The storage market has reached what Andy Grove once described as “…a strategic inflection point.”[1] This is the stage in the life of a business when its fundamentals are about to change.
Changing fundamentals in the storage market—where solid state drives (SSD) are now at the forefront of multiple storage applications, from enterprise-based datacenters to PCs—create both great opportunities and significant challenges. Both arise from new technical innovations, emerging standards, and the desire to reach higher performance, increase storage capacities, and meet the needs of system-level infrastructures—all at a lower cost per device.
Delivering solutions for these challenges are where the Mentor Veloce® emulation platform demonstrates its strength as the hub of a sophisticated and comprehensive functional verification solution. One that gives design teams a catalyst to differentiate their enterprise storage devices that use SSD and NAND technologies.
Emulation can verify the hundreds of millions of gates and multiple protocols now seen in SSD controllers along with the complex software that drives them. It has the speed to support full-chip hardware/software co-verification so that the RTL IP and software specific to a particular SSD controller can be verified together.
Many protocols are still widely used in storage systems today (including SATA, SAS, PCIe, and NVMe). SSD device manufacturers need an emulation tool kit that offers solutions for them all. The Veloce emulation platform is without peer in this regard. Veloce provides in-circuit emulation (ICE) components (iSolve), virtual models (VirtuaLAB), and a unique new application (Veloce Deterministic ICE) to verify the design using the chosen host interface. Veloce also provides all the NAND, DDR, and NOR models used in conjunction with the SSD controller and software.
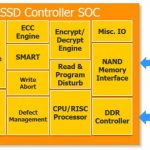
Figure 1: SSD controller architecture.
The Veloce iSolve library offers a full complement of hardware components to build a robust in-circuit emulation (ICE) flow, which is needed for many SoC verification scenarios.
The Veloce Deterministic ICE App complements and extends the usability of an ICE-based environment by delivering a repeatable and virtual debug flow. In addition to offline SW debug, the Veloce Deterministic ICE App enables advanced debug capabilities, power analysis, and coverage closure methodologies.
And the Veloce VirtuaLAB environment represents a new-generation of verification solutions delivering high-speed verification for multiple host protocols and memory devices, HW/SW system-level debug, power analysis, and system performance analysis.
SSD on ICE
When an SSD SoC design needs to be connected to real devices or custom hosts, the DUT (instantiated in the emulator) must be connected to physical hardware. In this case, teams use an emulation platform to set up the test environment by connecting the required peripherals/hosts using speed adapters/bridges to communicate with the SoC design mapped to emulator. Software teams make use of the ICE environment for firmware development and to run real applications. Verification teams use it to exercise various test methods to interact with the interfaces to verify the functionality of their SoC designs. Most designs today have an embedded CPU, and ICE is used for testing the OS boot cycles as well. ICE is also used for connecting proprietary hardware or proprietary operating systems (OS) to reproduce issues found in prototype or in a post-silicon lab setup.
Making ICE Repeatable
There are significant challenges in using ICE in certain scenarios, many of which are found in SSD verification. These include limitations on trace depth, long and iterative debug cycles, random and asynchronous events, and inflexibility in how the emulator can be deployed and shared. In addition, advanced verification techniques, such as power estimation, are not the best fit for a traditional ICE environment.
The Veloce Deterministic ICE App addresses these challenges by creating a virtual debug model of an ICE run. Significantly, it adds determinism to the debug environment by making the test run repeatable cycle-by-cycle. It does this by generating a replay database to re-run or repeat the same test without the need for hooking up to ICE targets.
Figure 2: ICE run.
Figure 3: Using the replay database without ICE targets.
While in replay mode, a user can choose to dump waveforms for an entire design for the duration of a test, or activate various other debug features (like live monitoring of important signals using streaming waveforms, enable displays, and protocol monitors), or do both. Having the ability to stop and inspect both data and full waveforms provides a rich debug platform and increased productivity in addition to efficient use of emulation resources.
The Veloce Deterministic ICE App makes the test environment portable to other emulators or teams located in different places as the test is no longer dependent on the external ICE hardware. It also gives the flexibility to use other Veloce Apps like power analysis, SW debug, coverage, and assertions that would not have been feasible without this technology.
The Virtual Lab
Virtualization is the game changer for enterprise verification. Virtualization, which Mentor pioneered almost 10 years ago, allows emulators to be moved to centralized data centers to establish company-wide virtual platforms that support multiuser, software-driven SoC verification in a 24/7 enterprise server environment. Verification engineers can now access an emulator from their desktop, even from remote locations thousands of miles away from the emulator.
Peripherals are virtualized via the Veloce VirtuaLAB environment. VirtuaLAB provides the same host interfaces as iSolve, including NVMe, but instead of using external hardware that must be cabled to the emulator, VirtuaLAB uses software protocol models. And, as VirtuaLAB uses the same IP as in ICE solutions, so it delivers the same functionality as iSolve hardware peripherals.
Importantly, VirtuaLAB delivers emulation performance equivalent to that of ICE, making it an attractive alternative that is better suited to multiple users and applications.
VirtuaLAB allows an SSD controller designer to run and debug the same software applications in the VirtuaLAB environment as they would on the real hardware. VirtuaLAB also eliminates the need for hardware speed adapters/bridges, and supports third-party performance analysis and power analysis applications. This means designers can do all of the same statistics, analysis, and metrics that they would do on the real design, but it’s done pre-silicon.
The Best of Both Worlds
With the Veloce emulation platform, verification teams have access to the best of both worlds—ICE and virtual emulation—powered by the world’s most versatile and flexible emulation technology.
The Veloce emulation platform is radically recasting the emulation landscape, making emulation friendlier and more useful, while delivering all of the speed, visibility, and performance of traditional ICE-based emulation. The Veloce emulation platform is uniquely built with highly scalable hardware, an extensible operating system, proven virtual solutions, and a growing library of apps that solve application-specific verification challenges.
To learn more about the rise of SSD technology and Mentor’s emulation solutions for storage system designs, check out the new whitepapers Veloce Delivers Best of ICE and Virtual Emulation to the SSD Storage Market and Using the Veloce Deterministic ICE App for Advanced SoC Debug.
[1]Only the Paranoid Survive, Andy Grove, Crown Publishing Group, May 5, 2010