
When PSS comes up, a lot of mainstream verification engineers are apt to get nervous. They worry that just as they’re starting to get the hang of UVM, the ivory tower types are changing the rules of dynamic verification again and that they’ll have to reboot all that hard-won UVM learning to a new language. The PSS community and tool makers work hard to dispel this fear by partitioning the roles of these languages (e.g. UVM for IP and PSS for SoC sequences and randomization) but questions remain; what about the grey areas between these two, and what about legacy UVM development? Also important, just how portable is PSS? In principle it’s perfectly portable but how does that work in practice? If I develop for one vendor’s platform will it work compatibly with another vendor?
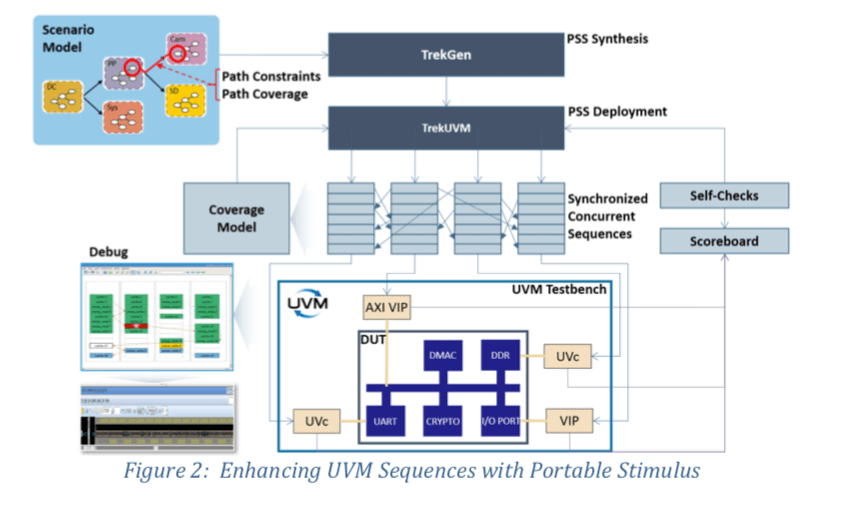
Starting with the last question, Breker has a natural advantage as a neutral player among simulation platform providers, which should give them best access to validate their solution against each platform. It should also make it easier for them to validate equivalent behavior (within the scope of the PSS standard) across platforms – i.e. true portability.
That answers one concern, but what about the legacy question – how much do you have to reinvent, versus building on UVM you already have (and will continue to develop)? To set your mind at rest, Breker have released a white paper on just that topic. This elaborates in some detail how you can use the Breker tools to model and generate randomized sequences, and then generate the corresponding UVM sequences (along with automated scoreboard and coverage modeling), which can connect to your UVM testbench.
The PSS modeling stage works as you would expect; you define PSS models using either DSL or C++, or through their graphical interface. The Breker TrekGen and Trek UVM tools read the model and synthesize tests based on flows and resource constraints (and even path constraints) defined in the model, then convert those to SystemVerilog tests. Generated score-boarding and coverage analysis will roll-up test pass/fail, profiling and other details for analysis in the Breker debugger and/or a vendor-supplier debugger to guide further refinement in scenario modeling.
Point here is that with Breker a PSS-based testing flow works hand-in-hand with your native UVM environment as an easier way to define, randomize and check coverage on sequences. No need to start over on any test-building; this is an entirely complementary addition to your flow.
The white-paper points out a number of advantages to using this approach over using UVM-based sequence definition and control:
- It’s a more efficient way to build useful sequence tests. Doing this in UVM is eminently possible, but it takes much more effort to build each sequence (or seed sequence with constraints) in a way that is guaranteed to connect meaningfully to real system behavior. PSS starts with expected system behavior, so each test is guaranteed to be meaningful. Which incidentally also accelerates test development and testing – always a desirable objective.
- The PSS approach is white-box versus black-box. Figuring out how to drive a path test in UVM can be hard – very hard. PSS removes need to think about these details in modeling and sequence generation, thanks to the internal smarts of the UVM generator.
- The PSS-based flow makes it possible to define more complex tests with more (allowed) concurrency. VIP models (an alternative) run independently, making it difficult to build tests around system-level concurrency, whereas these are easy to generate in PSS and constrain based on available resources as defined in the model.
- Score-boarding and checking is built-in – no extra effort on your part is required.
- Coverage is also built-in and is directly related to coverage of paths through the model, a concept that you can’t easily define through traditional coverage metrics. This for me is one of the big motivators for PSS. Traditional coverage is more or less useless at the system level. The useful metric in this context is coverage of realistic sequences constrained by available resources.
- You get automatic reusability both horizontally and vertically in design and verification flows – the “P” in PSS. Once you’ve defined models for a block, you can reuse those in higher-level subsystem or system testing; you can also reuse these models from simulation to emulation, FPGA prototyping, virtual prototyping and silicon testing.
There’s a lot more detail in the white paper that I won’t attempt to cover here, but I will add that Breker now includes a Portable Stimulus/UVM example with every software distribution. The design is a small representative SoC based on a couple of CPUs, a couple of UARTS, a DMAC and an AES encryption block. Most importantly the white paper provides a detailed walk-through of the steps in integrating this into a UVM testbench and then executing these together. Well worth a read if you’ve been wondering about PSS but have been nervous about jumping in.
Also Read
Verification 3.0 Holds it First Innovation Summit
CEO Interview: Adnan Hamid of Breker Systems
Breker Verification Systems Unleashes the SystemUVM Initiative to Empower UVM Engineering
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.