

Earlier this year, Achronix made a product announcement about shipping the industry’s highest performance Speedster7t FPGA devices. The press release included lot of details about the architecture and features of the device and how that family of devices is well suited to satisfy the demands of the artificial intelligence (AI) era. Emerging applications of the AI era rely on data intensive compute capability and zero latency to make real time decisions.
An earlier blog went into details highlighting the many benefits of using Speedster7t FPGA devices. That blog gave some insights into how the Speedster7t family of FPGAs offers a way to solve long standing chronic semiconductor chip problems. It explained how the lines between computing, communications and consumer market segments have faded to give rise to a number of smaller market segments. And how the requirements for each market segment were primarily driven by the use case the chips were to be deployed for. And how the Speedster7t devices offer the best attributes of the processor, ASIC, ASSP and traditional FPGA technologies.
With the markets moving toward an AI driven, edge-centric, fast-changing, data-accelerated product space with short life cycles, the stage is set for innovative efficient solutions to fill the demand. This blog covers the salient points garnered from a whitepaper that presents a Speedster7t-based solution for a Graph Neural Network (GNN) accelerator.
Machine Learning Algorithms and Data Complexity
Applications such as image classification, speech recognition and natural language processing involve operations on Euclidean data with a certain size, dimension and orderly arrangement. “Euclidean data” is data that can be modeled in n-dimensional linear space. Traditional machine learning (ML) algorithms work fine for these applications but not for many other applications that deal in non-Euclidean data such as graphs. Non-Euclidean data is complex as it contains not only the data but also the dependencies between the data elements. Social networks, protein molecular structures, and e-commerce platform customer data are examples of non-Euclidean data.
In order to handle this increase in data complexity, new graph-based machine learning algorithms or graph neural networks (GNNs) models are emerging at a fast rate from academia and industry alike.
GraphSAGE Algorithm
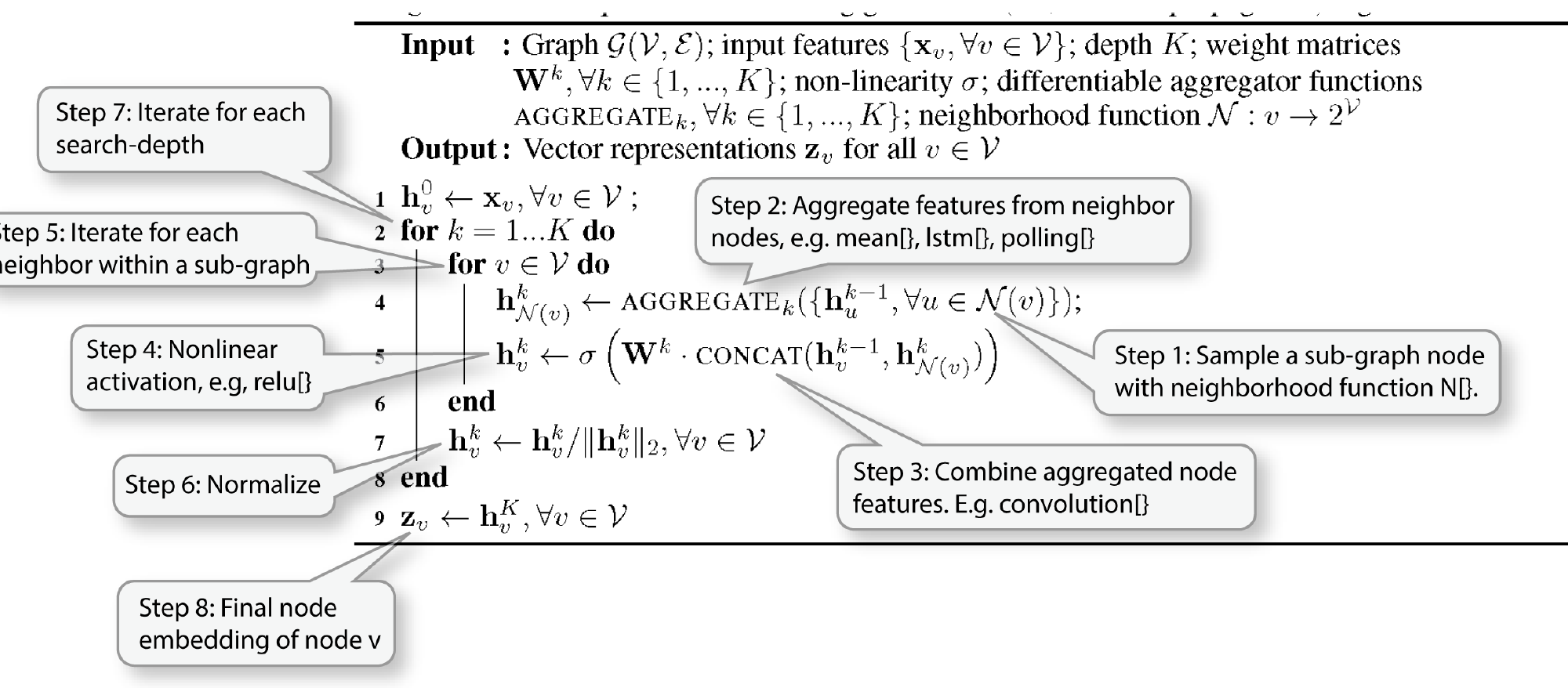
GraphSAGE is an algorithm proposed by Stanford University as a way to arrive at a GNN data acceleration solution. The algorithm involves three main steps. The first step involves sampling of adjacent nodes in a graph. To limit complexity, this step is generally limited to sampling only two layers deep. The second step is aggregation of feature information from the adjacent nodes. And the third step is the predicting of the target node label.
Mathematical Model of GraphSAGE Algorithm (Source: http://snap.stanford.edu/graphsage)

As can be seen from the mathematical model, the algorithm involves a large number of matrix calculations and memory access operations. An x86 architecture-based implementation will be very inefficient in terms of performance and power consumption. A GPU may improve the performance per watt metric compared to a CPU implementation but the solution will still fall short on the performance level needed for real-time calculations of a graph.
A better GNN data acceleration solution is needed to execute real-time applications that operate on non-Euclidean data. The solution should support highly concurrent, real-time computing, huge memory capacity and bandwidth and scalable.
GNN Accelerator Design Challenges
Research has thrown light on the characteristics of the aggregation and merge operations involved in executing the GNN algorithm. Refer to table below. It can be seen that the two types of operations have completely different requirements.
Comparison of Aggregation and Merge operations in the GNN algorithmSource : https://arxiv.org/abs/1908.10834

FPGA Design Scheme of GNN Accelerator
Based on the differences in requirements for performing the aggregation and merging operations, it makes sense to design two different hardware structures in the GNN core of the accelerator design to handle these respective operations.
The extensive set of features included in the Speedster7t1500 FPGA make it easy to overcome the challenges faced in implementing GNN accelerator solutions. As indicated earlier, the Achronix Speedster7t family of high-performance FPGAs is optimized to eliminate performance bottlenecks found in solutions based on CPUs, GPUs, ASICs, ASSPs and even traditional FPGAs. For the full set of features and details of the architecture, refer to the product page at Speedster7t-fpgas. The following table gives a high-level mapping of how the Speedster7t1500 meets the GNN design challenges.

Summary
The whitepaper explains how the unique features provided by the Achronix Speedster7t AC7t1500 FPGA devices lend themselves to creating a highly scalable GNN acceleration solution that can deliver excellent performance. For all the details covered in the whitepaper, you can download here. For more details about the Speedster7t FPGA family, go to the product page at speedster7t-fpgas.
Share this post via:




Solving the EDA tool fragmentation crisis