Machine learning (ML), and neural nets (NNs) as a subset of ML, are blossoming in all sorts of applications, not just in the cloud but now even more at the edge. We can now find them in our phones, in our cars, even in IoT applications. We have all seen applications for intelligent vision (e.g. pedestrian detection) and voice recognition (e.g. speaker ID for smart speakers). In a compelling demonstration of just how widely application is spreading, one IP vendor recently announced a 5G modem sub-system using neural nets in support of link-adaptation (optimizing the link between the UE and the base station). The sky truly seems to be the limit for this technology.
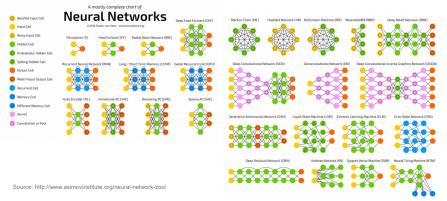
An important question for this audience is what hardware architectures are needed in support of these systems, particularly at the edge. Here power/energy is much more important than in the cloud, yet performance is also important to complete complex recognition tasks in milli- or micro-seconds (long/variable delays are sub-optimal when deciding if the car needs to slam on the brakes).
Also, while we originally thought that we only needed to do training in the cloud and could do skinnied-down inference at the edge, now we’re finding applications where re-training at the edge becomes important. Your car has driver face-ID, you break your leg on a hike in the remote backwoods, fortunately someone is with you so can drive you to the hospital, but they never trained the car to recognize them and, oops, there’s no cell reception to support cloud-based training. In this case, maximally-reduced NNs (which can’t support local training) may not be the way to go.
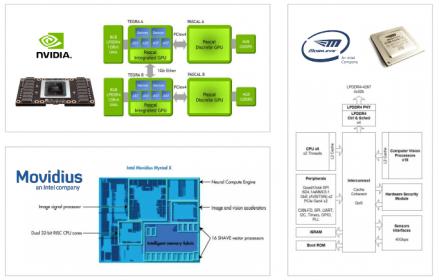
All of which means that often there is no one best architecture choice; platforms must host a range of options to suit different needs. The range can be pretty wide – GPUs with fixed-point compute (lower power than floating-point), also specialized accelerators: FFTs, custom vector and matrix compute engines, support for flexible operand bit widths (8->4->2) through NN flows, and low word-size weights. More specialized still are architectures such as grids of interconnected processing elements, offering higher performance at lower power through closely-coupled compute for NN (and I would guess neuromorphic) applications.
A common factor in all these applications is minimizing DRAM accesses, since each neuron MAC operation requires 3 reads (weight, activation and partial sum) and one write (new partial sum). In AlexNet, a well-known reference network in the domain, 3 billion memory accesses are required to complete a recognition. If all this went straight to DRAM, performance and power would be wildly impractical. In conventional compute architectures you mitigate with layers of caching. In some of these more exotic architectures, multiple caching strategies are required – local register files, closely-coupled memories, internal (to the accelerator) SRAM and common buffer RAMs.
Cache coherence then becomes important at the accelerator level and at the SoC level. NN algorithms are very regular but intrinsically 2-D (for image recognition at least) and area-performance tradeoffs limit how much tightly-coupled memories can hold. As you might guess, given this problem definition, there are multiple strategies for optimizing locality of reference – around weights, around MAC outputs, even around rows in the (current) image. Whichever strategy is employed, in large systems and systems supporting feedback such as RNNs, processing elements ultimately have to share memory (also with the CPU/ GPU subsystem running the show), which of course they must do coherently if recognition is not to become scrambled.
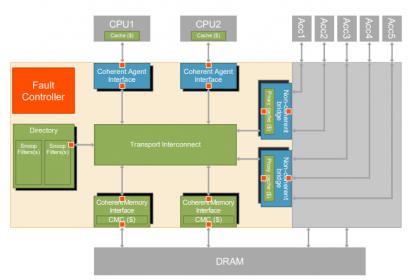
I wrote in my last blog about how Arteris supports cache-coherent connectivity through their Ncore 3 interconnect fabric and how non-coherent peers on a FlexNoC interconnect can tie into the coherent network through proxy caches. This has apparently become of particular interest in integrating NN accelerators which can use these proxy caches to sync not only with the main coherent network but also with each other. An added benefit is that these caches can be optimized to use-case needs which is important for such specialized architectures.
Ncore also provides support for functional safety in the generated interconnect, a must-have for ADAS and autonomy applications these days. They do this through a Resilience option to Ncore, providing data protection (parity for data paths and ECC for memory paths), intelligent unit duplication and checking (similar to dual-core lockstep – DCLS), and a fault controller with BIST that is automatically configured and connected based on the designer’s data protection and hardware duplication settings. These capabilities can be combined to provide sufficient diagnostic coverage to meet automotive ISO 26262 functional safety certification requirements, as well as the more general IEC 61508 specification.
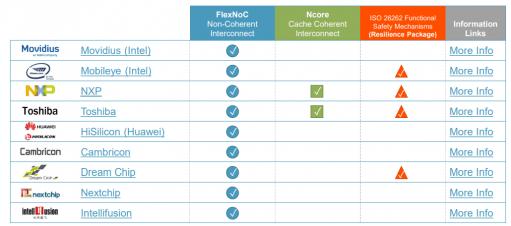
Arteris are obviously making waves, judging by the list of companies that have adopted their solutions for ML/NN applications. I would guess that differing adoption of Ncore versus FlexNoc reflects the wide range of architecture approaches I discussed earlier. You can learn more about the Arteris solution and AI HERE. If you have the patience for a long paper, THIS is an excellent read on differing approaches to hardware for NNs.




Comments
2 Replies to “Machine Learning Neural Nets and the On-Chip Network”
You must register or log in to view/post comments.