You are currently viewing SemiWiki as a guest which gives you limited access to the site. To view blog comments and experience other SemiWiki features you must be a registered member. Registration is fast, simple, and absolutely free so please, join our community today!
Dan and Mike are joined by Malcolm Penn, 50-year semiconductor industry veteran and founder and CEO of Future Horizons. Dan and Mike explore the evolution of the semiconductor supply chain, how we got to the current state of shortages and what the future may hold. Drawing on his substantial knowledge of the industry, Malcolm makes some enlightening comments about the industry and what may lie ahead.
The views, thoughts, and opinions expressed in these podcasts belong solely to the speaker, and not to the speaker’s employer, organization, committee or any other group or individual.
The semiconductor shortage has really caught the world’s attention. Friends and family who don’t really know what a semiconductor is now ask me to explain it. This is great news for the semiconductor industry for different reasons which I will discuss here. We can also discuss the downside risks.
First, let’s look at a bit of semiconductor history. Malcolm Penn of Future Horizons did his “IFS2021-MT” Mid-Term Semiconductor Industry Update & Forecast” which was definitely worth an hour of my time. Malcolm went through 237 slides in that hour which he shared with me. This one is my favorite:
I’m a big fan of history, we really need to understand how we got to where we are today to better understand where we will go tomorrow. The takeaway here is that the semiconductor industry has weathered storms like this in the past and will continue to do so in the future. In fact, Malcolm said that this is the 14th such event in his 50 years.
Malcolm joined us for a Semiconductor Insiders Podcast, you should also catch last week’s episode with Wally Rhines. We discuss the history of TSMC and a few other topics including the current semiconductor shortage.
After listening to Malcolm’s take on the semiconductor shortage I took a close look at the supply chain from wafer to packaged parts to finished electronic products. I talked to colleagues and attended multiple calls with industry experts. We do not have a semiconductor manufacturing problem, it’s a supply chain problem and that problem is not limited to semiconductors, it’s hitting many sectors and will continue to do so for many quarters to come.
Bottom line: COVID and climate change have devastated the worldwide supply chain. I mentioned a while back that I noticed a growing number of ships backed up in the San Francisco Bay and out the Golden Gate. The word on the docks is that not only is COVID causing personnel shortages but COVID protocols are killing productivity. The airline industry is facing a different kind of personnel issue. In addition to COVID complications, pilots are aging out and they can’t hire and train replacements fast enough.
Unfortunately, the dominant narrative led by Intel and others, including politicians, is that we need more fabs and those fabs need to be in the country of demand origin. This really started with China a few years ago with the Made in China 2025 strategic plan. As a result, China has bought massive amounts of semiconductor equipment over the past few years. Unfortunately, the majority of this equipment sits idle for the time being. When it does in fact get into high volume production China will become somewhat self sufficient with their massive semiconductor consumption which will add to the coming semiconductor glut, absolutely.
But please do build more fabs all over the world and try to replicate the entire semiconductor supply chain many times over. It will be an exercise in futility but we all need exercise. The end result of course will be a glut and that means lower prices which will bring about a whole new generation of semiconductor products and services. All for the greater good of semiconductors and modern life, I’m looking forward to it!
On Sep 20th, Synopsys announced an expansion of its DesignWare® ARC® Processor IP portfolio with new 128-bit ARC VPX2 and 256-bit ARC VPX3 DSP Processors targeting low-power embedded SoCs. In 2019, the company had launched a 512-bit ARC VPX5 DSP processor for high-performance signal processing SoCs. Due to the length, format and style, press releases are limited in what they capture. Typically, there is a story behind every product announcement. Learning this story gives us better insights into the announced products.
In order to gain these insights, I had a meeting with Matt Gutierrez, Sr. Director of Marketing, Synopsys Processor Solutions, Markus Willems, Sr. Product Marketing Manager, ARC VPX DSP Processors. This blog is a synthesis of what we discussed.
Unwavering Focus on Embedded Applications
One thing that has been steady and constant from the 1990s to today is ARC technology’s focus on supporting embedded applications. Historically, ARC processors did not target the mobile applications processor segment. The markets for embedded applications have been evolving and ARC processor technology has been transforming accordingly. ARC processors have moved up from being used for just simple and dedicated tasks such as power management to even running 64-bit Linux operating system.
After becoming part of Synopsys in 2010, the burgeoning IoT market gave impetus to build a new generation of embedded ARC processors. A family of very small, highly efficient, low-power processors was need to support the IoT market. A new architecture and ISA were born. A couple of processors were developed and marketed. Early IoT devices needed minimum amount of DSP capabilities. Some DSP functions were added to the processors to support the IoT requirements.
Fast forward to today, Synopsys offers five different ARC product families, each with extensive lineups. Each product family of embedded processors addresses the varying and tight requirements of a broad range of applications. The current announcement is about their VPX DSP family of processors for Language processing, Radar/LiDAR, Sensor Fusion and High-end IoT applications.
Focus Drives Highly Efficient ARC Architecture
The instruction set architecture (ISA) has been designed with the embedded market in mind. For example, unique instructions such as compare & control transfer and branch & loop make it easy to efficiently implement common embedded program behaviors. Another example is 16-bit encodings for popular 32-bit instructions. The ARC ISA has many such features for reducing code size as memory space is at a premium on embedded devices.
Every microarchitectural decision is also made with the embedded market in mind. For example, built-in shadow registers are important for real-time embedded applications to enable fast context switching. These kinds of architectural decisions make a big difference for embedded applications. Something not easily replicated by taking a processor designed for some other applications and tweaking it to support embedded applications.
Other important aspects of ARC’s value proposition are the configurability of the design and the extensibility of the instruction set. Configurability enables implementing just the minimum hardware that is needed for a SoC and nothing more. Extensibility enables adding custom instructions to accelerate application code, increase code density and reduce power consumption.
Customers are effectively able to create customized processor hardware, supported by a singular, standard MetaWare toolchain, that delivers the optimal PPA and code density for their application needs. The majority of ARC customers extend the instruction set by adding custom instructions for their specific algorithms.
Addressing Expanding Market Requirements
Until the introduction of the VPX family of processors, ARC processors could be categorized as Big CPU, little DSP IP solutions. Embedded workloads such as IoT sensor fusion, Radar and LiDAR processing, voice/speech recognition, and natural language processing call for full-fledged DSP capabilities. As Synopsys saw this rising market need, they launched the VPX line of processors, which uses an extended ARC ISA to implement highly vectorized DSPs.
Product Requirements for these Markets
Floating point support is becoming more important for signal processing applications. The data processing algorithms being developed for these markets use floating point to support a wide dynamic range. Staying in floating point instead of converting to fixed point makes mapping an algorithm to a design architecture quicker. The DSP libraries and linear algebra libraries that are supporting these applications are represented in floating point format. Strong support for programming with vector floating point operations is becoming more of a requirement than in the past.
Efficient execution of AI algorithms is another must-have for any modern DSP. This implies support for short Integer datatypes such as Int8, combined with a dedicated programming environment that allows for a smooth mapping of graphs to the DSP architecture. And of course, the DSP has to come with a rich library of machine learning kernels optimized for the hardware to ease software development.
A dedicated hardware accelerator for linear and non-linear algebra operations significantly speeds up these increasingly used math functions.
Configurability, extensibility and scalability are becoming key requirements as product companies start offering multiple variants. Each variant may be optimized differently for PPA and code density.
VPX Family of DSP IP
With the availability of three different VPX families representing 7 different DSPs, customers now have greater flexibility for implementing specific application requirements. The latest two additions are based on the same VLIW/SIMD architecture as the higher-performance 512-bit ARC VPX5 DSP processor launched two years ago. As the new additions target low-power embedded SoCs, they are designed for smaller vector lengths, resulting in smaller, lower power footprints. As ultra-high floating-point performance is a focus for the VPX DSPs, a Vector Floating Point Unit (VFPU) is offered as an option. The VFPU is implemented with multiple pipelines capable of executing up to 512 FLOPs per clock cycle. Along with the launch of the two new additions, Synopsys has also announced some enhancements to the VPX5 processor.
Easy Migration and Scalability of Products
The ARC VPX processors are supported by the Synopsys ARC MetaWare Development Toolkit, which provides a vector length-agnostic (VLA) software programming model. From a programming perspective, the vector length is identified as “n” and the value for n is specified in a define statement. The MetaWare compiler does the mapping and picks the right set of software libraries for compilation. The compiler also provides an auto-vectorization feature which transforms sequential code into vector operations for maximum throughput.
In combination with the DSP, machine learning and linear algebra function software libraries, the MetaWare Development Toolkit delivers a comprehensive programming environment.
Together, the above features enable customers to easily migrate and/or scale their products across all members of the VPX family.
Opportunity for Optimizing Current ARC VPX5-based Designs
In all the talk about VPX2 and VPX3 in the press announcement, mention of the VPX5 enhancements may have gotten lost. Refer to Figure below.
The VPX5 enhancements include double-wide vector load/store, wider AXI interfaces, ISA extensions, and machine learning, DSP and linear algebra libraries that support a VLA-based programming model. These enhancements have enabled VPX5 (as well) to double its performance compared to the earlier version for common DSP functions such as FFT, dot product and windowing. In many applications, this removes the need for designers to implement a separate external accelerator for these functions.
For the Automotive Market
To satisfy the enhanced safety requirements of the automotive market, Synopsys offers a functional safety (FS) series for their entire portfolio including the VPX family of processors. The FS series of processors meet random fault detection and systematic functional safety development flow requirements for full ISO 26262 compliance up to ASIL D.
Summary
Delivering design efficiencies, optimizing for PPA and maximizing software code density are at the root of what ARC is about. Synopsys’ ARC VPX DSP family of processors provides customers with a full range of scalable solutions to address their varying requirements.
Verification is a complex task that takes the majority of time and effort in chip design. Veriest shares customer views on what this means. We are an ASIC services company, and we have the opportunity to work on multiple projects and methodologies, interfacing with different experts.
In this “Verification Talks” series of articles, we aim to leverage this unique position to analyze various approaches to common verification challenges, and to contribute to make the verification process more efficient.
As product life cycles are getting shorter, you need to be very effective in your development flow to meet deadlines. What does that mean in terms of design maturity? Since we can never say that the verification is fully complete, I was interested in who and when decides when “enough is enough”: Is there some predefined date? Is it adjustable in relation to the success of the development process?
Even after 10 years of career as a verification engineer, I was very interested to discuss this topic with other respected professionals and get their perspectives. My interlocutors were: Mirella Negro from STMicroelectronics in Italy, Mike Thompson from the OpenHW Group in the Canada and Elihai Maicas from NVIDIA in Israel. We’ve also talked about different sign-off criteria, progress tracking and measuring metrics against the criteria as the development progresses.
How do we set a project timeline?
Everyone agrees that verification completion criteria should be jointly defined by all stakeholders in project.
Mike believes that it should all start from the question “what are our quality goals?” and that primarily depends on the specific project. “For example, many ASIC projects will budget for one metal re-spin before going to production, so the quality requirement of first silicon could be written as ‘no functional bugs that gate sample testing and initial customer testing’. This is still a very high bar, but it is not ‘zero functional defects’”.
Elihai believes it depends on the product application. Although he has worked only on consumer electronics projects, where the tape-out date is usually specified at the beginning, he noticed that in the development of, for instance, medical or automotive devices all stages are much more strictly defined and reviewed. So hopefully these chips are not taped-out until the confidence in the quality is very high.
“This is market driven”, says Mirella. She explains that after the marketing team understands customer demands, they come to the R&D team with a description of the product and technology required. The R&D team then evaluates if that goal is achievable and in how much time. There are two possible scenarios: The first one – this is an innovation; in which case you are usually not limited in time. The second scenario – the product that is currently in demand in the market; here the development makes sense only if your delivery date is aligned with expected customer demand. If you miss a very short window of opportunity, you may miss out the time to sell.
Mirella emphasizes the importance of risk planning and having business continuity plan in place. Risk planning should include both a general risk as well as project-specific risk. Project scope can change because projects are very complex and involve a lot of innovation. But also, you can be completely stuck due to unforeseen circumstances such as a pandemic, a bug in the tool, or the technical leader who left the company.
Sign-Off Criteria
According to Mike, the quality goal should be defined at the start of the project, but the “measurement question” must typically wait until the requirements and/or functional specification is available. And the answer to that question should be more qualitative and usually is a variation of “100% coverage and no test failing”. “There are a lot of re-use opportunities for completion criteria when the projects are in the same domain. For instance, in our case, two different 32-bit RISC-V cores implement the RVIMC instruction extensions. So, the RVIMC completion criteria for these cores are (probably) the same,” he adds.” However, the two cores have very different interfaces to instruction and data memory, so the completion criteria for these aspects are very different. This illustrates why the ‘measurement question’ is gated by the Requirements and/or Functional Specification.”
Elihai’s experience indicates that in most cases there are some “magic” numbers (for example: phase1: 85% code coverage, phase2: 90% code coverage + 90% functional coverage, Tape Out: 95% code coverage + 100% functional coverage) that are passed from project to project, plus some criteria specific to the current project, block, IP. This should all be defined before the development starts. However, he adds: “I never saw that happening. In real life, the specs are constantly being edited as the development progress, and so are the flows and exact numbers (performance for example) that need to be simulated”. “The criteria are defined by the technical managers and project leaders, based on personal experience and legacy criteria used in the team,” Elihai summarizes.
At STMicroelectronics, however, there is a common sign-off criteria for all projects: anything less than 100% of functional and code coverage means there is still work to do. Once reached full coverage and no failing tests, there is still possibility to miss some functional bugs, but it is not that obvious to define better criteria. They try to grant at least what is measurable today by the available tools.
Takeaways
Since the quality criteria depends on the market, competition, budget, I’m not sure that we can or should aim to create common criteria because this dictates the success of the company. Therefore, companies that find themselves less successful comparing to competitors, could revise their approach in this regard. Still, there seems to be a minimum that everyone respects. It is mandatory to have a very high percentage (100% or almost 100%) of all success indicators that can be measured with today’s tools. Also, no one compromises the quality when it comes to the sensitive applications such are medical and automotive devices. There the verification sign-off happens only once all internal and external auditors approve it. On the other hand, in consumer electronic devices some features might be abandoned due to a pressure to meet a deadline.
After understanding what different criteria are and how they were created, in the follow-up article we will look at how you can track the progress and what can cause problems on that way.
To view more about Veriest, please visit our web site.
The shortage of semiconductors for automotive applications is getting worse. Recent statements from major automakers:
General Motors significantly cut production at eight North American plants earlier this month due to the semiconductor shortage. GM expects North American vehicle production in the second half of the year will be down about 100,000 compared with the first half.
Ford Motor has cut North American production of its popular F-150 pickup truck due to the shortage.
Toyota announced on September 10 it will reduce global vehicle products by 70,000 units in September and 333,000 units in October. For its full fiscal year ending March 31, 2022, Toyota expects to produce 9 million vehicles, down from its previous forecast of 9.3 million.
Volkswagen has also cut production and will build 100,000 fewer vehicles in 2021 than planned.
Hyundai Motor cut production at its U.S. Hyundai and Kia plants.
Stellantis, the merger of the Fiat-Chrysler and Peugeot groups, temporarily halted vehicle production at four plants in North America and one in Italy in late August.
At the Munich Motor Show earlier this month, Daimler AG’s CEO Ola Kallenius stated its Mercedes unit will have significantly lower third quarter sales, buts expects its semiconductor supply to improve in the fourth quarter. He expects shortages to influence 2022 auto production, with the industry fully recovering in 2023. Ford Europe chairman Gunnar Herrmann said the semiconductor shortage could continue until 2024. Volkswagen CEO Herbert Diess expects shortages to ease as countries reduce COVID-19 cases, but a general shortage of semiconductors could persist for some time due to demand from other applications such as the internet of things.
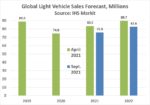
The chart below shows vehicle production by the six largest automakers relative to March 2021, when production was about at pre-pandemic levels. Since March, production has generally been on a downtrend due to semiconductor shortages. SAIC of China fared the best, bouncing back to 92% of March production in August from 66% in July. In June, SAIC Motor Chairman Chen Hong stated his company’s semiconductor supply shortage would be alleviated in late July. In August 2021, GM Group, Hyundai Group and Toyota Group each produced vehicles at about 60% of the March level. VW Group and Stellantis in August were at about 37% of March production.
On September 16, IHS Markit updated its April forecast for global light vehicle sales. The 2021 forecast was reduced by 7.7 million units, or 9%. 2022 was cut by 7.1 million units, or 8%. The April forecast called for 2022 sales of 89.7 million units, up from the pre-pandemic 89.0 million in 2019. The September forecast has 2022 sales at 82.6 million, 7% below 2019 levels. Thus, the automotive market is not expected to fully recover until at least 2023.
Our Semiconductor Intelligence April newsletter asserted automakers were primarily to blame for their semiconductor shortages since they drastically cut production and semiconductor orders while other semiconductor applications were either relatively stable or growing. Another contributing factor was automakers use of Just-In-Time (JIT) inventory management systems. JIT systems are designed to reduce automakers’ parts inventories by working with suppliers to furnish parts just as they are needed for production.
The Wall Street Journal in April 2021 stated many automakers are modifying their JIT systems to have safety stock of critical material such as semiconductors. Raconteur.net proposes automakers move from JIT to just-in-case (JIC). JIC means keeping minimal levels of inventory for critical components. Sourcengine.com points to NXP Semiconductor as an example of a supplier signing medium-term supply contracts with some its automotive customers. It cites DigiTimes prediction automotive semiconductor shortages will not be resolved until the middle of 2022. IHS Markit estimates automotive microcontroller supply will not catch up with demand until 2Q 2022.
Automakers are now realizing the importance of semiconductors. Automotive semiconductors have unique requirements compared to other applications. Many need to operate in extreme temperatures. Devices must often be supplied in high volumes over long time periods. Automakers compete with other major applications such as PCs and smartphones for the more advanced devices such microcontrollers. Automakers generally cannot switch to another semiconductor supplier in the short term. Trends toward electric cars and self-driving cars only make semiconductors even more important. It is time for automakers to think more strategically about semiconductors and not treat them as just another component in a vehicle.
A processor ISA provides an abstraction against which to verify an implementation. We look here at a paper extending this concept to accelerators, for verification of how these interact with processors and software. Paul Cunningham (GM, Verification at Cadence), Raúl Camposano (Silicon Catalyst, entrepreneur, former Synopsys CTO) and I continue our series on research ideas. As always, feedback welcome.
The authors aim with ILA to extend the ISA (Instruction Set Architecture) concept for processors to include accelerators common in most SoCs, providing a unified abstraction for all software-visible compute units in such SOCs. Accelerators are already visible to software for example through memory-mapped IO; ILA adds instruction abstractions to this view. Their goal is to enable scalable software validation against an abstract model of the SoC and a standard abstraction against which implementations can be verified. Generally they aim to reduce verification complexity as architectures expand further in massively multi-core and multi-die systems.
They consider applications to accelerators for image processing, machine learning and cryptography and a RISC-V core. ILAs here are generated either by hand or through a template-based synthesis flow. ILA allows for hierarchical levels in abstraction, to model microcode level complexities like looping and implementation choices like buffering for streaming IO.
The authors use formal methods based on commercial and open-source tools to verify their ILAs. They do this through equivalence checking to compare two different implementations of an ILA (e.g. a specification ILA versus a more elaborated ILA). They also run equivalence checks between ILAs and RTL implementations.
Paul’s view
This is a very thought-provoking paper. The trend towards domain-specific heterogenous compute is unstoppable, fueled in a big part by the AI/ML transformation ongoing all around us.
Traditional CPU design benefits from a rich ecosystem of verification and validation techniques built around formal definitions of ISAs. These ISAs serve as a bridge between the software validation world and hardware verification world. Software is compiled into a sequence of ISA instructions. Hardware processes that ISA sequence in silicon.
In this paper the authors attempt to generalize an ISA beyond general purpose CPUs to any domain specific accelerator. They observe that while accelerators do not literally support an ISA, it is possible to map an accelerator’s MMIO or stream interface to something that looks and feels like an ISA. A key contribution of the paper is a formal definition of this “ILA” generalization such that no matter what concurrency there is in hardware between the CPU and its accelerators, the software world can see a flattened sequential sequence of unified ILA instructions across all compute engines.
The paper is very practical, taking the reader through multiple worked examples of ILAs for accelerators (gaussian blur, recurrent neural network, AES encryption), along with proofs of correctness for RTL implementations of these accelerators to their respective ILAs – nice to see one of the tools they use being JasperGold from Cadence 🙂
I would love to see follow-on papers to showcase worked examples of the other side of ILAs. How they can be used to improve validation of software leveraging multiple accelerators and CPUs. While the way an ISA bridges software and hardware for a CPU is clear, a software program that leverages accelerators does not literally compile into ILA instructions, so the bridge between hardware and software for accelerators using ILAs is less clear to me, and I would appreciate a worked example.
Raúl’s view
The paper is a significant contribution around modeling, not really about innovation in verification, as Paul noted. Verification is based on existing verification tools, the contribution here is methodology and modeling. I think it is fair to note that the human effort involved in the setup (including setup for proofs) seems more significant than run-time and probably requires a high level of expertise. The authors hand-generated some of the ILA models, not so surprising at this stage of evolution. Some they generated through template-based synthesis, checking against reference models (C/C++, SystemC, Chisel, RTL). Though they don’t go into details, I suspect there is significant manual work behind the scenes in finalizing those models. Even the formal verification setup probably requires a lot more know-how and work than detailed in the paper.
In terms of how EDA tools could use ILA in the future, that depends obviously on a usable language / notation. We’d have to look carefully at comparable objectives and adoption rates. Chisel for example is another way to abstract, also using templates; Berkeley used Chisel to build the Risc-V Rocket and Google used it to design an edge TPU. SystemC might be a more interesting reference as a high-level standard which has faced adoption challenges.
This looks like a starting point on a long road, pointed to by future work suggestions. Extensions to concurrency, consistency of shared memory, accelerator code generation and reliable simulator generation for software development are some examples.
My view
While this paper doesn’t demonstrate an application. I did find a related paper, also from Princeton, on application to memory consistency verification. Perhaps we can review that paper in a later blog. I see this paper more as an introduction to the concept. With a demonstration applied to a range of accelerators, rather than a self-contained innovation. Some innovations build on multiple sub-innovations. This is a sub-innovation 😀
My first IR drop analysis was back in the early 1980s at Intel, where I had to manually model the parasitics of the VDD and VSS interconnect for all of the IO cells that our team was designing in a graphics chip, then I ran that netlist in a SPICE simulator using transient analysis, measuring the bounce in VSS and droop in VDD levels as all of the IOs switched simultaneously to keep the power and ground levels within a safe operating region. On another occasion in 1980 I was debugging a DRAM chip, because a certain percentage of these chips were failing when a specific portion of the aluminum wiring heated up enough to cause the metal to bubble and form open circuits, an Electromigration (EM) failure. Oh, how I wished for some EDA tools to help me pinpoint reliability issues like EM/IR, before tape-out of course.
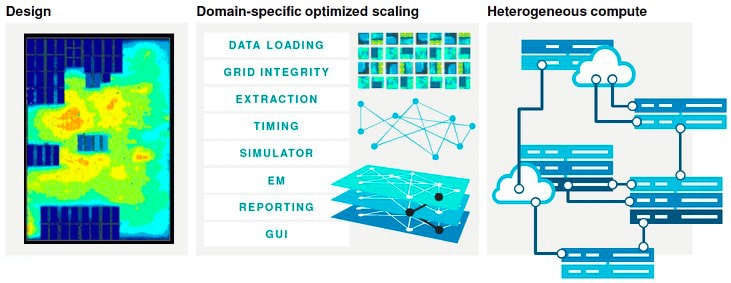
For the past few decades there have been EM/IR tools available in the EDA market, mostly for big digital designs and limited analog designs, so reliability analysis has been performed in order to avoid field failures. Last week I had a Microsoft Teams meeting with Joseph Davis of Siemens EDA, where he outlined their brand new EM/IR tool offering, called mPower.
The past approaches to EM/IR analysis have been to use static techniques on big analog blocks, which is faster, but less accurate than dynamic analysis. Then for smaller blocks, typically analog or AMS, to use the more accurate dynamic analysis. What jumped out to me right away with the new mPower tool, is that it has the capacity to handle the full-chip using the more accurate dynamic analysis, as shown below:
mPower Capacity
The secret sauce to mPower is in how it scales across your network of CPUs, creating quick run times and enabling billion transistor capacity, while also minimizing RAM usage. Inputs to mPower are industry standard file formats, so there’s little work for your CAD group, and it’s a quick learning curve for your design engineers using the tool, just pick out your favorite extraction tool and SPICE circuit simulator. Siemens EDA does offer the popular Calibre tool for extraction and AFS for SPICE circuit simulation, but really, any vendor tool works.
For digital flows, there’s the mPower Digital tool, and then for transistor-level analog flows, the product is mPower Analog. I asked about which IC design companies are using mPower for EM/IR analysis, and was impressed with the initial list:
MaxLinear – full-chip, large analog
Efinix FPGA – full-chip, transistor-level EM/IR analysis without IP modeling
Esperanto – AI chip with 1,000+ RISC-V cores, ran mPower Digital on their own network
On Semi – pixel array designs, both mPower Digital and Analog
The AI chip from Esperanto has 24 billion transistors, so that’s a prime example showing the capacity of the mPower Digital tool. The other customer examples just couldn’t be run with competitor tools using the dynamic approach.
Support from foundries will be announced soon, just know that you can use this new EM/IR tool at process nodes down to 5nm with confidence today, and that 3nm support is in the works. Even 2.5 or 3D ICs can be analyzed for EM/IR compliance, and you can run mPower Digital in the cloud to meet your time to market requirements.
Summary
During IC layout and certainly before tape-out, your design team needs assurance that EM/IR reliability concerns have been analyzed, and that the layout has been properly updated. There is now a new choice for this type of analysis, and Siemens EDA has carved out some unique properties in this segment like full-chip dynamic analysis, using mPower Analog. It’s worth a look to see how your designs could benefit from higher capacity, and fit within the compute resources in place. EDA competition always fosters innovation, and vendor loyalties can quickly change, if the new entrant delivers on their promises.
Anyone can create a testbench[TB] and verify the design, but it can’t be simply reused as a verification IP [VIP]. So I would like to address in this article: What is VIP? How can we build a high-quality VIP? How can we verify the VIP? What else can we do to make the VIP unique and commercially more valuable?
Most of the module/IP level nonstandard testbenches are used once to verify the design. Is it efficient? We always want to use the same module/IP level testbench to verify the IP’s derivatives or the same IP at the chip /SoC level efficiently. Also, if any third-party vendor or client wants to use the testbench to verify their IP/Chip, then the testbench should comply with coding guidelines as per the standard methodology like UVM. So, a reusable testbench that follows a standard methodology, scalable TB architecture, and coding guidelines is called Verification IP. Let me share some of the important guidelines to implement the VIP.
Verification Plan: Defines the verification intent of the DUV/DUT[Design Under Verification/Test]. It captures all the design features and defines how each feature can be verified and tracked closely. It acts as a golden reference document for all the verification folks responsible for the verification sign-off. The VIP functional specification will have all the details – Vplan, TB architecture, Coverage Model, Verification Strategy, Test Scenarios, etc.
Verification Plan [Vplan] is different from the test plan as it’s based on the DUT features and random testcases. In SystemVerilog, we use covergroups and assertions to generate the functional coverage primarily to track the verification progress during the regression testing, which is predominantly done through random testcases. This verification tracking process can be automated by back-annotating the functional coverage to the Vplan document[Excel/Word Doc] during simulation using the EDA tool. But using the test plan, we track it manually by running every directed testcase, usually developed in HDL. Despite this huge difference Directed vs Random, traditional verification folks still refer to Vplan as test plan, similar to how we informally refer to the RTL as DUT instead of DUV.
TB Architecture: Currently, most companies prefer a standard testbench methodology like IEEE standard UVM [Universal Verification Methodology]to define their SystemVerilog TB architecture. It doesn’t mean that one can simply create UVM agents for all the DUV interfaces and connect them together at the TB top level. To create a proper working TB, one needs to understand how the working environment of RTL would be in real-time and how it can be modelled. It is the most challenging part of the verification process. Having a proper TB architecture that can support our verification strategies means that 50% of our job is over.
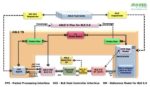
Let me share my experience, how we created the TB architecture for the Bluetooth verification IP [ABLE – Aceic’s Bluetooth Low Energy]. Refer to the figure below – ABLE’s architecture.
ABLE was created mainly to verify the DUV, Link Layer RTL of Bluetooth. So, we created the UVM TB to mimic the host and TLM functional reference model in UVM to mimic the Bluetooth Link Layer. TB was using HCI [Host Controller Interface] as a TLM interface to configure and interact with the Link Layer functional model. The TB as the host for generating stimulus to configure and drive both the BLE reference model and RTL. The scoreboard for comparing the DUV outputs with the expected values generated by the reference model.
More importantly, using the DUV reference model as TLM, one can add or remove any number of BLE devices dynamically during simulation by creating or deleting the TLM objects, as we do in the real-time environment.
All the Link Layer compliance and HCI test scenarios were modeled using UVM sequences. The LL-TS[Link Layer Test-suite and HCI-TS[Host Controller Test-suite] were invoking those UVM virtual sequences.
Also, we had added necessary adapters [BFMs] to replace the functional model with RTL BLE IP at one end, as most of the DUVs use standard bus interfaces like UART/SPI. One can configure the DUT adapter and use it with any interface. So, the DUT side sequences remain the same at the TB top level. Smartly we had used the UVM RAL model to capture the DUT status, and reference/received data through backdoor access for the scoreboard data comparison.
Verification Strategy: Our approach was back-to-back verification using our BLE reference model, UVM TLM. As we were into only VIP development, we didn’t have access to the BLE RTL IP. So, we had to find a way to verify our functional model. I had created two different teams, the TB and modeling team, and had made them work independently in parallel on both the functional model and testbench. TB folks created their own DUV reference model as a predictor logic independently, based on their interpretation of DUV[Link Layer] specification. Eventually, we had to deal with their difference in terms of interpretations, which helped us find all the VIP bugs.
You can’t sell a VIP that has more bugs than the DUT. Eventually, your customer will end up finding bugs in VIP rather than verifying their DUT. So, the verification strategy is critical for the success of your VIP.
As shown in the above figure, the VIP provider should also provide all necessary things:
Executable verification plan which maps all the coverage data
Scripts that can run the regression test-suite that includes all the compliance tests and back-annotate the coverage data to the verification plan
Assertion IP to verify the interface protocols
Reference models that can be used independently as TLMs
User guides to understand and run the VIP, examples, etc.
No one will buy the VIP just because its source code compiles and generates stimulus on any industry-standard simulator. Your customer will ask you to prove how your VIP is different from other commercially available VIPs on their DUT during a detailed evaluation phase beyond your impressive pre-sales presentation and demo. So, you really need to think about how fast you can find bugs in their design and excite your customer beyond their usual expectations like easy VIP integration, user interface, and complete automation.
I’ve simulated IC designs at the transistor-level with SPICE, gate-level, RTL with Verilog, and even used cycle-based functional simulators. Sure, they each worked well, but only for the domain and purpose they were designed for. Industry analyst, Gary Smith predicted that the IC world would soon move to system-level modeling, and I’m seeing more tools in this area. One notable vendor that focuses on system-level modeling is Mirabilis Design, and their simulator is called VisualSim. Mirabilis Design recently issued a press release about a new product called VisualSim Cloud, so I contacted Deepak Shankar, Founder, to learn more about it.
VisualSim Cloud is a Cloud-based simulation platform that can be used for architects, software designer and developers to quickly explore, conduct trade-offs, and optimize the specification. It has the complete feature set of VisualSim Architect. From within a Web Browser, users can assemble models, run simulations by varying parameters, and view/save the results. Models constructed by the user are stored on their respective desktops. All VisualSim libraries are available in the VisualSim Cloud.
VisualSim Cloud is a completely new product that has been in development for over 4 years. It is the next generation to the VisualSim Explorer that we announced a few years ago and was used mostly as a server product within companies. The current release of VisualSim Cloud is the equivalent to VisualSim Architect 2130.
Agile methodology is being to manage the versions within the Cloud. The Cloud version is updated as soon as new features have been developed and fully tested. This include GUI features, simulation speed improvements and new library components.
VisualSim Cloud will showcase all types of modeling- analog, data centers, supply chain, electronics, semiconductors and software.
Modeling and simulation can be carried anywhere. The models can be loaded on a drive and VisualSim Cloud can open it from any machine with just a Web Browser. There is no need for a software download or setup of complex Licensing mechanism. The simulation engine uses the compute and memory power of the local desktop.
New updates and bug fixes can be provided instantly. The user does not need to wait for the next release or request CAD to update their install.
Q: What problems are you trying to solve?
System-Level modeling takes a long time to get started, there’s a need to be in the corporate network, you get approvals before they decide to conduct system modeling, restriction to take your work any where, and leverage any server that does not have VisualSim installed. With this approach, everything is performed through the browser. All the tutorials, documentation, starting models and all available online. SO, the user is up and running as soon as they get the login information.
Also, new features are not immediately communicated to all users. This can be eliminated as the user will always be working with the latest release.
Q: Who should use this tool?
There are three main users- students, casual users, users that need the software for a single project or for a single analysis, and for overflow scenario when a license is not available in the corporate environment.
Q: Which OS do you support?
VisualSim Cloud will work on any platform that has a Web browser. This includes Windows, Linux and Mac OS.
Q: What else needs to be installed on my computer to run this?
To launch and start modeling, user needs a login, Java 1.14 installed on the machine, and a small download called OpenWebStart. Please note that right now support is limited to Java 14. Before launching VisualSim Cloud for the first time, user needs to configure OpenWebStart to work with Java 14. When they click on the Launch button, a small executable is downloaded. When the user double clicks on this executable, a series of windows will ask the user if they would like to execute. The user must accept all the security statement. Finally, VisualSim will open from within the Web Browser. There are several models available in VisualSim Cloud using File->Open Template. Also, if the user has models on their desktop, they can open them, as well.
Q: Are there any modeling limitations?
There are two limitations currently in VisualSim Cloud. User created classes cannot be used in the models, and batch-mode simulation are not supported.
Q: When should I use VisualSim Cloud versus standard VisualSim?
VisualSim ensures the user always has the latest version and there is no need for installation and management of the software locally. This can be of great use to students working on research or class projects, professor offering assignments, researcher using it for short-term; startup or smaller companies that do not have an IT/CAD infrastructure. Also, anyone that wants to use it for a short time, want flexibility in their working environment and overflow at existing company infrastructure.
Unlike other Cloud solutions, VisualSim still stores the models locally. This way the user manages the data and also does not have to pay expensive cloud provider fees.
Q: What is the cost of VisualSim Cloud?
Until end of 2021, there is no charge. After that we will be charging between $500-3000 a month depending on the libraries, type of customer, and usage. There is no cloud provider fees.
Q: If VisualSim Cloud is. free, then how do you make money?
VisualSim cloud is free for some types of teaching and student research. It is not free for commercial operations. The price is listed above.
Q: Are there any capacity or practical limits to the size of a system that I want to simulate?
There is no model capacity or simulation limitations with the cloud version. Of course, there are limits in the interface to other tools as they also need to be cloud compatible.
Q: What are some of the largest designs simulated on VisualSim Cloud?
We have simulated three large designs that cover the most popular market segments:
SoC with 64 NoC Router, with 4 HBMs, 64 ARM N1 Routers and a host of associated interfaces, DMA and cache.
TSN and CAN Network with 85 devices
Multi-blade PCie system with ten 100Gbps interfaces
Q: Does VisualSim Cloud co-simulate with other tools or have an API?
VisualSim Cloud API has an open and documented API. Currently there are no other system modeling tool that has Cloud facility. We welcome any and all companies to integrate their IP and simulators to VisualSim.
Q: How would you compare VisualSim Cloud to something like MathWorks, Simulink, Simscape, Stateflow tools? Are there any competing tools out there?
VisualSim is the only integrated multi models of computation and system modeling solution on the Cloud. VisualSim is used for architecture exploration, performance analysis and integrated power exploration. While others are focused on correctness of algorithms and code-generation, VisualSIm focused on providing Intellectual Property that enables designs to develop new SoC, processor, network equipment, Radar and communication systems, and avionics.
Q: Can I run Monte Carlo simulations, or perform design optimizations?
Yes, you can run Monte Carlo simulation by varying configurations, topologies, and parameters. Using the soon-to-be-launched requirements/Diagnostic engine, much more accurate design optimization can be performed. For example, if you are designing an SoC, you create the best configuration to meet the Quality-of-Service, throughput and power requirements for a multimedia, AI or networking application. Similarly, if you are design an AI machine for automotive application, you can select the interface, AI processor or FPGA, memory size and software partitioning.
Q: Which Universities are using VisualSim Cloud in their curriculum?
A number of universities and companies are using VisualSim cloud: Wichita State, Politehnica University- Romania, Xiaopeng Motors, eSol Trinity, ELC Labs, Shivaji university, ZTE, City University of Seattle, University of Ottawa, Draper laboratory, TH Cologne, University of East London and a few others.
Q: What was the impetus to offer a cloud-based system simulator?
System design is not well understood and there is very little time allocated. Engineers prefer to get their analysis done quickly. We felt a Cloud version will enable engineers to get started very quickly and use existing templates to quickly explore their designs. This will provide instant benefit without having to setup a formal Engineering infrastructure. As the company evolves to make systems design more mainstream, the engineers can migrate to the Desktop or corporate version.
Q: Does Mirabilis have a 3rd party program for other vendors that want to integrate with your ecosystem?
Yes, we have a fully open API. Users can partner in three ways- create value-add features for new application markets (industrial or Medical), develop libraries and market them for their existing market segment (Automotive networks), training companies (Labs and interactive learning solutions), develop multi model of computation design for sensors, mixed-signal and control system.
Cloud Hardware
Q: Which datacenter are you using for VisualSim Cloud?
Mirabilis Design maintains a private data center at Host Gator in Houston, TX and Provo, UT.
Q: What security measures are you taking in the cloud?
VisualSim Cloud hosting site is protected by a variety of security measures. The access is via https.
Q: How do you guarantee the computing power for each cloud job?
All simulation are executed on the host machine. VisualSim takes advantage of the processor and memory capacity of the machine running the Web browser.
Q: What OS is VisualSim Cloud using?
The cloud is running on the following version of Linux- Linux 4.19.150-76.ELK.el6.x86_64 x86_64
Q: What is the download speed of VisualSim Cloud generated simulation data?
The download speed is 10Gbps.
User applications
Q: How many VisualSim Cloud jobs can a person launch simultaneously?
Each user can open any number of VisualSim models. At any time, only one model can be simulated.
Q: What is the Memory capacity allowed for a person?
Currently, there is no limit on the memory capacity [partitioning for each user. Memory is provided on-demand for each simulation run.
Q: Can the simulation results be saved to a cloud disk, and is their a limitation of the disk space?
No, All simulation results and models are saved locally on the client.
Q: What Web browsers are supported for VisualSim Cloud?
VisualSim Cloud can be accessed by any browser that support Java 1.14. This includes current versions of Microsoft Edge, Firefox, Google Chrome, and Safari.
Q: Where are the models hosted?
The models are hosted on the local desktop. The software image is stored on the Mirabilis Design server. When the user logins to the VisualSim Cloud, the software is downloaded to the Browser and VisualSim opens within the Browser.
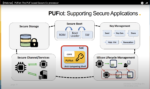
In June 2021, eMemory Technology hosted a webinar titled “PUFiot: A PUFrt-based Secure Coprocessor.” You can read a blog leading up to that webinar here. PUFiot is a novel high-security crypto coprocessor. You can access a recording of that entire webinar from eMemory’s Resources page. While the focus of that webinar was to present the details of PUFiot and the underlying PUF technology and PUF-based Hardware Root of Trust, it did have one slide showing the different use cases for the coprocessor. Refer to the figure below.
The webinar stated that the PUFiot Coprocessor can be used in Arm-based systems and RISC-V-based systems to secure applications but did not go into detail. Therefore, I want to pick up from there and blog about how the PUFiot Coprocessor can be utilized to secure applications. This blog is based on a whitepaper published by PUF Security Inc. The proof point is in the form of a successful demo by Andes Technology.
According to AV-TEST Institute, the number of malware programs climbed from around 65 million in 2011 to 1.1 billion by the end of 2020. The AV-TEST Institute is an independent research institute for IT security monitoring and reporting. The threat level is expected to grow significantly with the rate of adoption of IoT devices.
IoT devices are set to take over the world. They are used in applications ranging from autonomous vehicles to remote weather stations. If these applications can be breached, imagine the damage that can happen. Companies must be prepared to deal with this increased vulnerability by securing their applications.
What is Needed to Tightly Secure Applications?
Ensuring the security of applications requires the following six things as identified in the whitepaper. See below.
Trusted Execution Environment (TEE): Isolates codes, data, and memory that require a higher security level.
Root of Trust: Safeguard crucial security parameters; comprises unique ID, certificates, secret keys, and secure storage.
Secure Boot: Blocks unauthorized OS and applications from running.
Data at Rest Security: Stores data in an encrypted/obfuscated form with solid access control to prevent leakage.
Data in Transit Security: Utilizes keys to encrypt data before transmission to prevent interception.
Secure OTA Update: Ensures that firmware or software updates in the field come as encrypted ciphertext and that no downgrading is allowed.
The main processor/CPU of the application cannot accomplish all of the above by itself. The Root of Trust is more securely implemented at the hardware level, using an inborn PUF. The key storage unit and the execution environment need to be tamper-proof. The cryptographic algorithms are also more efficiently implemented in hardware.
In essence, a Secure Coprocessor that includes a Hardware Root of Trust and anti-tampering features is needed to support the CPU in securing applications.
Benefits of Using a Secure Coprocessor for Securing Applications
A fully secure hardware-accelerated coprocessor will offload the security-related tasks away from the CPU, allowing the main processor to perform its primary functions safely and efficiently. This approach simplifies the system design and enhances the overall performance of the application. An ideal coprocessor will be a plug-and-play security solution to allow easy implementation of key security features.
PUFiot – A Drop-in Solution for RISC-V-based IoT Systems
RISC-V architecture is gaining significant adoption among IoT devices for the processor of choice to handle the enormous amount of data and associated transactions. A major reason for this is RISC-V’s open architecture and relatively low cost. But the security guidelines for RISC-V based systems are still under development.
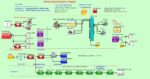
As security guidelines continue to evolve, choosing a compatible solution that calls for the least amount of disruption to the system and the application is a wise choice. PUFiot coprocessor is such a drop-in solution. Refer to the figure below for the design architecture of the PUFiot Coprocessor.
PUFiot Coprocessor Design Architecture
PUFiot’s secure boundary is based on physical separation of hardware, therefore establishing a sound Trusted Execution Environment (TEE). At the heart of PUFiot is a Hardware Root-of-Trust design. This encompasses eMemory’s patented NeoPUF, providing each chip with a unique chip fingerprint (UID) and offers Riscure certified anti-tampering secure OTP for key storage, preventing physical/electrical attacks on crucial security parameters. The Hardware Root of Trust also comes with a True Random Number Generator (TRNG), a source of dynamic entropies to secure cryptographic engines and communications between systems. For complete details of all of the built-in features and functionality, refer to the PUFiot product page.
Securing Applications on a RISC-V based system
With the security guidelines for RISC-V based systems still evolving and the ecosystem still maturing, systems developers have to either implement the security solution themselves or adopt a trustworthy solution from a partner. Choosing the in-house development path will throw its own challenges along the way. For example, does the solution provide a solid secure boundary (meaning comprehensive Hardware Root of Trust), support all major crypto algorithms, and obtain 3rd party security certifications, etc. Security is a global issue, and certifications need to satisfy international requirements, rules, and regulations. PUFiot coprocessor has all of these aspects covered. Refer to the figure below for a block diagram of a RISC-V SoC design incorporating PUFiot coprocessor to secure applications.
A RISC-V SoC Incorporating PUFiot Coprocessor
A potential threat to an IoT device comes in the form of a malicious chip added to the system in place of the genuine chip holding the firmware. A PUFiot implementation ensures that attempted breaches can be stopped right at boot time. Any attempted tampering to switch security key information is stopped right at boot time by verifying chip pairing. Refer to Andes Technology demo below.
Andes Technology’s Secure Boot Demo
Andes Technology is a leading supplier of high-efficiency, low-power 32/64-bit RISC-V processor cores and a Founding Premier member of RISC-V International. It demonstrated the effectiveness of the PUFiot coprocessor in securing applications.
A secure boot process involves checking and authenticating application firmware before executing the boot-up process. Andes setup two FPGAs (A and B) for the demo. A’s firmware was encrypted and stored in flash memory corresponding to A. Similarly, B’s firmware was encrypted and stored in flash memory corresponding to B. Each PUFiot comes with its unique inborn private key, what is stored in the respective flash memories is encrypted differently. As a result, the systems will only boot with the correct chip pairing. Any attempt to boot the systems with non-matching flash memories will fail, as the decryption will not be successful without the valid key. Andes demonstrated that the systems booted successfully with the correct chips-pairing but could not boot when the flash memories were swapped.
Summary
The PUFiot secure coprocessor can easily be dropped into RISC-V-based systems to secure IoT applications. PUFiot enables Zero Touch Deployment needed in the world of IoT. With built-in hardware-accelerated security functions and access controls, PUFiot also meets the requirements of Zero Trust Security in cloud applications. You can access the whitepaper titled “An Essential Security Coprocessor for RISC-V Designs” from here. PUFiot is available for free evaluation for users who would like to try the IP. Please visit https://www.pufsecurity.com/ip-go.






{kind=link}
{kind=link}