The potential for AI in cars, whether for driver assistance or full autonomy, has been trumpeted everywhere and continues to grow. Within the car we have vision, radar and ultrasonic sensors to detect obstacles in front, behind and to the side of the car. Outside the car, V2x promises to share real-time information between vehicles and other sources so we can see ahead of vehicles in front of us, around corners to detect hazards, and see congested traffic and emergency vehicles. Also this AI can improve on the fly, adapting to new conditions through training updates from the cloud.
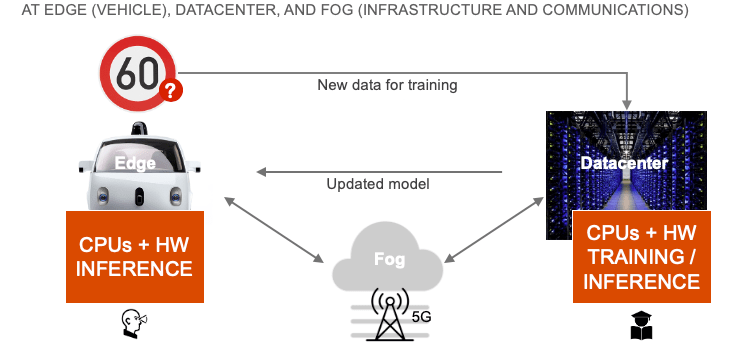
This all sounds wonderful, but of course implementation is much more complex than the vision. It demands a lot of specialized devices, each with its own constraints in performance, latency (how quickly it can respond to a change) and power consumption. Put them all together in the car and more constraints emerge: How well can the central brain respond to the massive flow of data being generated by all these sensors? Will it become bogged down and not be able to respond quickly enough to a pedestrian ahead of the car? Will AI be more reliable if object-based or rule-based or a combination of the two? Most important of all, will it be safe?
Taken together, it’s not surprising that the nirvana of full autonomy isn’t right around the corner. But progress is being made, bottom-up as it should be. A good place to see this in action is at the edge of the car, in sensors, sensor fusion and local AI.
Memory Implications
AI is being pushed to the edge. This is not new. Transmitting raw video or radar or ultrasonic streams would bog down the car network, create massive latency and burn a lot of power. Doing all the object detection and fusion close to the sensor reduces those problems. For cost, reliability and again, power reasons, it’s better per sensor cluster to do all of that in one chip.
Now you need to integrate onto a single chip support for multiple AI subsystems along with other administrative and safety functions. This has some interesting design implications. To manage power and latency it is important to share memory between central compute and the AI accelerators. You don’t want to have to go out to external memory any more than absolutely necessary because that’s much slower and burns more power than staying on chip. Further, as more accelerators and compute clusters are added to the system-on-chip it become nearly impossible to efficiently manage the data flow using software only. Therefore the AI accelerator subsystems must be cache coherent with the rest of the chip (CPU cluster, memory subsystem, communication, etc).
Cache coherence goes further. Within that group of AI accelerators it may be important to share memory, in fusion for example. Which means you need cache coherence between accelerators. But you don’t necessarily want to pay the penalty every time for coherence with the whole system; most of the time coherence is needed just between accelerators. Now you want hierarchical cache coherence – between accelerators at one level, then to the full system at the top. Kurt Shuler (VP Marketing at Arteris IP) told me cache coherence requirements of this kind are becoming more common in automotive applications, because they’re dealing with big images across more accelerators, yet they still need to manage to a tight power and performance budget.
Safety
What about safety? There is a larger question of how you quantify safety in non-deterministic systems, as most machine-learning based systems are. This is where SOTIF (ISO/PAS 21448:2019) and UL4600 are headed. But even before we get there, how do ISO 26262 and AI interact? Most accelerators so far have not been ASIL-rated, so must be managed in a larger system aiming for ASIL D compliance.
This mix of safety standards and levels is pushing a trend to a safety island on the system on chip (SoC) to monitor system safety, along with an ability to isolate each IP on the interconnect in turn for temporary in-service testing, or longer-term isolation if an IP is found not to be performing to expectations.
This level of monitoring acknowledges a few realities. We may never be able to build large SoCs in which each component can be brought up to ASIL D. Components will fail; systems must self-monitor to determine if this may be about to happen or has happened and must provide means for self-correction where possible (through say a soft reboot of a subsystem). And where a problem cannot be corrected, systems must provide notification to the central control to enable a fail-operational response – maybe the driver should retake control of the car.
Could AI be accelerators be brought up to ASIL D? This is still very much a research topic. A lot of work has been done on the software side. In hardware, Kurt tells me that attention is mostly on conventional functional safety (FuSa) for the various elements inside the accelerator. One interesting observation he made was that FuSa seems to be more important in later planes in the neural net. Sensitivity to errors in earlier planes is not as strong. Interesting topic to follow!
Interconnect Implications
One thing is clear. The interconnect becomes the backbone for mediating all this activity – coherent caching and safety. Coherent caching because a full SoC is inevitably going to depend on a mix of IPs from multiple suppliers, yet caching must still be managed coherently across all those IPs.
And safety because the NoC or NoCs running through these systems must interconnect a wide range of IPs with differing ASIL capabilities. Some of those IPs can be very exotic indeed, serving the needs of some of the most advanced AI suppliers. NoCs must enable and mediate this trend to safety islands, self-testing and isolation support, while also providing safety control and monitoring within the network itself.
This is a complex and fast-moving range of needs. Arteris IP is clearly working to keep up with these needs. Kurt is on the ISO 26262 working group, and they work with a lot of AI companies, including some of the most prominent in automotive applications. Check them out.
Also Read:
Autonomous Driving Still Terra Incognita
Evolving Landscape of Self-Driving Safety Standards
Safety and Platform-Based Design
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.