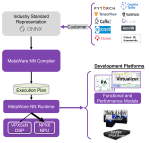
Semiconductor industry is going through an unprecedented technological revolution with AI/ML, GPU, RISC-V, chiplets, automotive and 5G driving the hardware design innovation. The race to deliver high performance, optimizing power and area (PPA), while ensuring safety and security is truly on. It has never been a more exciting time for hardware design and architecture.
The story around validation & verification is however not as inspiring with the industry struggling to show improvements in best practice adoption. If Harry Foster’s Wilson Research Report is anything to go by, an ever-increasing number of simulation cycles and the astronomical growth of UVM is unable to prevent the ASIC/IC respin which is at a staggering 76% while 66% of IC/ASIC projects continue to miss schedules.
62% of the ASIC/IC bugs are logic related causing respins in designs with over a billion gates – practically everything that powers our devices in our day-to-day lives. It would be interesting to analyze what proportion of the logic bugs could have been caught on day one of the DV flow.
While the industry continues to talk about shift-left, it is not doing the walk. The best way of ensuring shift-left is to leverage formal methods into your DV flow. One of the ways we could adopt formal methods early in the DV flow by understanding its true potential. While the use of formal apps has certainly increased over the last decade, the application of formal is still very much on the extremities. Almost everyone would use linters (based on formal technology) in early stages of the project and use apps such as connectivity checking towards the end of the project flows. However, the full continuum is missed. The real value-add of formal is in the – middle – in functional verification as well as safety & security verification.
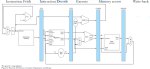
Modern-day designs are verifiable by formal when supported by great methodology. At Axiomise, we have formally verified designs as big as 1-billion gates (approx. 338 million flip-flops), though the gate and flop count is not the only criteria for determining the challenges with proof complexity.
Formal methods are capable of not only hunting down corner-case bugs easily, but they also establish “exhaustive proofs of bug absence” through mathematical analysis of the entire design space by employing program reasoning techniques based on sound rules of mathematical logic. Formal verification constructs a mathematical proof to verify a design-under-test (DUT) against a requirement. Along the way of building a proof, formal tools can encounter bugs in the design, or in the specifications, or both. When no more bugs can be found, a formal proof establishes that the requirement holds valid on all the reachable states of the design where reachability is determined purely through assumptions on the test environment with no human effort needed in injecting stimulus in the design – a formidable challenge in dynamic simulation!
At Axiomise, we have been deploying production-grade formal methodology using all the commercial tools in the market with great success. To make formal normal, one must understand its true potential by mastering the methodology. This talk will discuss some of the key aspects of formal verification methodology based on the insights from the practical deployment of formal, and show how scalable formal methodology based on abstraction, bug-hunting and coverage can be used to accomplish functional verification for designs with few flip-flops to a design with billion gates.
Also Read:
A Five-Year Formal Celebration at Axiomise