


 At the Linley conference last week I ran into Gordon Brebner of Xilinx. He and I go a long way back. We had adjacent offices in Edinburgh University Computer Science Department back when we were doing our PhDs and conspiring to network the department’s Vax into the university network over a two-week vacation. We managed to do it. I think Gordon and I (and another co-conspirator called Fred whose name wasn’t really Fred, but that’s another story) drank some beer together at times, but I’m a bit hazy about that.
At the Linley conference last week I ran into Gordon Brebner of Xilinx. He and I go a long way back. We had adjacent offices in Edinburgh University Computer Science Department back when we were doing our PhDs and conspiring to network the department’s Vax into the university network over a two-week vacation. We managed to do it. I think Gordon and I (and another co-conspirator called Fred whose name wasn’t really Fred, but that’s another story) drank some beer together at times, but I’m a bit hazy about that.
I came to the US and Gordon remained in Edinburgh and eventually became head of the computer science department. Then he decided to join Xilinx and move over here and do research on novel things to do with FPGAs. One area goes back to that networking stuff, how to use FPGAs to build a custom network processor that has exactly the functional and power/performance requirements.
At the evening exhibit session, they were demonstrating this at 100G line rates showing that FPGAs do have the necessary performance. And devices are now large enough that you can build significant architectures and systems.
The normal alternative is to use a network processor unit (NPU) or else a generic multicore CPU and try and get the right mix of resources, interconnect, ports etc in a fixed architecture.
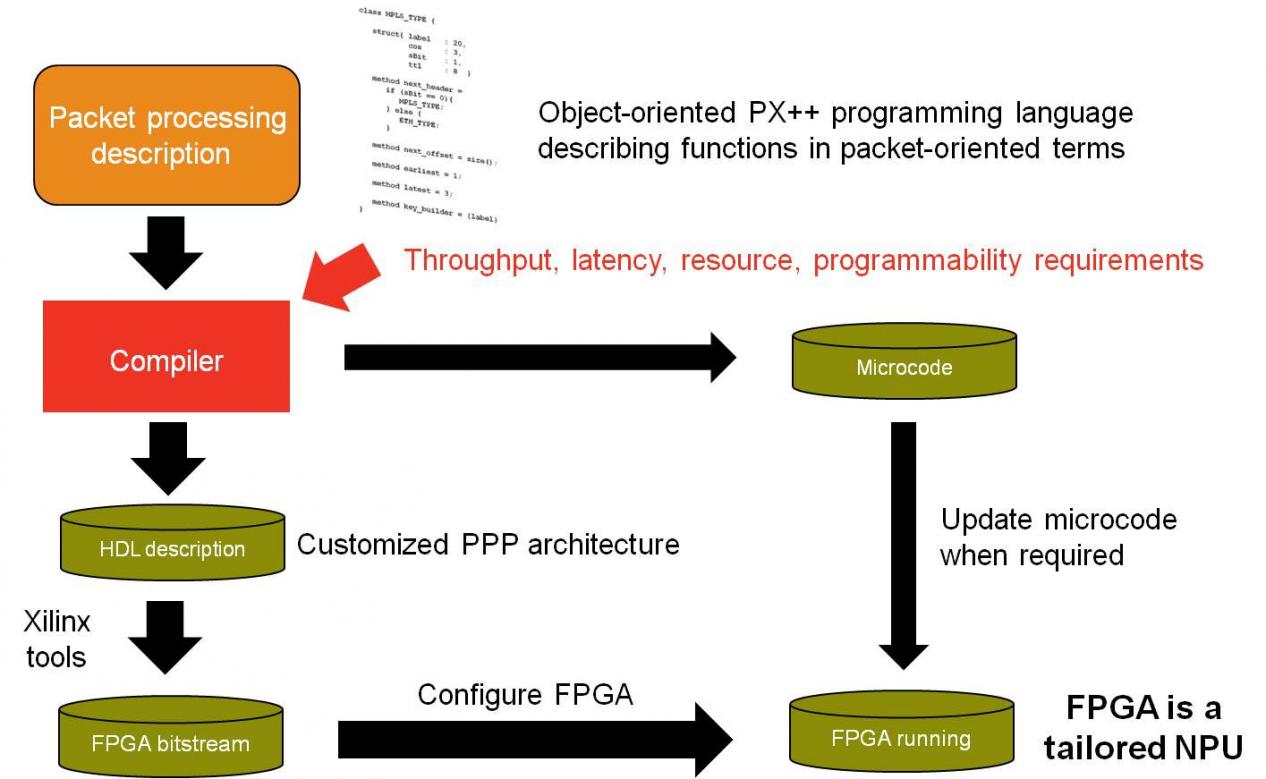 So how do you actually build one of these network processors? The user describes packet processing requirements in the PX++ language, which has an object-oriented programming style. The PX++ compiler generates a customized micro-coded architecture, described in RTL, when is then synthesized for the FPGA. Subsequent changes to the PX++ description, unless very large, can then be compiled to microcode updates only, with no re-synthesis being required. The compiler also takes throughput and latency requirements separately, and customizes the generated architecture to meet these, thus showing a scalable approach. This results in trade-offs, e.g. higher throughput means more FPGA resource use, lower latency means less run-time programmability.
So how do you actually build one of these network processors? The user describes packet processing requirements in the PX++ language, which has an object-oriented programming style. The PX++ compiler generates a customized micro-coded architecture, described in RTL, when is then synthesized for the FPGA. Subsequent changes to the PX++ description, unless very large, can then be compiled to microcode updates only, with no re-synthesis being required. The compiler also takes throughput and latency requirements separately, and customizes the generated architecture to meet these, thus showing a scalable approach. This results in trade-offs, e.g. higher throughput means more FPGA resource use, lower latency means less run-time programmability.
In the future I think we will see more of this. Today, when you think of programming an algorithm you think if implementing it in software. But for really high performance, compiling it into gates can be more effective, either using general high-level synthesis (such as AutoESL that Xilinx acquired last year) or something like PX++ that is completely focused on a specific but important problem.





Enhancing Multi-Domain System Simulation with FMI Co-Simulation