Standards committees, the military and governmental organizations are drawn to acronyms as moths are drawn to a flame, though few of them seem overly concerned with the elegance or memorability of these handles. One such example is SOTIF – Safety of the Intended Function – more formally known as ISO/PAS 21448. This is a follow-on to the more familiar ISO 26262. While 26262 provides processes and definitions for safety standards of the hardware in electrical and electronic systems in automobiles, it has little to say about the high-levels of automation that dominate debate around autonomous and semi-autonomous cars.
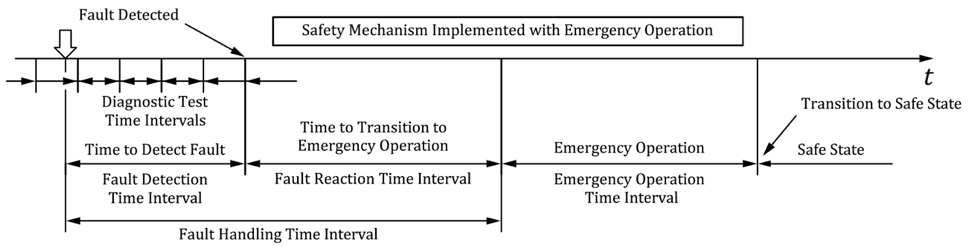
ISO 26262:2018 introduces the Emergency Operation Time Tolerance Interval to account for fail operational use cases
Safety at SAE level 2 and above automation is no longer simply a function of the safety of the hardware. When systems-on-chip are running complex software stacks, quite often multiple stacks, and those systems use probabilistic AI accelerators depending not only on software but also on arrays of trained weights, then there’s a lot more that can go wrong beyond the transient faults of 26262.
An SoC designer might assert “Yes these are problems, but they have nothing to do with my hardware. My responsibilities stop at ensuring that I meet the ISO 26262 requirements. All the rest is the responsibility of the system and software developers.” But you’d be wrong, based on where SOTIF is heading. High levels of integration and non-deterministic compute elements (AI) in safety-critical applications raise a new question; how should the system respond when something goes wrong? And how do you test for this? Because inevitably something will go wrong.
When you’re zipping down a busy freeway at 70mph and a safety-critical function misbehaves, traditional corrective actions (e.g., reset the SoC) are far too clumsy and may even compound the danger. You need something the industry calls “fail operational”, an architecture in which the consequences of a failure can be safely mitigated, possibly with somewhat degraded support in a fallback state, allowing for the car to get to the side of the road and/or for the failing system to be restored to a working state. According to Kurt Shuler (Arteris VP of marketing and an ISO 26262 working group member), a good explanation of this concept is covered in ISO 26262:2018 Part 10 (chapter 12, clauses 12.1 to 12.3). The system-level details of how the car should handle failures of this type are decided by the auto OEMs (and perhaps tier 1s) and the consequences can reach all the way down into SoC design. Importantly, there are capabilities at the SoC-level that can be implemented to help enable fail operational.
Redundancy engineering is becoming more important in SoC functional safety mechanism design. In safety-critical areas in the design, you use two or more versions in parallel and compare the outputs. This is called static redundancy and sounds suspiciously like the TMR, lockstep computing and similar safety mechanisms you already use for ISO 26262. And to some extent they are. But as I understand it, there are a couple of key differences. First these requirements are likely to come from the OEM (or Tier 1), over and above anything you plan to add for redundancy. And second, in a number of redundancy configurations (called dynamic redundancy), these independent systems are expected to self-check their correctness. For example, there is a redundancy style called “1 out of 2 with diagnostics” (1oo2d) in which perhaps 2 cores would each compute a result in parallel, and also each provide a self-check diagnostic. The comparison step can then feed-forward a fail-operational result if both cores self-check positively and agree, or if one core self-checks positively and the other does not.
Another major component of fail-operational support requires the ability to selectively reset/reboot subsystems in the SoC. A very realistic example in this context would be for a smart sensor SoC containing (among many subsystems) one or more vision subsystems (ISPs) and one or more machine learning (ML) subsystems. On a failure in one of these subsystems, rebooting selectively allows other object-recognition paths to continue working. This obviously requires a method to isolate individual subsystems so that the rest of the system can be insulated from anomalous behavior as the misbehaving subsystem resets. One SoC network-on-chip interconnect company, Arteris IP, is already pioneering technology to enable this.
Redundancy in ML subsystems as described above allows for one class of failures in recognition, but what about failures resulting from training problems? One idea that has been suggested (though I don’t know if anyone has put it into practice) is to use asymmetric redundancy between two ML system trained on different training sets. It will be interesting to see how that debate evolves.
The system interconnect is the ideal place to manage a lot of this functionality in the SoC, from “M out of N” redundancy (maybe with diagnostics) to isolation for selective reset/reboot. Arteris IP have made significant and well-respected investments in this area. You should check them out.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.