

Investing in semiconductor startups is something Silicon Catalyst knows a lot about. During a time when venture funding for chip companies all but disappeared, this remarkable organization built a robust incubator, ecosystem, support infrastructure and funding source. Silicon Catalyst has assembled a top-notch management team and an extensive, world-class advisor network. You can learn more about this remarkable organization here. Silicon Catalyst also has a great track record for putting on compelling events with A-list participants. You can read SemiWiki coverage of their most recent event here. So, when Silicon Catalyst announces a webinar on investing in semiconductor startups, you must take notice.
Chips are Popular Again
It appears the rest of the world is now seeing what Silicon Catalyst saw all along. As stated by Silicon Catalyst:
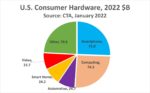
Following a remarkable year of over 25% year on year growth, the global semiconductor industry is poised to experience strong growth in 2022. World-wide sales for this year are projected to reach in excess of $600 billion in what many are calling the golden era of semiconductors.
Chips are indeed hot again. Another interesting fact courtesy of Silicon Catalyst:
Nuvia is a great example, having taken their first round of money in April 2019 at a post-money valuation of $16 million and being acquired by Qualcomm in March of 2021 for over $1.2 billion.
Examples like this are truly remarkable. They also don’t happen every day. For every home run, there are many more failures. Understanding the trends and developing insight to spot the companies that are correctly leveraging those trends is the focus of the upcoming webinar. As usual, Silicon Catalyst has assembled an all-star cast to discuss these topics. We can all learn a lot from these folks, so I highly recommend you attend this event. More information is coming.
An All-Star Cast Weighs In
First, let’s look at the panel lineup. A stellar group from around the world.
Moderator
- Cliff Hirsch, Semiconductor Times. Cliff has extreme depth and breadth in semiconductors and related technologies, communications, data/telecom network infrastructure, and open-source web technology. He has analyzed greater than 4,000 private and public companies in the semiconductor & comm/IT space. Check out the latest news on semiconductor startups here.
Panelists
- Rajeev Madhavan, North America, Clear Ventures. Rajeev is a founder and General Partner of Clear, where he focuses on early-stage technology investments. His notable career exits include Apigee (IPO), YuMe (IPO), Virident (acquired), Magma (IPO), Groupon (IPO), VxTel (acquired), LogicVision (IPO) and Ambit (acquired). Rajeev has the uncanny ability to deeply understand what entrepreneurs are trying to do, and to steer them onto a successful path. I know Rajeev. He truly has the golden touch.
- Emily Meads, EU, Speed Invest. Emily passionately supports Deep Tech companies and the Deep Tech ecosystem, and always strives to give scientific credibility to the VC side of the table. Before joining Speedinvest, Emily worked for Fraunhofer IZM, as well as a software engineering startup where she first caught the startup bug. She then worked at Spin Up Science where she specifically supported innovators on their Deep Tech commercialization journeys.
- Dov Moran, Israel: Grove Venture Capital. Dov Moran is one of Israel’s most prominent hi-tech leaders, entrepreneurs and investors. He is known as a pioneer of several flash memory technologies, most notably as the inventor of the USB flash drive. Dov was a founder and CEO of M-Systems (NSDQ: FLSH), a world leader in the flash data storage market. Under Dov’s leadership, M-Systems grew to $1B revenue, and was acquired by SanDisk Corp (NSDQ: SNDK) for $1.6B.
- Owen Metters, UK, Foresight Williams Technology Funds. Dr. Metters is an Investment Manager at Williams Advanced Engineering (WAE). He has worked at Oxford University Innovation, the technology transfer organization for the University of Oxford, supporting academics in the commercialization of University IP leading to the formation of several successful spin-out companies which have then raised over £20m of VC funding & holds a PhD in Inorganic & Materials Chemistry from Bristol University.
And a special presentation: Semi Industry Trends and Market Opportunities for 2022, presented by:
- Junko Yoshida, Editor in Chief, The Ojo-Yoshida Report. Junko has always been a “roving reporter” in the most literal sense. After logging 11 years of international experience at a Japanese consumer electronics company, Junko pursued journalism, breaking stories, securing exclusives, and filing incisive analyses from Tokyo, Silicon Valley, Paris, New York, and China. During her three decades at EE Times, Junko rose through the ranks from Tokyo correspondent to West Coast bureau chief, European bureau chief, news editor, and editor-in-chief.
I know Junko and I find this part quite exciting. She is someone who will always find the hidden truth in every story. Her insights are legendary. I can’t wait to hear her perspectives in her new role. She will be joined by Bolaji Ojo, Publisher and Managing Editor @The Ojo-Yoshida Report.
Junko has offered some comments about the upcoming event. Consider this a sample of what’s to come:
“Semiconductors are the lifeblood of today’s economy. It is pouring into every economic sector, at different speeds and vigor. This means there are huge investment opportunities yet to be tapped in semiconductors using new products and old ones that are finding new applications. Finding where to strategically put investment dollars in semiconductors should be a passion for every investor because this process will endure for a while. The Ojo-Yoshida Report identifies certain technology segments and market applications investors should be paying attention to.”
How to Attend the Webinar
The webinar will be held on Zoom and is open to the public. Attendees will be able to submit questions to the panel and they will be addressed as time permits.
January 19, 2022, 09:00 AM in Pacific Time (US and Canada)
You can register for the webinar on investing in semiconductor startups here.
Also Read:
Silicon Catalyst Hosts an All-Star Panel December 8th to Discuss What Happens Next?
Silicon Startups, Arm Yourself and Catalyze Your Success…. Spotlight: Semiconductor Conferences
WEBINAR: Maximizing Exit Valuations for Technology Companies




{kind=link}
{kind=link}
{kind=link}