The great thing about architectural solutions to increasing throughput is that they offer big improvements. Multiple CPUs on a chip with (partially) shared cache hierarchies are now commonplace in server processors for this reason. But that big gain comes with significant added complexity in verifying correct behavior. In a shared memory model, the value stored in a logical memory address appears not only in main (DRAM) memory but also potentially in multiple on-chip caches and even possibly in buffers in the coherency fabric. Which raises a consistency issue – for a given logical memory address these should all contain the same value under all circumstances, but do they? Breker attacks this coherency verification problem through their test synthesis technology, looking at full system coherency in heterogenous systems.
The challenges in coherency
The logical memory view can become inconsistent when two or more processors are working with their own local copy of a value at a shared address and one updates its local value, unknown to the other. Chaos ensues as CPUs each work with their own view of reality. The coherent fabric itself has structure supporting data in-flight, such as write-back buffers. Coherency verification must also deal with these. And then of course peripherals can write directly to main memory through DMA, unknown to internal caches.
Clearly some mechanism is needed to keep shared values in sync when required. But it must be light-handed. Synchronization comes with a latency penalty which can significantly reduce the performance advantage of caching, unless used only when absolutely needed. The latency problem is compounded further when you consider shared memory multi-socket processor boards interconnected via CXL. Adding more complexity to solutions.
Clever techniques are used to spy on cache contents and changes, to determine when a synchronization update is necessary. These include snooping and directory-based coherency systems, which tag cache addresses (more exactly cache lines) as being clean (coherent) or invalid, with a variety of refinements. These methods must walk a fine line between minimizing net performance impact while ensuring no possible escapes. Escapes being possible cases in which a non-coherent condition can survive.
The Breker System Coherency TrekApp
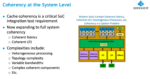
To check that the design does not cross that fine line, verification engineers must independently construct tests which they believe will cover all possible cases. Cache, fabric and IO coherence across all control variations (power, interrupt, clocking, etc) through which the design might cycle. That’s where the Breker Trek System Coherency app comes in.
Adnan Hamid, founder of Breker, started many years ago in coherency verification at AMD. The ideas he developed there around cache coherence verification and system verification methods in general he built into Breker. The coherence solution expanded over time to also include fabric and IO coherence and interaction with power switching, etc. After proving this capability out with a few lead customers, Breker announced the product at the recent DAC 2021 in San Francisco.
Adnan offers an insight: to know how to achieve meaningful coherence verification, you first must know how to measure coverage. As with any system-level coverage objective, RTL coverage metrics aren’t helpful. More useful is coverage first of the coherency manager state machine per cache, with variants in cache values and address stride, then a similar coverage for cross-cache interactions, then coverage across a synthetic set of software-based torture tests, crossed with power and other transitions, running on an emulator. The System Coherency TrekApp supports all of this.
What about escapes?
Talk to anyone working with coherent designs and they’ll all tell you they find coherency problems post-silicon. Getting close to that fine line without crossing it is really quite difficult. After all you’re trying in pre-silicon verification to model a vast state space with, in comparison, a tiny set of tests, even if you run tens of thousands of tests. Given that exhaustive testing is not even remotely possible, the trick is to find the best practical set of tests to run. Since this will be unavoidably incomplete, the System Coherency TrekApp extends even to post-silicon, helping to diagnose silicon failures. Perhaps a power transition in the middle of synchronization. Or an interrupt unfortunately timed against a tag update. In Adnan’s view, this post-silicon learning will help refine the pre-silicon verification coverage plan. To reduce if not eliminate post-silicon escapes.
Interesting stuff, incidentally supported for both Arm-based and RISC-V-based systems, recenly endorsed in a press release with Nuclei System Technology. You can learn more HERE.
Also Read:
WEBINAR: Adnan on Challenges in Security Verification
Breker Tips a Hat to Formal Graphs in PSS Security Verification