We already know that IP-Xact is extremely useful for managing IP and SOC design specifications, yet it may come as a surprise to learn that it also can be used to form the basis of a power flow too. There are design tools that read UPF to help implement and verify designs, however it can be extremely useful to understand the interplay between the power intent and the fully elaborated design early in the flow.
First off, let’s back up and talk about how designs with multiple power and voltage domains are specified. In theory, and often in practice, the RTL for a design provides no guidance for power domains or voltage domains. Of course, there may be a mode controller in the RTL, or the design might be completely power agnostic. Certainly, the RTL will not have information about signal levels between blocks or information about implementation of the power nets. This is where UPF comes in.
UPF works in conjunction with the RTL to fully define the details of the supply connections and the signals that cross domains. Power and ground nets may be connected or disconnected to save power in certain operating modes. Signals may need level shifting, and isolation or retention when blocks switch off. UPF is based on the logical hierarchy, which is available in a fully elaborated design.
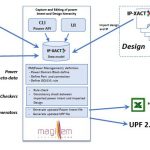
Writing UPF directly can be a daunting task. Magillem, a leading provider of IP-XACT solutions, saw a way that IP-XACT and power intent can be combined to make specification of power intent easier, and used to check for issues before moving into the implementation phase. IP-XACT already provides a way to create, manage and elaborate an RTL design, by capturing information for the hierarchy, block interfaces, buses and signals. Magillem realized that tabular input through csv files is an ideal way to specify power domains, voltage domains, power states, isolation rules and level shifter rules. These can be applied to the fully elaborated design to create a complete specification.
Using this flow mismatches between the power intent and the design can be easily detected. Magillem has also implemented checkers for missing level and isolation elements. Propagated power properties are reported, as well as any warning or errors. Their IP-XACT power flow provides verbose reports to provide easy traceability. Magillem’s power flow outputs a domain based virtual hierarchy and offers visualization so that it is easy to understand the domain partitioning. Then in the final step it outputs UPF 2.0 for use downstream in the design flow.
Mistakes in specifying power intent can be fatal and navigating through reams of UPF looking for issues can be frustrating. Magillem makes the entire process easier by letting the designer work on the fully elaborated design and get a clear picture of what domain each instance is in. Magillem’s power flow can ensure that there are no missing level shifters. It also can help ensure that level shifters, isolation and retention are in all the necessary locations. While UPF provides a nice partitioning between design and power specification, it’s good to know that Magillem’s power flow offers a high-level solution for integrating and verifying them early in the design process.