
The field of DRAM is fascinating as it continues to grow and innovate. For the past ten years, I have often read that DRAM is running out of steam because of its difficulty to scale the capacitor, and yet it continues to evolve since invented by Dr. R. Dennard at IBM. In 1966, he introduced the concept of a transistor memory cell consisting of one transistor and one capacitor. His invention was granted a patent (US3387286) in 1968. The overall configuration of one transistor memory cell has not changed over the years. Today — fifty-five years later — we have three manufacturers in 1X nodes with a memory capacity greater than 4 Gb, who still fabricate their memory cells with the same configuration consisting of one transistor and one capacitor. Micron’s D1α, which is the most advanced DRAM and is the first sub-15nm cell design, has an impressive memory capacity of 8 Gb.
Every new DRAM technology node produces chips that are smaller and more compact than their predecessors. This scaling allows more dies per wafer which offsets the increasing manufacturing cost of introducing new technology. Every new node not only shrinks the cell size, but also introduces new materials or new architecture layouts. The DRAM technology has moved from trench capacitors to stacked capacitors. The capacitor dielectric has changed from a single high-K layer to multiple dielectric layers, with the capacitor structure evolving from a crown structure to a pillar structure and the layout now modified from 10F2 to 8F2to 6F2, where F is the minimum feature size.
I was particularly interested in the cell layout and considered it to be a strong parameter to enable reduction of cell size. Micron was the first company to switch from 8F2 to 6F2 cell layout at 9x nm node, followed by Samsung at 80 nm node and finally SK-Hynix, which also adopted the 6F2 cell layout at 3x nm node. I keep wondering when will a 4F2 be adopted? In a 4F2 cell, the wordline pitch and the bitline pitch are exactly 2F. The 4F2 configuration requires a surrounded vertical gate structure. This concept has still not materialized even though there have been major advancements in patterning and lithography as it is more cost effective to stay with the same type of architecture and simply make modifications rather than adopting a completely new design.
Working for an IP centric company, I was able to quickly check the status of DRAM 4F2 patents and was surprised to find that the total number of alive patents filed in the US by the three major memory makers (Samsung, Micron, and SK-Hynix) is less than a couple of hundred and that the filing activity after the year 2015 is sparse. This seems to indicate that the industry is focused on something else.
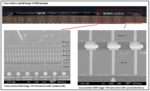
The main challenge of DRAM is bandwidth and latency. Bandwidth is the quantity of data that can be written on to the memory or can be read from it, while latency is the time gap between the request to the memory and its execution. This topic is of current interest in the memory industry. The biggest relief in bandwidth came in 2013 with the introduction of High-bandwidth-memory (HBM) where stacked DRAM dies were connected to each other by through-silicon-vias (TSV). Figure 1 shows a picture of HBM analyzed at UnitedLex in 2018 for supporting IP activities. The HBM along with its TSV structures improved the data transfer between the logic process and the memory but it did not solve the “memory wall” problem entirely.
Figure 1: Cross-section of HBM (UnitedLex)
I often wondered what the next steps would be, I then came across the proceedings of the Electronic Components and Technology Conference 2021(ECTC), which is one of the premier international events related to packaging, components, and microelectronic systems. This conference had papers from major device makers like GlobalFoundries, IBM, Intel, Micron Samsung, and TSMC. All these companies discussed hybrid bonding, direct bonding, die to die connections, and various TSV-less solutions. The one paper that caught my attention was authored by Micron Memory Japan, along with several other research organizations, and titled “Ultra-thinning of 20 nm Node DRAMS down to 3 µm for Wafer-on-Wafer (WOW) applications”. This paper describes how they thinned the wafers using two different methods namely grinding and chemical mechanical polishing (CMP) and compared retention time of the DRAM before and after the thinning. They concluded that the retention properties had not deteriorated due to the thinning process.
This was indeed a “WOW” paper. Ever since HBM was introduced, the wafer thickness has plummeted from a few hundreds of micrometers to around 40 µm but going to 3 µm is something extraordinary. Just in comparison, the human hair is around 70 µm ±20 µm. The combination of hybrid bonding and wafer thinning opens new possibilities for DRAM. In hybrid bonding the metallic bond pads of two wafers are directly connected as well as the dielectric materials adjacent to them which are also connected. Hybrid bonding is used in the industry and has been employed by Sony in their image sensors, however, as of today it has not yet been implemented in stacked DRAM products. One of the challenges of hybrid bonding is that it requires a clean interface at an atomic plane level.
The production of thin wafers along with hybrid bonding would greatly reduce the TSV impedance, it would also increase data bandwidth, reduce thermal resistance, and finally increase the density of interconnects. If such a technique were to be used then the image on figure one would not have the conductive bumps seen between the dies and the memory die thickness would be ten times thinner, which would lead to a considerable overall reduction of the height of the stack. This combination of ultra-thin wafers with hybrid bonding will extend the life of DRAM devices more easily than adopting a completely new configuration like monolithic 3D DRAM which is being lately discussed in the scientific community. New applications, like using a DRAM stack directly bonded onto a logic chip could be envisaged, or it could be used as the cache memory, like AMD and some others are implementing with their external SRAM memory. Of course, for DRAM devices, some architecture designs would need to be modified because as of today, SRAM is better than DRAM in terms of latency. Mounting thin DRAM dies on logic dies could also bring new concepts like compute in memory, where the base die in HBM could have some computing power.
DRAM devices are far from being at the end of their lives and still have many miles to go. It will need to be further shrunk to reduce costs. Probably in the future, the periphery circuitry will also be scaled or even taken out of the DRAM die and be fabricated as an independent chip and then be mounted on the DRAM using ultra thinning process and hybrid bonding technology. The combination of advanced lithography and patterning, the possibility of disaggregating periphery circuitry into individual small chips (or “chiplet”) configuration, the availability of wafer thinning process and hybrid bonding technology has rejuvenated the DRAM devices. Most likely DRAM is not ceding its place to any other memory soon. I am also hoping that there will be a breakthrough in design and process technology so that monolithic DRAM with 4F2 cell layout will be available in the market soon.
At UnitedLex, we monitor and analyze both the technology and patents that surround the IC eco-system. By doing this, we are well positioned to help clients track the innovations being implemented in industry but also, strategically guide clients on how to optimize their patent portfolios.







