
I’ve always been intrigued by Synopsys’ Certitude technology. It’s a novel approach to the eternal problem of how to get better coverage in verification. For a design of any reasonable complexity, the state-space you would have to cover to exhaustively consider all possible behaviors is vastly larger than you could ever possibly exercise. We use code coverage, functional coverage, assertion coverage together with constrained random generation to sample some degree of coverage, but it’s no more than a sample, leaving opportunity for real bugs that you simply never exercise to escape detection.
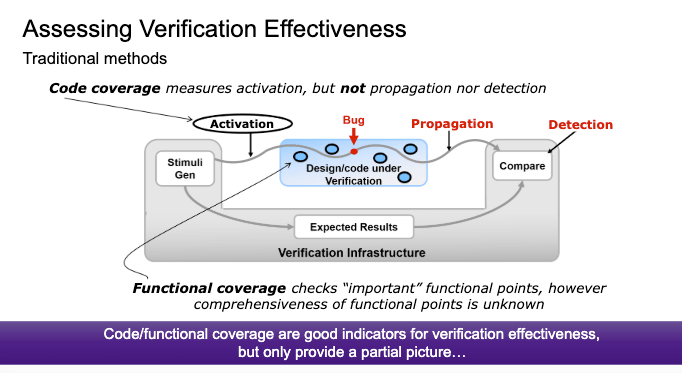
There’s lots of research on methods to increase confidence in coverage of the design. Certitude takes a complementary approach, scoring the effectiveness of the testbench in finding bugs. It injects errors (one at a time) into the design, then determines if any test fails under that modification. If so, all is good; the testbench gets a high score for that bug. Example errors change the code to hold a variable constant, or force execution on only one branch of a condition or change an operator.
But if no test fails on the modified design, the testbench gets a low score for that bug. This could be due to problems in activation; where no stimulus generated reached the bug. Or it could be a propagation problem; the bug was exercised but its consequences never reached a checker. Or it could be a detection bug; the consequences reached a checker, but it was inactive or incomplete and didn’t recognize that behavior as a bug.
Certitude works with both RTL and software models, and for RTL works with both simulation and formal verification tools. Here I’ll talk about RTL analysis since that’s what was mostly covered in a recent webinar, presented by Ankur Jain (Product Marketing Mgr) and Ankit Garg (Sr AE).
What sort of problems does Certitude typically find in the field? Some of these will sound familiar. Detection problems through missing or incomplete checkers/assertions, and missing or incomplete test cases, for example a disabling control signal in simulation or an over-constraint in model checking. These are problems that could be caught in simulation or formal coverage analysis (eg formal core checks). That nevertheless they were caught in Certitude suggests in practice those checks are not always fully exploited. Certitude at minimum provides an additional safety net.
What I found really compelling was the class they say they most commonly encounter among their customers. They call these process problems. Imagine you build the first in a series of designs where later designs will be derived from the first. You’re planning to add support for a number of features but those won’t be implemented in the first chip. But you’re thinking ahead; you want to get ready for the derivatives, so you add placeholder checkers for these planned features. These checkers must be partly or wholly disabled for the first design.
This first design is ultimately successfully verified and goes into production.
Now you start work on the first derivative. Verification staff have shuffled around, as they do. The next verification engineer takes the previous testbench and works on upgrading it to handle whatever is different in this design. They run the testbench, 900 tests fail and 100 tests pass. They set to work on diagnosing the failures and feeding back to the design team for fixes. What they don’t do is to look at the passing test cases. Why bother with those? They’re passing!
But some are passing because they inherited checks from the first design, which were partially or completely disabled. Those conditions may not be valid in this derivative. You could go back and recheck all your coverage metrics on the passing testcases, potentially a lot of work. Or you could run Certitude, which would find exactly these kinds of problem.
In the Q&A, the speakers were asked what real design bugs Certitude has found. The question is a little confused because the objective of Certitude is to check the robustness of the testbench, not to find bugs. But I get the intent behind the question – did that work ultimately lead to finding real bugs? Ankit said that, as an example, for one of their big customers it did exactly that. They found two testbench weaknesses for a derivative, and when those were fixed, verification found two real design bugs.
You can watch the webinar by registering HERE.
Share this post via:



Comments
2 Replies to “How Good is Your Testbench?”
You must register or log in to view/post comments.