If you are not yet familiar with the term Convolutional Neural Networks, or CNN for short, you are certainly bound to become in the year ahead. Using Artificial Intelligence in the form of CNN is on the verge of replacing a large number of computing tasks, especially those involving recognizing things such as sounds, shapes, objects, and other patterns in data. Its applications are so widespread it would be hard to list them. However, one application stands out among all the rest – vision.
The demand for processing image data, in terms of the amount of data, is larger than any other and is growing at an accelerating rate. Using traditional methods, creating software for this task required describing what to look for and then creating custom code for that one application. The most obvious prerequisite for the traditional approach is the ability to describe or define the thing(s) to recognize. Once recognition code has been developed then comes the job of testing and then fixing all the corner cases.
No matter how good the recognition code, there is always the limitation that it is not possible to write code for an intangible quality, such as a fake smile versus a real smile. Our brains can do this, but writing code to differentiate between them is almost impossible. The other thing neural networks are good at is dealing with noisy input. Image data that might throw off a classical vision algorithm would work just fine when put through a neural network.

The approach in using CNN is to create a general purpose neural network and train it by providing input that matches the ‘target’. A neural network divides the source image into very small regions and performs a large number of parallel math operations on the pixels. The results are handed off to another layer which is not as complex but is still suitable for parallel processing. This is repeated many times, passing the data in a sequential manner through many processing layers until a result is achieved. At each stage during training there is back propagation to correct for errors. The result is a large number of coefficients that drive the neural network.
The same network implementation could be retrained to recognize a different target. All that is needed is retraining to create new coefficients. So by now it should be clear that training is a compute and memory intensive activity: something ideally suited for the cloud or large servers. Training can require from 10[SUP]22[/SUP] to 10[SUP]24[/SUP] operations. Where as, inference – the real time component of CNN used to recognize things – requires a far fewer 10[SUP]8[/SUP] to 10[SUP]12[/SUP] operations (i.e Multiply Accumulate, MAC).
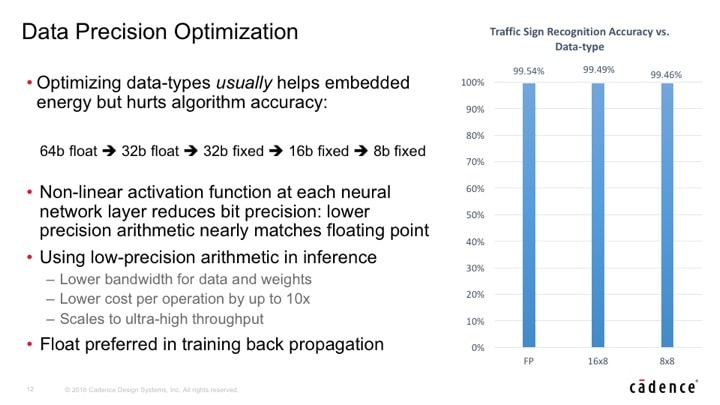
Furthermore, optimizations such as reducing the matrix size and coefficient precision are an active area of research, and if done properly have minimal impact of the quality of results. For instance, in one example going from floating point data to 8-bit integer coefficients only reduces accuracy from 99.54% to 99.41%. Most humans are not nearly that accurate when it comes to spotting a familiar face in a crowd. This means that with more computation in the training phase, the data set and number of operations for inference can be dramatically reduced.
The reason things are getting even more interesting now is that CNN is not just for super computers. The places where the applications for this technology exist are mobile – cars, phones, IoT devices. Overall since 1989 we have seen a 10[SUP]5[/SUP] increase in hardware performance, according to Nvidia’s Chief Scientist Bill Dally. This has made CNN practical. More interestingly, we have recently moved into a technology space where embedded CNN is feasible.
On February 9[SUP]th[/SUP] Cadence hosted a summit on Embedded Neural Networks which had an overflow crowd at their in-house auditorium. Not only are embedded neural networks starting to become practical, they are something that is creating significant interest.
The first speaker was Jeff Bier, president and founder of the Embedded Vision Alliance. One of the first things he did was show a video for a product that uses CNN on a tablet to interpret sign language. Jeff talked about how Neural Networks are ideal for otherwise difficult recognition problems. CNN really shines when the input varies because of lighting angles, orientation changes, and other noise in the input.
Next up was Bill Dally, Chief Scientist and SVP of Research at Nvidia. He drilled into the parallel nature of the solutions for CNN. He has spent a lot of time also looking at optimizations to reduce the footprint for the inference portion of CNN. Mobile applications are constrained by power and storage budgets. Using the cloud for CNN inference is not practical for the same basic reasons: too much data would need to be transferred to the cloud to do real time inference.
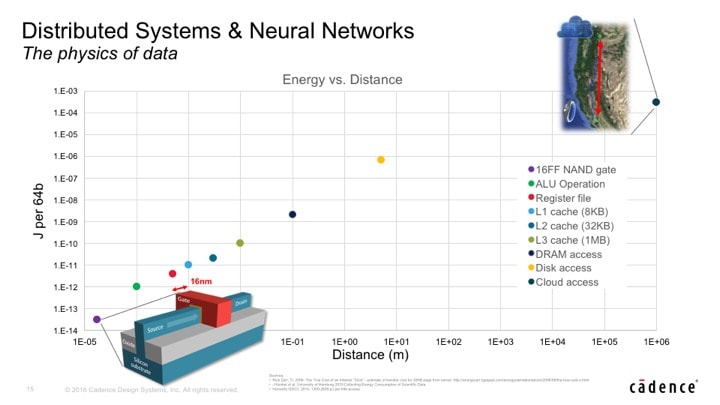
The energy cost of inference is tightly tied to how close the storage is to the compute resource. Much of Bill’s work has been to look at making it so that the data can reside as close to the processor(s) as possible. Here is a chart that shows the relative cost of different data locations.
Shrinking the neural network and reducing the data size for the neural network training coefficients can be done in clever ways to achieve stunning improvements. CNN has an inherent robustness that allows for large portions (up to 90%) of the neural network to be removed, then retrained with minimal loss in accuracy. So now it is possible to take neural networks that required over 1GB and fit them into 20-30MB – a size easily handled by a mobile device.
Google is even promoting its own open source CNN software and hopes that embedded platform developers and software developers will use it. Pete Warden, Staff Engineer at Google, came to the Cadence event to talk about his role in proliferating the use of their open source TensorFlow software, the technology they use internally. Google is making a long term commitment to its development and use. Their goal is to allow it to operate in SRAM and always stay on. They are working towards reducing the power requirements so that this is possible on mobile devices such as Android using the CPU or potentially GPU.
Cadence’s IP Group is very experienced with vision processing, and sees big growth and changes in this area. Neural Networks have the flexibility to be implemented on CPU’s, GPU’s, DSP’s and dedicated hardware. Each of these alternatives offer their own benefits and drawbacks. The hardware implementation area is moving as fast as the software for Neural Networks. Chris Rowen, CTO of the Cadence IP Group and one of the Founders of Tensilica, spoke at the Cadence event emphasizing that Neural Networks are definitely heading to embedded applications.
Right now there is a vigorous debate as to whether CPU’s, GPU’s or DSP’s will be the best vehicle for embedded inference applications. Tensilica offers a family of DSP’s focused on vision applications. Chris said that over 1 billion chips that have been manufactured with a Xtensa vision, imaging or video DSP on board. These are cores that are tuned for embedded applications and optimized for their specific applications.
Due to the fundamental shift from hard coded recognition software to neural networks the main task is now architecting the underlying network hardware, rather than writing code for recognizing specific things. This makes selecting the optimal processing architecture paramount.
In the years ahead we can expect to see remarkable progress in neural networks, and specifically with inference in embedded applications. Given the turnout at the Cadence event it is clear that many companies see this as an important area with big business potential.
More information about Cadence solutions for Neural Networks is available here.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.