
As the mobile industry growth slows and looks to growth in IoT, companies like Samsung Electronics are looking for ways to initiate change or adapt to the new climate around them. One of the ways mobile companies are going to be profitable in the future is through offering, building and sometimes hosting those services beyond just… Read More
 CEO Interview with Ann Wu and Akash Levy of SilimateAnn Wu is Co-founder & CEO of Silimate.…Read More
CEO Interview with Ann Wu and Akash Levy of SilimateAnn Wu is Co-founder & CEO of Silimate.…Read More From Process Learning to Production Control: Characterization for the Era of Heterogeneous SystemsEvery generation of semiconductor innovation has relied on…Read More
From Process Learning to Production Control: Characterization for the Era of Heterogeneous SystemsEvery generation of semiconductor innovation has relied on…Read More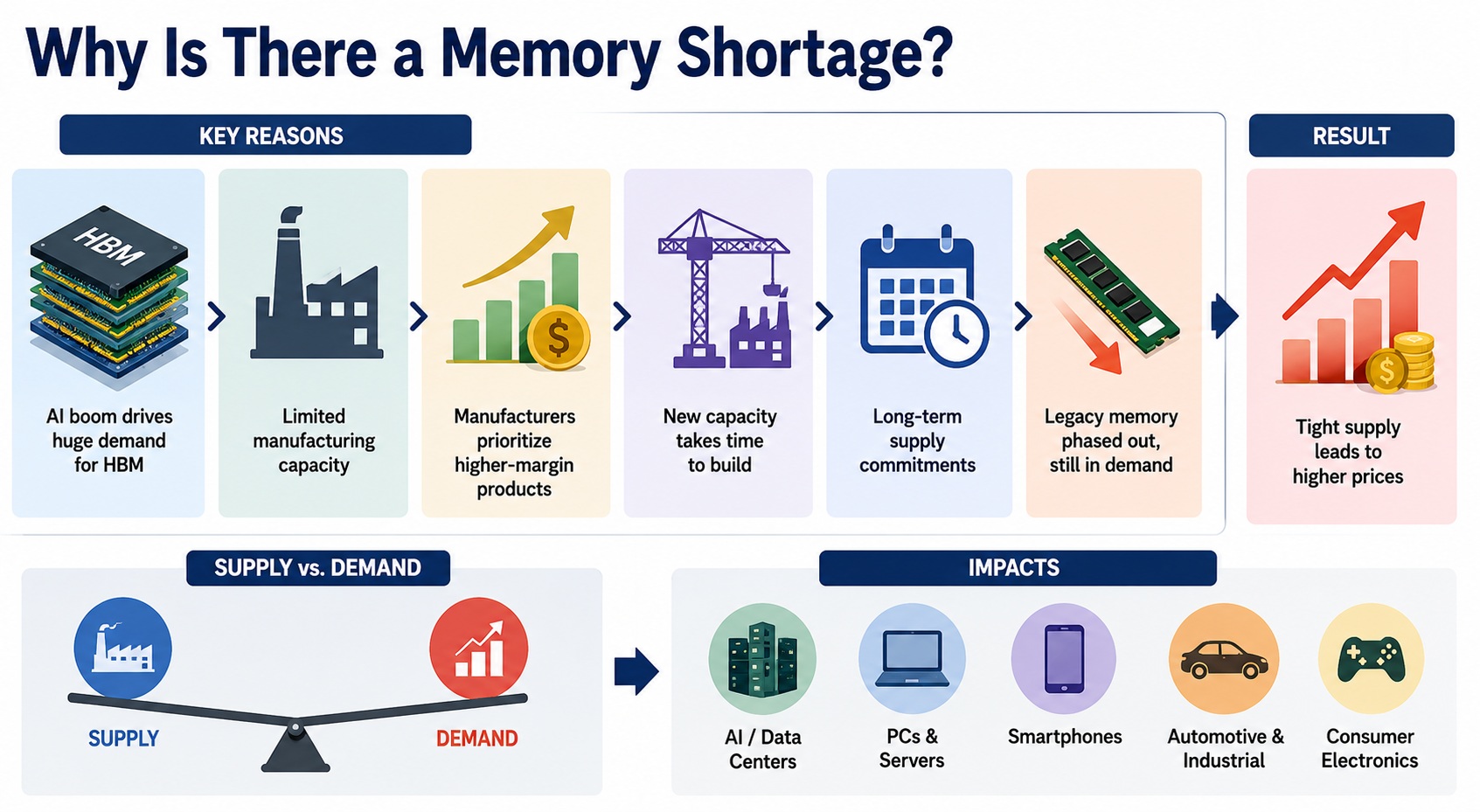 Five Myths about the Current Memory BoomThe current semiconductor memory boom is mainly an…Read More
Five Myths about the Current Memory BoomThe current semiconductor memory boom is mainly an…Read More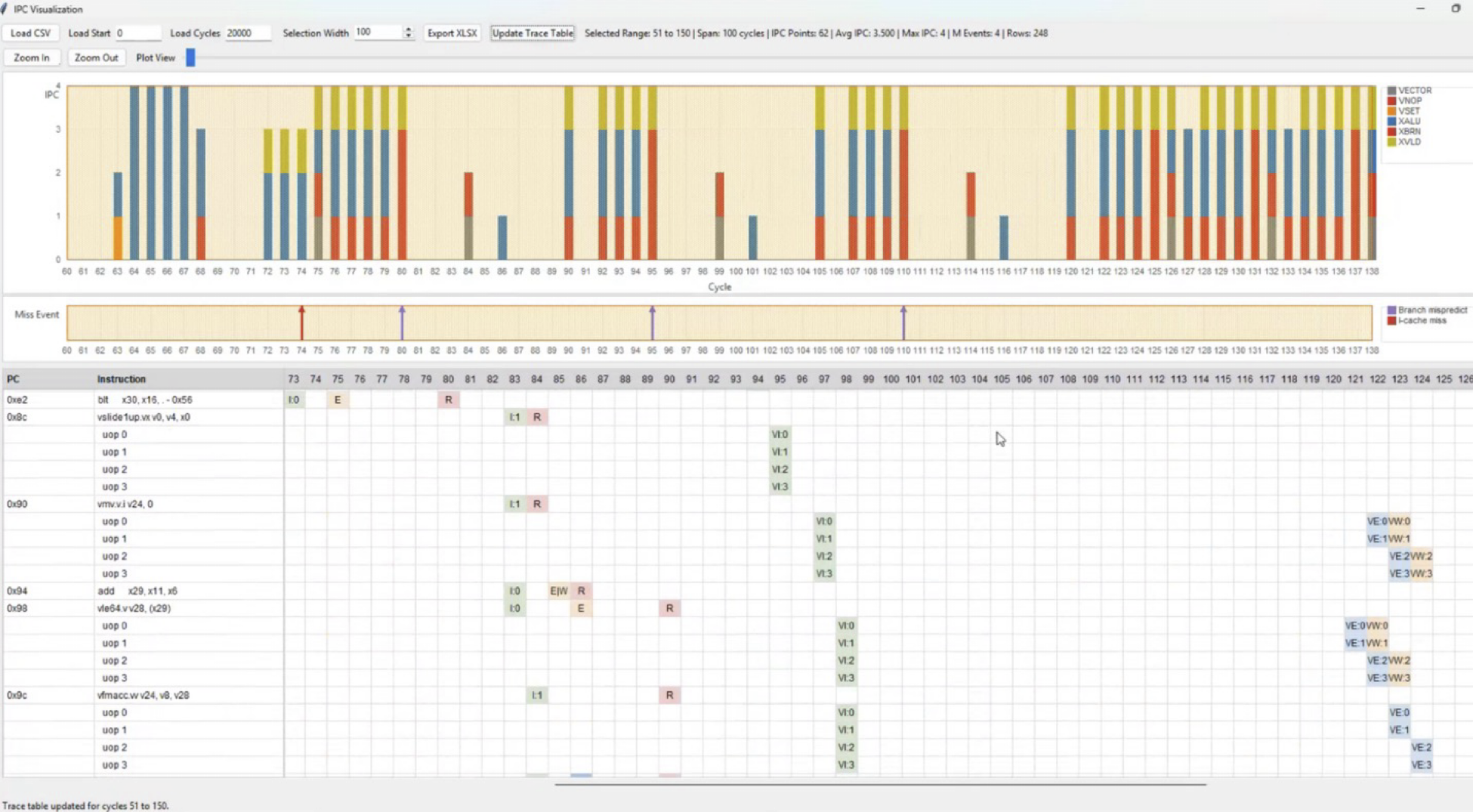 How Fast Can a Performance Model Actually Be Built?By Thang Tran, CEO of Simplex Micro and…Read More
How Fast Can a Performance Model Actually Be Built?By Thang Tran, CEO of Simplex Micro and…Read MoreBig Data Lessons from the LHC
Big Data techniques have become important in many domains, not just to drive marketing strategies but also for semiconductor design, as evidenced by Ansys’ recent announcements around their use of Big Data analytics. And they should become even more important in the brave new world of the IoT. So it makes sense to look at an organization… Read More
Not-so-ulterior motive leads SoftBank to ARM
This week’s £24.3B offer for ARM Holdings plc from SoftBank has been widely viewed as Brexit reflexit. It did firm up in the preceding two weeks, but this acquisition offer has been years in the making – and if it sticks, one SoftBank motive many analysts and editors are missing comes front and center.… Read More
Electrical-Optical Design, A Bridge to Terabitsia
If you don’t get the tongue in cheek reference of the title, you probably don’t have children who liked to watch Disney movies. All four of my daughters loved Disney and so, I am forever shaped by the Wonderful World of Disney. In 2007 Disney adapted to the screen a novel called, ‘A Bridge to Terabithia’, in which two adolescents escape… Read More
Technology, Shakespeare, Linguistics and Combatting Terror
My brother Sean is working on post-doctoral research in linguistics, especially the use of language in Shakespeare’s plays. Which may seem like a domain far removed from the interests of the technologists who read these blogs, but stick with me. This connects in unexpected ways to analytics of interest to us techies, and ultimately… Read More
10 Challenges in IP Design Collaboration

Enterprise design management can be summed up in one word: collaboration. Intellectual property (IP) reuse and the success of distributed system-on-chip (SoC) design efforts depend strongly on how well designers can collaborate. As time-to-market windows have shortened, the challenges around design collaboration have… Read More
Integrity and Reliability in Analog and Mixed-Signal

In the largest and fastest growing categories in electronics – mobile, IoT and automotive – analog is playing an increasingly important role. It’s important in delivering high integrity power and critical signals to the design though LDO regulators and PLLs, in managing high speed interfaces like DDR and SERDES, in interfacing… Read More
New Transistor Sizing Company at #53DAC
I first met Herve Guegan at Mentor Graphics back in the late 90’s when he managed a group of developers for the SPICE circuit simulator called Eldo in Grenoble, France. We’ve kept in touch over the years and he asked to meet me at DAC in Austin this year, so I caught up with him to get an update on his latest start-up company… Read More
AVS 2016: Table Set for Tesla Tussle
As predicted, by me, the anti-Tesla and anti-autonomous vehicle forces are gathering in the wake of the recent fatal Tesla Model S crash in Florida. The rising resistance arrives one week in advance of next week’s Automated Vehicles Symposium in San Francisco – setting the stage for a spirited debate.… Read More
Safety = Security?
Have you ever wondered what the difference is between safety and security? I would be surprised if you had unless you work in these areas as we tend to use the words interchangeably. Languages such as German, Norwegian and Spanish have one word to mean both – or so I am told by my associates who claim those languages as their mother… Read More
TSMC CoPoS Versus Intel EMIB Semiconductor Packaging