallel, eliminating the sequential nature of CNNs. This parallelization significantly accelerates training and inference times, making large-scale vision models more feasible. Transformers can be scaled horizontally by adding more layers and parameters, allowing them to handle a wide range of vision tasks. They can be scaled vertically to handle larger or smaller input images for image classification to fine-grained object detection. Vision tasks often involve multiple modalities, such as images and text. Transformers are inherently multimodal, making them suitable for tasks that require understanding and reasoning about both visual and textual information. This versatility extends their applicability to areas like image captioning and visual question answering.
Transformers also tend to produce more interpretable representations compared to some other deep learning models. The attention maps generated by Transformers provide insights into which parts of the input are weighted more for making predictions. This interpretability is invaluable for debugging models and gaining insights into their decision-making processes.
Applications of Transformers in Computer Vision
Models like DETR (DEtection TRansformer) have demonstrated remarkable performance in object detection tasks, outperforming traditional CNN-based approaches. DETR’s ability to handle variable numbers of objects in an image without the need for anchor boxes is a game-changer. Transformers have shown significant promise in semantic and instance segmentation tasks. Models like Swin Transformer and Vision Transformer (ViT) have achieved competitive results in these areas, offering improved spatial understanding and feature extraction. Transformer-based models, such as DALL-E, are capable of generating highly creative and context-aware images from textual descriptions. This has opened up new opportunities for content generation and creative applications. Last but not least is that Transformers can generate descriptive captions for images, enriching the accessibility of visual content.
Hybrid Models
While ViTs are excellent in image classification and beat CNNs in accuracy and training time, CNNs beat ViTs in inference time. While Transformers are more helpful for recognizing complex objects, the inductive bias of a convolution is more helpful for recognizing low level features. Training large scale Transformer models for computer vision often requires extensive datasets and computational resources.

As such, a vision processing application may utilize both CNNs and Transformers for greater efficiency. Combining the strengths of Transformers with other architectures like CNNs is a growing area of research, as hybrid models seek to leverage the best of both worlds.
Synopsys ARC® NPX6 NPU IP
The Synopsys ARC® NPX6 NPU IP is an example of an AI accelerator that can handle CNNs and transformers. It leverages a convolution accelerator for matrix-matrix multiplications, as well as a tensor accelerator for transformer operations and activation functions. The IP delivers up to 3,500 TOPS performance and exceptional power efficiency of up to 30 TOPS/Watt. Design teams can also accelerate their application software development with the Synopsys ARC MetaWare MX Development Toolkit. The toolkit provides a comprehensive software programming environment that includes a neural network software development kit and support for virtual models.
To learn more, visit the product page.
Summary
The surprising rise of Transformers in computer vision spotlights a significant shift in the field’s landscape. Their unique capabilities, including the attention mechanism, parallel processing, and scalability, have challenged the dominance of CNNs and opened up exciting possibilities for computer vision applications. They offer unparalleled versatility and performance across a wide range of tasks, transforming how we interact with visual data. As researchers continue to refine and adapt Transformer models for vision tasks, we can expect further breakthroughs that will lead to smarter, more capable vision systems with broader real-world applications.

Also Read:
Power Analysis from Software to Architecture to Signoff
WEBINAR: Why Rigorous Testing is So Important for PCI Express 6.0
Synopsys Expands Synopsys.ai EDA Suite with Full-Stack Big Data Analytics Solution
Share this post via:



Comments
One Reply to “Transformers Transforming the Field of Computer Vision”
You must register or log in to view/post comments.