When I was young, functional safety for automobiles consisted of checking tread depth and replacing belts and hoses before long trips. I’ll confess that this was a long time ago. Though even not that long ago, the only way you found out about failing systems was going to the mechanic and having them hook up a reader to the OBD port. Or, worse you found out when the car stopped running or a warning light came on. A lot has changed with the advent of ISO 26262 which defines the standard for automotive electronic system safety.
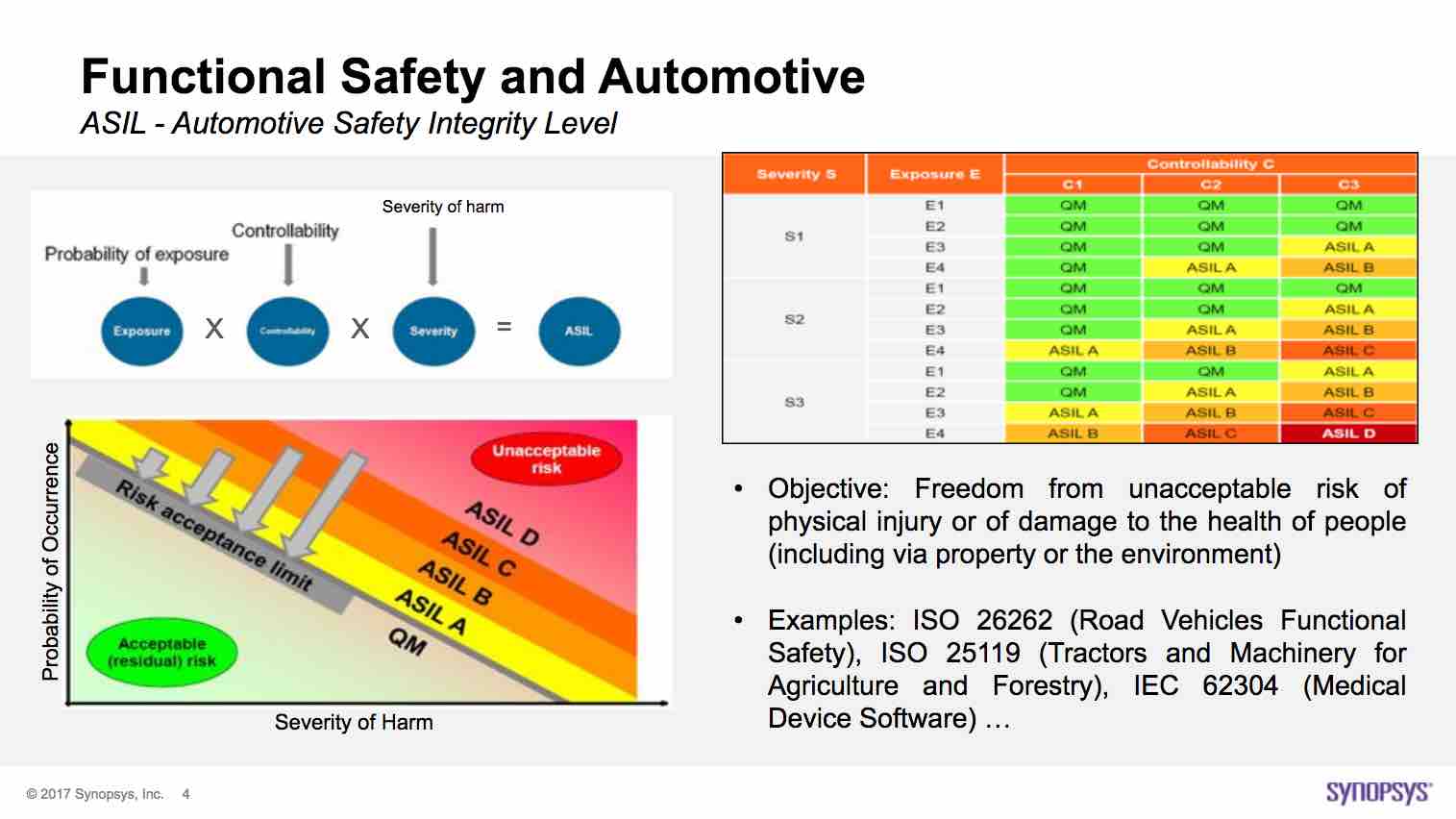
The most critical systems, which are designated as Automotive Safety Integrity Level (ASIL) D, have many requirements imposed on them to ensure high reliability. This applies to systems where a failure could lead to death or serious injury, e.g. ADAS systems. It is easy to understand that these systems must be carefully designed and documented. While this is true, the safety requirements extend into ensuring that these systems can self-check at startup and also continuously monitor their own health. In fact, ISO 26262 requires that every block in these systems must run a self-test every 100 milliseconds during operation. This can include fault injection too. In effect, it is now necessary to “check the checkers”.
Even the scope of the functional safety self-monitoring tests is impressive. For instance, in the case of memories, in addition to requiring ECC on data, addresses are also protected by ECC. SOC designers for automotive applications are now faced with not only building the system they have specified, they need to build in extensive new on-chip functionality to ensure functional safety that meets the ISO 26262 standard. This process is somewhat familiar to designers, who have been adding BIST and Scan test functionality into their designs for decades.
Fortunately, similar to the model for BIST and Scan, there are commercial IP based solutions and tools chains that address the needs arising from these dramatic changes in system testing. Synopsys has long been a player in both the IP and test markets. It is only natural that they extend and adapt these offerings to create a combined and comprehensive solution. They have done the work to make their solution ISO26262 ASIL-B through ASIL-D ready.
There is a very informative video presentation that gives an overview and then goes into detail on the Synopsys functional safety offerings along with specific customer experience from Bosch in the application of STAR Memory System (SMS) and STAR Hierarchical System (SHS). The presenters are Yervant Zorian, Synopsys Fellow & Chief Architect, and Christophe Eychenne, Bosch DFT Engineer. In the first half, the very knowledgeable Yervant covers the requirements of ISO 26262 systems and then outlines the offering from Synopsys. In the second part Christophe goes through a case study from Bosch.
Here are a few of the interesting things I learned from this video. In the case of memories, each memory is given a wrapper that can perform testing and then implements memory repair. The repair information is saved and reloaded at start up, However, an additional test is performed at every start to fully check each memory. This helps manage aging in memories. Soft error correction in memories is complicated in newer process nodes because of the increased likelihood of multi-bit errors. The SMS is aware of memory internal structure and this helps in error detection and correction.
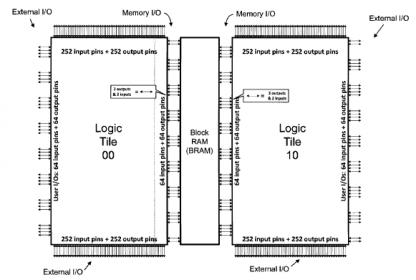
The SHS wraps interface and AMS blocks, and connects to a sub-server using IEEE 1500. The wrapped memories are tied together using the SMS processor and all of these elements and the digital IPs with DFT scan are then connected to a server which offers the traditional TAP interface. In addition, there are external smart pins that can be used to quickly and easily initiate tests without needing a TAP interface controller. As an added bonus, this entire system can be used to facilitate silicon bring up using with the Synopsys Silicon Browser.
Back when we were changing hoses and belts for long trips, Synopsys was just an EDA tools company. But, like I said, that was a long time ago. Synopsys has evolved and developed impressive and sophisticated offerings in IP, which now includes many of the essential elements to build SOCs and systems for safety critical automotive systems. The video presentation is available on the Synopsys website, if you would like to get the full story behind their latest work in this area.