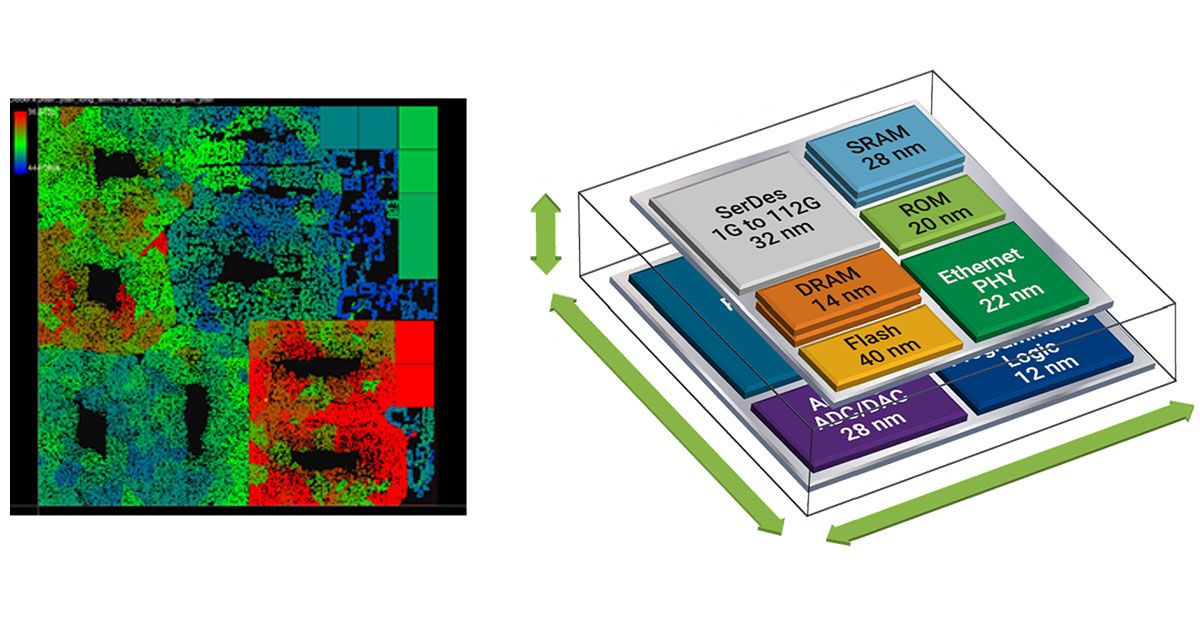
Maybe, but every significant chip company in the industry is working on UCIe and promising to deliver it. And that article is just marketing material, and Eliyan is a client of article's author.
Yes - the author of the paper is an investor / cofounder of Eliyan who is building upon the UCIe concept with an alternative implementation. I can see some value to the offering - but it will be hard to compete against an open standard - although there will be variations. Everyone wants to eek out an edge in the market.
.... as you might expect - I have an alternative in the works that is a lot less cumbersome compared to CXL and UCIe. (I know, I know - we can come back to it later)
No, we're not aligned. Are you referring to transient circuits or persistent circuits? If you can support a very large number of persistent circuits, it is possible that latency could be lower than with packet switching, but then the question becomes... at what level does the circuit exist? What level are you referring to? Just the physical ports? Higher?
Ethernet does have an externally managed address, in that the endpoint address is the port's MAC address, which is assigned by the manufacturer. Other interconnects assign addresses at the endpoint, which are discovered, or through fabric managers, which can assign them centrally.
The only interconnects which don't congest are direct interconnects (point to point), like a dragonfly. Direct interconnects with intermediate routing, like a torus, can and usually do congest.
The design provisions for the creation of point-to-point circuits for all ports simultaneously- on an on-demand/as-required basis. These are direct port-to-port circuits from system to system - exactly like dragonfly. So yes - this is exactly the idea/application. I dont use any intermediate routing like a torus or switched packet system like Ethernet. The closest concept is like RapidIO which pretends to be a peripheral Master/Slave connection by assigning slave addressing to systems along with master addresses. Cumbersome but works in some cases.
What I do is provision for 100% data transfer coverage between any number of systems. We can support fully bidirectional transmissions by binding two circuits ... this expands to permitting a one-to-many and many-to-one connection with congestion constraints at the "one" - but logically possible with multiple ingress ports configured.
The MAC address is leveraged by an Ethernet switch for the assignment an address - so I will add the precision that the network address is aligned with the MAC address and that the MAC address itself is not the address for the network. In a cross-over configuration, one must assign manually into the IP stack. Fabrics also assign a logical address to each physical connection - either by using a hardware signature or implementing one of their own. My point is - these "addresses" are for the benefit of the Network routing and switching....
You're going to have to move beyond this sort of dreaminess for us to discuss it. I know what comes next... I'm just having a failure of imagination.
Let me see if I can help draw a picture.... imagine a box that has a connection for every system (two if you want to talk bidirectional but lets imagine the data transfers are small and the transmission speed is fast so that we can flip directions on a single circuit)
So every system is connected to this box - and every system will either read or write to this box.
Now imagine that, in this box, there is a system delegate or proxy. Let me pull you into my dreamworld of AI and ask you to imagine that this delegate or proxy is like a delegate at the UN... Every country is present - insofar as they have a delegate at the discussion hall - and each delegate can find a table at which to negotiate a deal with every other delegate. So many papers are exchanged - in person - on behalf of the remote governments. Regardless of how each delegate is instructed - they act with the full authority of the home country. So - with local intelligence - each delegate finds the other and deals direct - resulting in seamless communication. And.. if we move back to a computer - we know that we can make an AI delegate more efficient than a human delegate - so if our Ai delegate can act as efficiently as a machine and as independently as a human - we can see how data exchanged across sufficient "tables" in out UN box - can exchange any amount of information without congestion: delegates find themselves, there are sufficient tables at which to sit, and the Ai delegate is machine efficient. Actually - NVIDIA kinda does this through its AI-trained switches... it trains its Ai-powered switches to learn what paths need to be created.
That is exactly what I put in a box.
The difference is that - unlike the NVIDIA Ai-trained switches - I have discovered how to train the delegates - "just in time" - so there is no upfront training. Very much like science fiction - but oh so much simpler (I am really not as smart or well trained as others on here).
So there is no congestion - there are always enough tables to support the creation of a conversation / link. And my Ai delegates are assigned a table at which to transact on a just-in-time basis.
Three problem spaces which have pretty much nothing in common now.
I don't know what this means. Can you explain it?
Computer networks were created to connect systems that were miles apart. They were connected in a way similar to the telephone. Telephones connected to a local switchboard and were manually plugged into another connection to create a circuit. When physically separated - an address is required to differentiate one thing versus another. If you live in a huge country, you rely on postal codes or zip codes. If you live a small rural town you say "the house with the big blue barn". When everything can ve aware if the other thing - each can self identify. I can introduce myself in a room and exchange a business card with anyone. This is a simple intelligent and ad-hoc circuit (biz card transfer). In an ethernet world, I have to go register, get a number, find someone else's number - then line up to provide my card to the room business card proctor and have that proctor stuff my card in the recipients 'inbox. What results is alot of junk - zero trust implementations of rejecting every card until each is validated and verified. etc etc. It is just silly to impose a business card proctor on me to exchange my information with another person in the room.
And our answer for computer systems that sit one beside the other on the same desk to do the same - just faster. Or between two IP blocks in the same electronic design to do that same. If I - as a user, designer or technician can commonly control two systems - why can't I make them transfer data directly?? In all cases I am in control of all three scenarios - I can set the rules for successful interaction.
In a first simulation - I wired two USB controllers together - directly wired them. Literally! I hit receive on the first system - and send on the second system. And the first 16 bits flew across at 457MBps. .... it took some time to scale the data, and scale the number of systems - but we did it.
It comes down to this simple axiom: "“if lines are cheap, use circuit switching; if computing is cheap, use packet switching” - Roberts, “The Evolution of Packet Switching.”, Proceedings of the IEEE (Volume 66, Issue: 11), Nov 1978.
I don't know what this means. Can you explain it?
It means I can train intelligent systems that are side by side, directly connect them to a common magic box - such that they transfer data without a network control or any external address. Each system and data exchange being fully secure and private. And by "intelligent system" I mean "any processor that can run logic" - so that means I treat semiconductor, laptops and servers all identically and interchangeably.
As to scaling - as long as I can connect to an external optical interconnect (available) I can conceivably connect 100,000 systems to a point-to-point switched interconnect at under 1 ns in a any-to-any and any-to-many configuration. Such a platform supports 1.4 petabytes per second simultaneous switching at under 1 KW. Using technology that exists today.
It really is all unicorns and rainbows.
I already have it working. If anyone would lie to peer review a paper illustrating it working - please DM me.
(and by peer review, I mean review a wannabe peer's work - I am truly working on better explaining why/how this really works)

/cloudfront-us-east-2.images.arcpublishing.com/reuters/NRT56KQMI5LQNC5TAURXVHWKDA.jpg)
 www.reuters.com
www.reuters.com