The ISO 26262 standard defines four Automotive Safety Integrity Levels (ASILs), from A to D, technically measures of risk rather than safety mechanisms, of which ASIL-D is the highest. ASIL-D represents a failure potentially causing severe or fatal injury in a reasonably common situation over which the driver has little control. Certification to one or more of these levels requires demonstrating that a system can guarantee better than a specified probability of failure, generally requiring increasing levels of failure mitigation, analysis and supporting documentation with each level.
Semiconductor component providers have opted in many cases for certification to component levels below D for cost and/or time-to-market reasons. But this is changing. As electronic content in our cars is increasing, distinctions between what does and does not critically affect safety are blurring. An ECU that might be used in an ASIL-B function today could become interesting for use in an ASIL-D function next year. Consequently, OEMs are extending their demands for ASIL-D certification across more components, to ensure they’re covered no matter what the application.
This ramps up effort demanded in safety assurance in more designs. Certainly component functions must demonstrate mitigation to an appropriate level, but also special care is needed in integrating those components together, commonly through a NoC interconnect. There are three approaches that designers can take to ASIL-D compliance for that network-on-chip:
- Complete replication (in this case the NoC), either duplication with comparison checks which will report a failure (where it is sufficient to warn the driver that a function has failed) or triplication with majority voting where a failure in one function can be overridden by outputs from two good functions (where simply knowing a system has failed is not enough). Still, complete duplication or replication of a NoC would be a very expensive option.
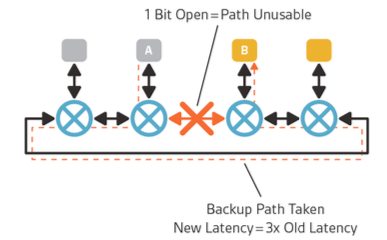
- Another acceptable approach is to provide path diversity. If a component fails in one path, there should be other paths through which system operation can continue to work, possibly after updating routing tables. In effect the system can heal around bad nodes and continue to operate. The challenge here is that the designer must prove that all possible paths have backup paths, again likely to be expensive. A second consequence is that performance impact from possible rerouting has to be characterized, potentially as rigorously as for the good part. And finally updating the routing is a software function which will take time and adds further risk, and that must also be characterized and mitigated.
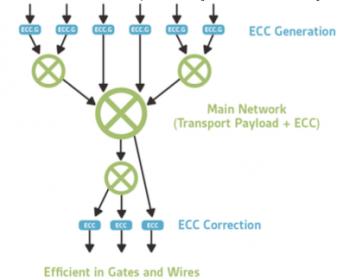
- A less expensive and disruptive approach is to replicate only those functions within the NoC that must be replicated, such as control blocks, and to use ECC on interconnect wires to correct single-bit errors and flag 2-bit errors. This approach still meets the ASIL-D requirement, avoids all the complications associated with path diversity and has limited area overhead since control blocks represent a relatively small percentage of the overall NoC area.
For a way to meet these new stringent requirements, the last method above is difficult to beat. Adding 8-bits of ECC to a 64-bit link increases the size of the NoC by a little over 10%, versus doubling the size if duplicating the NoC. The solution is entirely in hardware and errors are corrected instantaneously with no need for software reconfiguration and no extra latencies. Finally, validating fault coverage and building a comprehensive FMEDA for the configured network can be completed with existing tools, compared with a path diversity approach which would require analysis over both hardware and network reconfiguration software.
To learn more about Arteris solutions for ASIL-D-compliant NoC interconnect, go HERE.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.