Given popular fascination it seems impossible these days to talk about anything other than AI. At CadenceLIVE, it was refreshing to be reminded that the foundational methods on which designs of any type remain and will always be dominated in all aspects of engineering by deep, precise, and scalable math, physics, computer science and chemistry. AI complements design technologies, allowing engineers to explore more options and optimizations. But it will continue to stand on the shoulders of 200+ years of accumulated STEM expertise and computational methods as a wrapper around but not displacing those methods.
Granting this observation, where is AI useful in electronic design systems methods, and more generally, how do AI and other technologies affect business shifts in the semiconductor and electronic systems industries? That’s the subject of the rest of this blog.
AI in Cadence Products
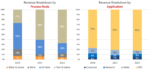
Cadence clearly intends to be a front-runner in AI applications. Over the last few years, they have announced several AI-powered products—Cadence Cerebrus for physical synthesis, Verisium for verification, Joint Enterprise Data and AI (JedAI) for unifying massive data sets, and Optimality for multi-physics optimization. Recently, they added Virtuoso extensions for analog design, Allegro X AI for advanced PCB, and Integrity for 3D-IC designs.
As a physical synthesis product, I expect Cadence Cerebrus to be primarily aimed at block design for the same reasons I mentioned in an earlier blog. Here, I expect that reinforcement learning around multiple full physical synthesis runs drives wider exploration of options and better ultimate PPA.
Verisium has a quite broad objective in verification, spanning debug and test suite optimization, for example, in addition to block-level coverage optimization. Aside from block level coverage, I expect other aspects to offer value across the design spectrum, again based on reinforcement learning over multiple runs (and perhaps even between products in the same family).
Optimality is intrinsically a system-level analysis and optimization suite. Here, also, reinforcement learning across multiple runs can help complex multi-physics analyses—electromagnetics, thermal, signal and power integrity—to converge over more samples than would be feasible to consider in traditional manual iteration.
Virtuoso Studio for analog is intrinsically a block-level design tool because no one, to my knowledge, is building full-chip analog designs at the SoC scale (with the exception of memories and perhaps neuromorphic stuff). Automation in analog design has been a hoped for but unreached goal for decades. Virtuoso is now offering learning-based methods for placement and routing, which sounds intriguing.
Allegro X AI aims for similar goals in PCB design, offering automated PCB placement and routing. The website suggests they are using generative techniques here, right on the leading edge of AI today. The Integrity platform builds upon the large database capacity of the Innovus Implementation System and leverages both Virtuoso and Allegro for analog RF and package co-design, providing a comprehensive and unified solution 3D-IC designs.
Three Perspectives on Adapting to Change
It’s no secret that markets are changing rapidly in response to multiple emerging technologies (including AI) and faster moving changes in systems markets as well as economic and geopolitical stresses. One very apparent change in our world is the rapid growth of chip design in-house among systems companies. Why is that happening and how are semiconductor and EDA companies adapting?
A Systems Perspective from Google Cloud
Thomas Kurian, CEO of Google Cloud talked with Anirudh on trends in the cloud and chip design needs. He walked through the evolution of demand for cloud computing, starting with Software-as-a-Service (SaaS), driven by applications from Intuit and Salesforce. From there, the landscape progressed to Infrastructure-as-a-Service (IaaS) allowing us to buy elastic access to compute hardware without the need to manage that hardware.
Now Thomas sees digitalization as the principal driver: in cars, cell phones, home appliances, industrial machines. As digitalization advances happen, digital twins have become popular to model and optimize virtualized processes, applying deep learning to explore a wider range of possibilities.
To support this objective at scale, Google wants to be able to treat worldwide networked data centers as a unified compute resource, connecting through super low latency network fabrics for predictable performance and latency no matter how workloads are distributed. Meeting that goal demands a lot of custom semiconductor design for networking, for storage, for AI engines, and for other accelerators. Thomas believes that in certain critical areas they can build differentiated solutions meeting their CAPEX and OPEX goals better than through externally sourced semiconductors.
Why? It’s not always practical for an external supplier to test at true systems scale. Who can reproduce streaming video traffic at the scale of a Google or AWS or Microsoft? Also, in building system process differentiation, optimizing components helps, but not as much as full-process optimization. Say, from Kubernetes, to containers, to provisioning, to a compute function. Difficult for a mainstream semi supplier to manage that scope.
A Semiconductor Perspective from Marvell
Chris Koopmans, COO at Marvell, talked about how they are adapting to evolving systems company needs. Marvell is squarely focused on data infrastructure technology in datacenters and through wireless and wired networks. AI training and other nodes must be able to communicate reliably at high bandwidth and with low latency at terabytes per second across data center-size distances. Think of ChatGPT, which is rumored to need ~10K GPUs for training.
That level of connectivity requires super-efficient data infrastructure, yet cloud service providers (CSPs) need all the differentiation they can get and want to avoid one-size-fits-all solutions. Marvell partners with CSPs to architect what they call cloud-optimized silicon. This starts with a general-purpose component, serving a superset of needs, containing some of the right ingredients for a given CSP but over-built therefore insufficiently efficient as-is. A cloud-optimized solution is tailored from this platform to a CSP’s target workloads and applications, dropping what is not needed and optimizing for special purpose accelerators and interfaces as necessary. This approach allows Marvell to deliver customer-specific designs from a reference design using Marvell-differentiated infrastructure components.
An EDA Perspective from Cadence
Tom Beckley, senior VP and GM for the Cadence Custom IC & PCB group at Cadence, wrapped up with an EDA perspective on adapting to change. You might think that, with customers in systems and semiconductor design, EDA has it easy. However, to serve this range of needs a comprehensive “EDA” solution must span the spectrum—from IC design (digital, analog and RF) to 3D-IC and package design, to PCB design and then up to electro-mechanical design (Dassault Systèmes collaboration).
Add analytics and optimization to the mix, to ensure electromagnetic, thermal, signal and power integrity, allowing customers to model and optimize complete systems (not just chips) before the hardware is ready. While also recognizing their customers are working on tight schedules with now further constrained staffing. Together, that’s a tall order. More collaboration, more automation, and more AI-guided design will be essential.
With the solutions outlined here, Cadence seems to be on a good path. My takeaway, CadenceLIVE 2023 provided a good update on how Cadence is addressing industry needs (with a healthy dose of AI), plus novel insights into systems/semiconductor/design industry directions.