Rajesh Vashist is SiTime’s Chairman and Chief Executive Officer and has served in this role since September 2007. Prior to joining SiTime, Mr. Vashist served as CEO and chairman of the board of directors of Ikanos Communications, Inc., a semiconductor and software development company, from July 1999 to October 2006. Mr. Vashist led the organization from a two-person pre-revenue startup to a public company with 90% market share and a market value of $600M. Prior to Ikanos, Mr. Vashist served as a general manager of a $450M business unit at Adaptec, a storage company, and held various general management and marketing positions at Rightworks, an ERP software company, Vitelic Semiconductor and Samsung Semiconductor.
Tell us about your company.
Precision Timing is the heartbeat of modern electronics. Whether it’s in AI data centers, networking infrastructure, automated vehicles, personal mobility or IoT, nothing works without precise timing. In today’s connected intelligence era, SiTime’s uniqueness lies in delivering Precision Timing to enable electronic products that are smarter, faster and safer. We are taking a new approach to the highly fragmented timing market, using semiconductor technology and processes to reimagine time. SiTime is the only company that is solely focused on all aspects of timing, from components to systems and software. We are using microelectromechanical systems (MEMS) technology to transform the $10 billion timing market with products that offer higher performance, smaller size, lower power consumption and unmatched reliability. What makes SiTime unique, apart from our Precision Timing technology, is the diversity of applications, products, customers, and our team.
What problems are you solving?
The timing market has been historically fragmented, but with the need for today’s electronics to be faster, always connected, more intelligent, and safer, a differentiated approach is vital. To meet these requirements, electronics are now being deployed in the “real world,” outside pristine environments such as air-conditioned offices. Here, electronic devices are being subjected to environmental stressors such as rapid temperature changes, extreme temperatures, shock and vibration. The incumbent timing technology for the past several decades, quartz, is susceptible to these stressors, which can impact the performance and reliability of intelligent, connected electronics. Our MEMS and analog technologies solve this problem. We deliver Precision Timing solutions that are orders of magnitude more resilient to these environmental stressors and help make electronics smarter, faster, and safer. For example, we are enabling higher timing performance and accuracy in AI data centers and 5G networks, where nanosecond-level synchronization is required, even in the presence of environmental stressors.
Our semiconductor-based MEMS technology enables us to offer the smallest size, more features, and higher stability, which, again, meets the requirements of modern electronics. With our fabless semiconductor supply chain and built-in programmability, we deliver better supply reliability and the flexibility to configure a device to each customer’s exact application requirements. Over the past decade, we have improved our Precision Timing performance by several orders of magnitude, something that the incumbents have not been able to do. To summarize, we deliver higher performance, more features, higher reliability, smaller size and lower power to our customers.
What application areas are your strongest?
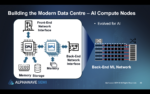
Our strongest markets for Precision Timing include AI data centers and all the networking electronics within, communications, automotive safety and infotainment, IoT, and aerospace and defense. Specific applications within these markets include 800G/1.6T optical modules, smart network interface cards (SmartNIC), 5G remote radio units (RRUs), advanced driver assistance systems (ADAS) cameras, radar and LiDAR, smartwatches and low-Earth orbit (LEO) satellites. For example, AI networking requires ultra-low jitter and latency, which our timing products deliver. Similarly, in autonomous vehicles, Precision Timing is critical for sensor synchronization and rapid decision-making. Our Endura Epoch Platform, for example, is making inroads in aerospace and defense applications, offering unmatched performance and reliability for critical applications such as positioning, navigation and timing (PNT) services. In fact, because of the various benefits of our timing technology, it’s safe to say that we are crucial to the future of electronics.
What keeps your customers up at night?
We’ve realized that we have two kinds of customers: the ones who have experienced and seen the benefits of our programmable timing chips and those who we are working closely with to come up with creative ways to address their timing issues. Our customers are concerned about keeping pace with rapid technological advancements. Whether they’re developing AI, communications, automotive or IoT applications, they must continuously innovate with their products. With the explosion of data-driven applications, companies also worry about achieving low-latency, high-reliability networks, especially as 5G and AI infrastructures continue to scale.
Another point is the ability to meet customers’ needs for scaling fast when the demand for their products increases. SiTime’s silicon manufacturing process ensures a stable, reliable, and independent supply chain with shorter lead times for the highest-quality timing products in the market. Our job is to be inventive and dependable so customers can be comfortable.
What does the competitive landscape look like and how do you differentiate?
After being asleep for so many years and considered a commodity product, timing technology is undergoing a transformation, led by SiTime. Traditional quartz-based timing solutions have been incumbents for the past several decades, but they are rapidly being displaced, given their lack of differentiation and programmability as customers demand smaller, more resilient and reliable, and energy-efficient Precision Timing solutions that our MEMS technology offers. SiTime differentiates itself as the only pure-play silicon timing company, which gives us a unique position to drive innovation in this market. Our programmable clock and oscillator solutions enable customers to tailor their timing devices for specific application needs, a major advantage in high-performance sectors like AI computing and data centers. We also focus heavily on system-level solutions, combining silicon MEMS technology with analog circuitry, advanced algorithms and high-volume packaging, which enables us to deliver unmatched precision, reliability, small size and low power consumption.
What new features/technology are you working on?
As the world becomes more connected and intelligent, we are focused on developing more Precision Timing solutions that meet the demand for stability, resilience, and lower power consumption.
For example, we have design wins with our Precision Timing products in all key applications of the AI ecosystem, including GPU and CPU boards, interconnect switches, optical modules, NIC cards, accelerator cards, active cables, and switches. To provide a sense of scale of our focus on AI, in 2024, we shipped 70 unique part numbers across 14 product families to 30 different customers developing AI hardware.
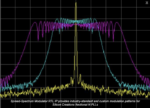
One of our key product innovations for the world of AI is our Chorus clock generator—the industry’s first integrated clock system-on-a-chip (ClkSoC) designed for AI data center applications. The Chorus ClkSoC integrates a clock IC, a silicon MEMS resonator, and oscillator circuitry into a single chip. By integrating the resonator and eliminating the need for external quartz crystal devices, Chorus simplifies system clock architectures for AI systems, accelerates design time by up to six weeks, and improves reliability and resilience. Chorus clocks are engineered to deliver 10 times better performance in half the size of equivalent quartz-based devices.
Another recent innovation is the Endura Epoch Platform, a ruggedized MEMS-based oven-controlled oscillator (OCXO) that provides significant improvements in size, weight, and power (SWaP) while delivering benchmark timing performance for AI data centers and 5G infrastructure. Epoch OCXOs solve critical timing issues that were previously insurmountable with quartz technology, especially when deployed under extreme environmental conditions. We’re also expanding the use of MEMS technology in emerging markets like aerospace and defense with our Endura Epoch Platform, which offers enhanced performance and resilience for critical PNT services.
How do customers normally engage with your company?
We collaborate closely with each customer’s technical team to design and deliver Precision Timing solutions that meet their unique application needs. This collaborative, system-level approach allows us to build deep, long-lasting relationships with industry leaders and ensures that our timing technology continues to meet their evolving requirements. We also engage with our customers’ commercial teams to ensure adequate supply and other business terms. In addition to the large players in electronics, we also support smaller players who might be developing new applications, devoting equal attention to their developments.
How do you see Precision Timing evolving in the future, and what role will SiTime play in that transformation?
Precision timing will become even more critical as the world continues to embrace AI, 5G-Advanced and 6G communications, automated driving, personal mobility, and IoT. We’re not only addressing today’s timing technology needs but also anticipating future demands. SiTime will continue to innovate in the areas of MEMS technology, analog circuits, packaging, integration, and software to develop Precision Timing solutions that push the boundaries of what’s possible. We envision a world where SiTime’s Precision Timing products are embedded in every critical application, from the cloud to the edge, enabling faster, smarter and more connected systems everywhere.
Also Read:
CEO Interview: Dr. Greg Newbloom of Membrion
CEO Interview: Sandeep Kumar of L&T Semiconductor Technologies Ltd.