
Let’s face it. Standards aren’t always exciting, and the process of ratifying new versions can be time-consuming and tedious. Regardless, we all know standards are the glue that bind many ecosystems and without them the technology world would be good measure more chaotic. Standards come in many versions, with various amounts of reach and impact. In this post I will explore the Peripheral Component Interconnect Express standard, or PCIe for short. This standard has far-reaching consequences, it is truly the silent partner of innovation in our world.
What is It, Why Does It Matter?
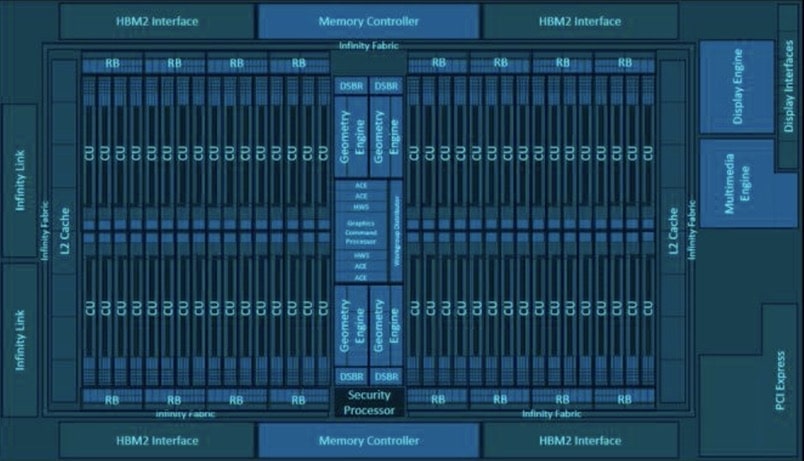
PCIe is a high-speed serial computer expansion bus standard. Its mission is to deliver high bandwidth, low latency, and low power communication between components in a computer system. Devices that use this standard include graphics cards and GPUs, all forms of storage including SSDs, network interfaces, WiFi and Bluetooth interfaces. Essentially, many of the technologies that fuel next-generation innovation.
The PCI Special Interest Group has done a remarkable job at keeping the standard evolving and vibrant. The group has delivered a doubling of PCI Express speeds around every three years ever since the introduction of the spec in 2003. The latest version, PCIe 6.0, overhauls the signaling technology to achieve bandwidth gains while maintaining low latency. The new architecture also maintains compatibility with all previous generations of PCIe. This is not easy to do but will certainly help with adoption for existing designs.
Each generation of the standard also supports multiple data lanes, from 1 to 16. This allows the standard to be used in all kinds of applications, from hand-held devices to server-class computing. Data Center, Artificial Intelligence/Machine Learning, HPC, Automotive, IoT, and Military/Aerospace are all markets that have benefitted from the PCIe standard.
And How Does It Impact the World Around Us?
Standards are nice; a working implementation of the standard is what drives innovation, however. When it comes to implementing high-performance channels, my go-to organization is Samtec. They are always at the forefront of high-speed channels. Their products are essentially the cohesive force for any new idea. Without the ability to move data, any idea is interesting but not practical. You can learn more about Samtec’s products and people on SemiWiki here.
As I dug into the latest information on its website, I found what I was looking for; real hardware solving real problems. The first item I found was a demo that uses the PCIe 6.0 standard. This is real cutting-edge stuff as the standard was just released earlier this year. It normally takes quite a while to see real implementations of a new standard and this demo was done right around the time of the standard’s release.
The demo showcases a PCIe Gen 6.0 AI hardware design based on the GenZ PCIe enclosure compatible form factor (PECFF). Working with Synopsys, a GENZ motherboard is combined with GENZ Add-In-Cards with top card connectivity. This design emulates industry standard AI acceleration hardware platforms. The Synopsys PCIe 6.0 PHY generates up to four 64 GT/s PAM4 differential signals in the demo. You can see a short, very informative video of this demo here.
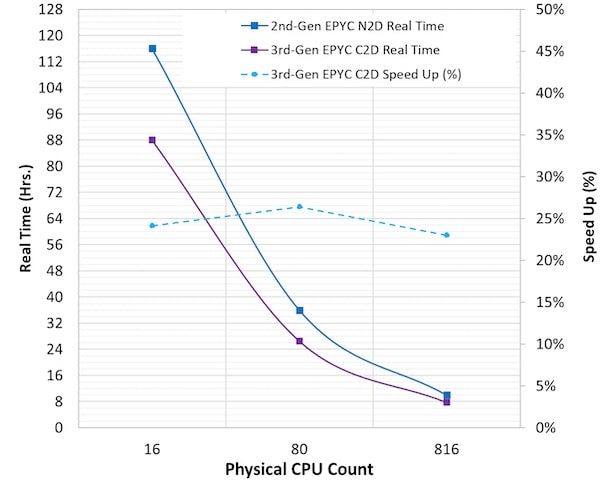
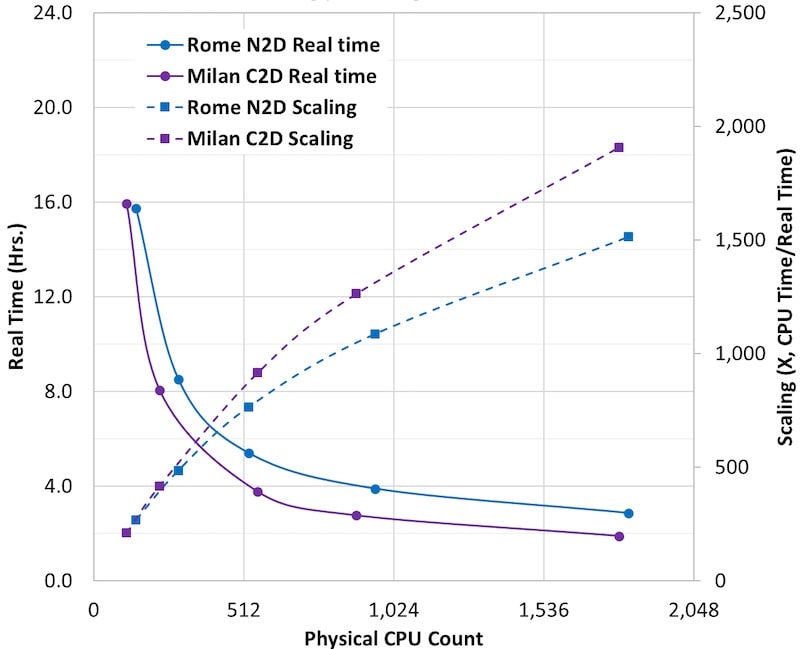
I also found a Samtec demonstration based on PCIe Gen 4.0. This demo highlighs Samtec’s PCIe®-Over-Fiber FireFly™ Adapter Card (PCOA Series), developed by its partner, Dolphin. The PCOA series utilizes Samtec’s PCI Express®-Over-Fiber FireFly™ Optical Cable Assemblies (PCUO series). It turns out Samtec is the only company in the world offering reset functionality and cable present sidebands in this form factor.
One of the new features of the adapter card is the capability to do a surprise hot add. A surprise hot add feature allows a new resource to be added to a system that is already running. The resource can be a storage device, camera, a GPU or an FPGA. This allows a new resource to be added and be available without shutting down the server. Without the surprise hot add, the host needs to be rebooted to enumerate and find the PCIe devices attached to the server, a much more cumbersome process. You can also see a short and informative video of this demo here.
The Momentum Keeps Building
There is significant momentum building for PCIe deployments. The PCI-SIG Developers Conference series for 2022 just kicked off in Santa Clara this past June. In case you missed it, there are more events happening around the world in later this year in Asia, Israel and Europe. You can learn more about Samtec’s support for PCIe here and download an overview of its various solutions here. PCIe is definitely creating big opportunities. It is truly the silent partner of innovation in our world.
Also read:
A MasterClass in Signal Path Design with Samtec’s Scott McMorrow
Passion for Innovation – an Interview with Samtec’s Keith Guetig
Webinar: The Backstory of PCIe 6.0 for HPC, From IP to Interconnect






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}